Inspiration
We wanted to reimagine how people prepare for high-stakes moments — job interviews, public speeches, and learning new concepts. Traditional practice tools give generic feedback after the fact. We asked: what if an AI coach could read your body language in real time and adapt its teaching style the way a great human mentor would?
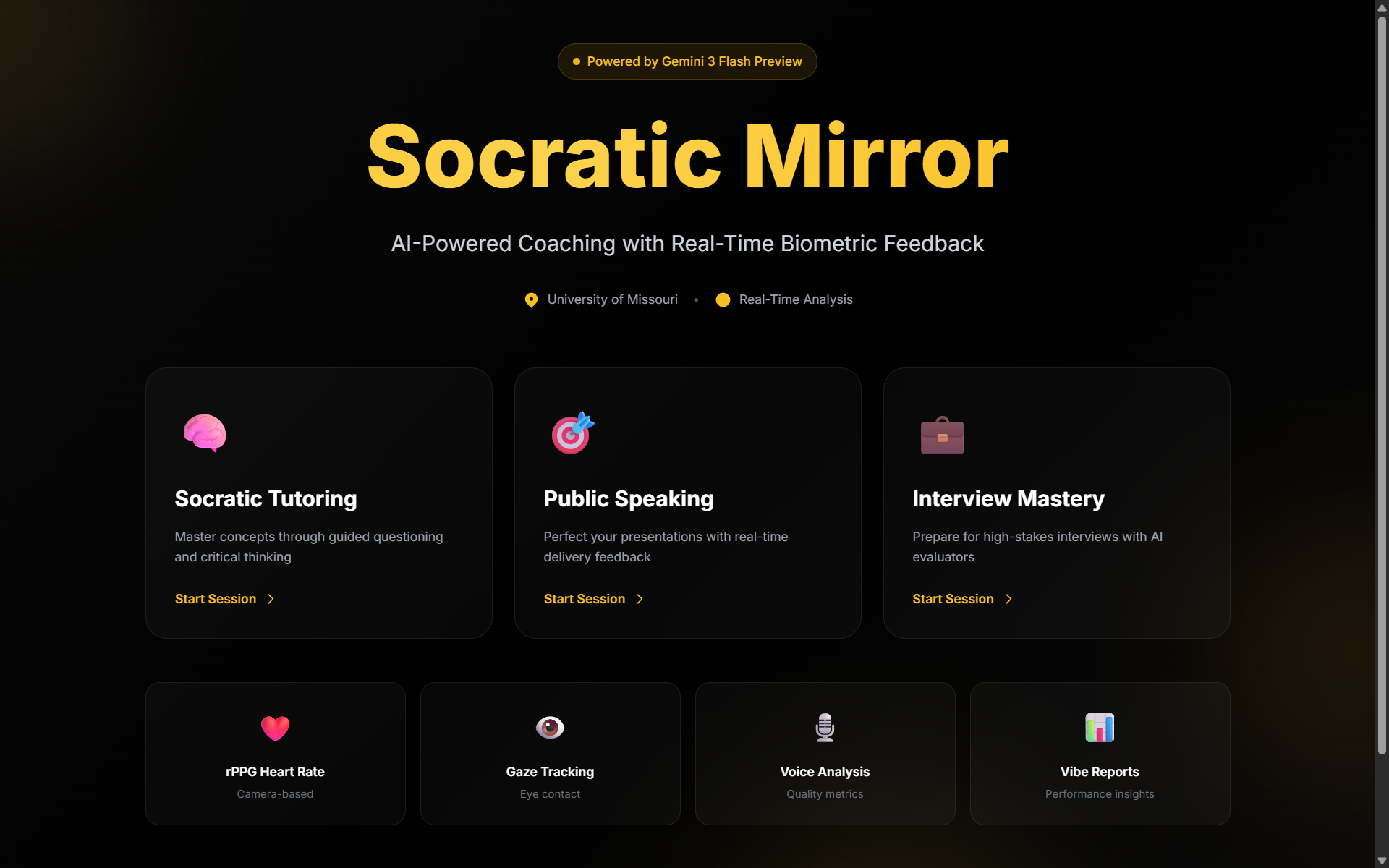
What it does
The Socratic Mirror Agent is a multimodal AI coaching system with three modes:
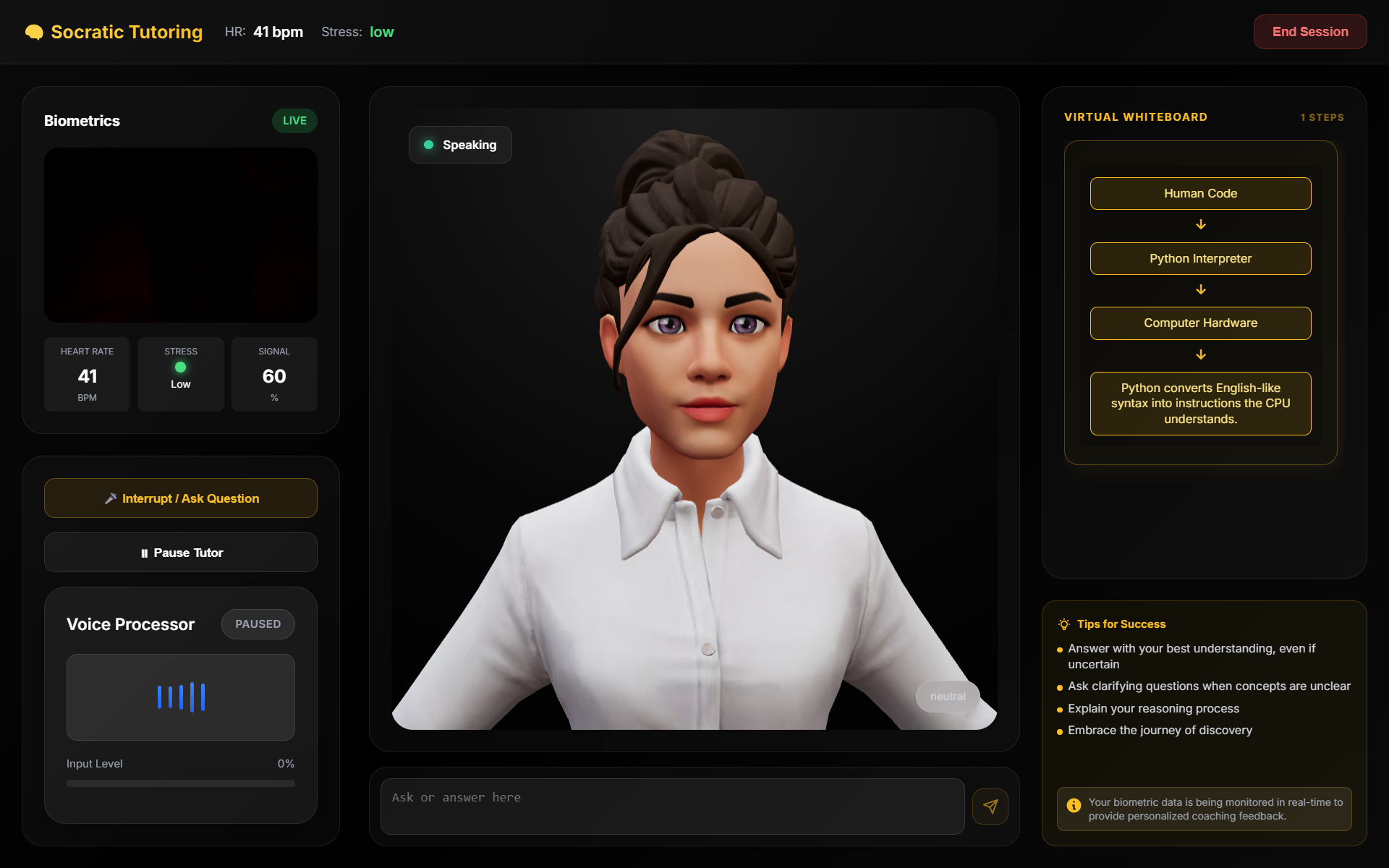
- Socratic Tutoring — Type any topic and the AI teaches through guided questioning, never giving direct answers. A live whiteboard renders equations, diagrams, step lists, and tables as the lesson progresses.
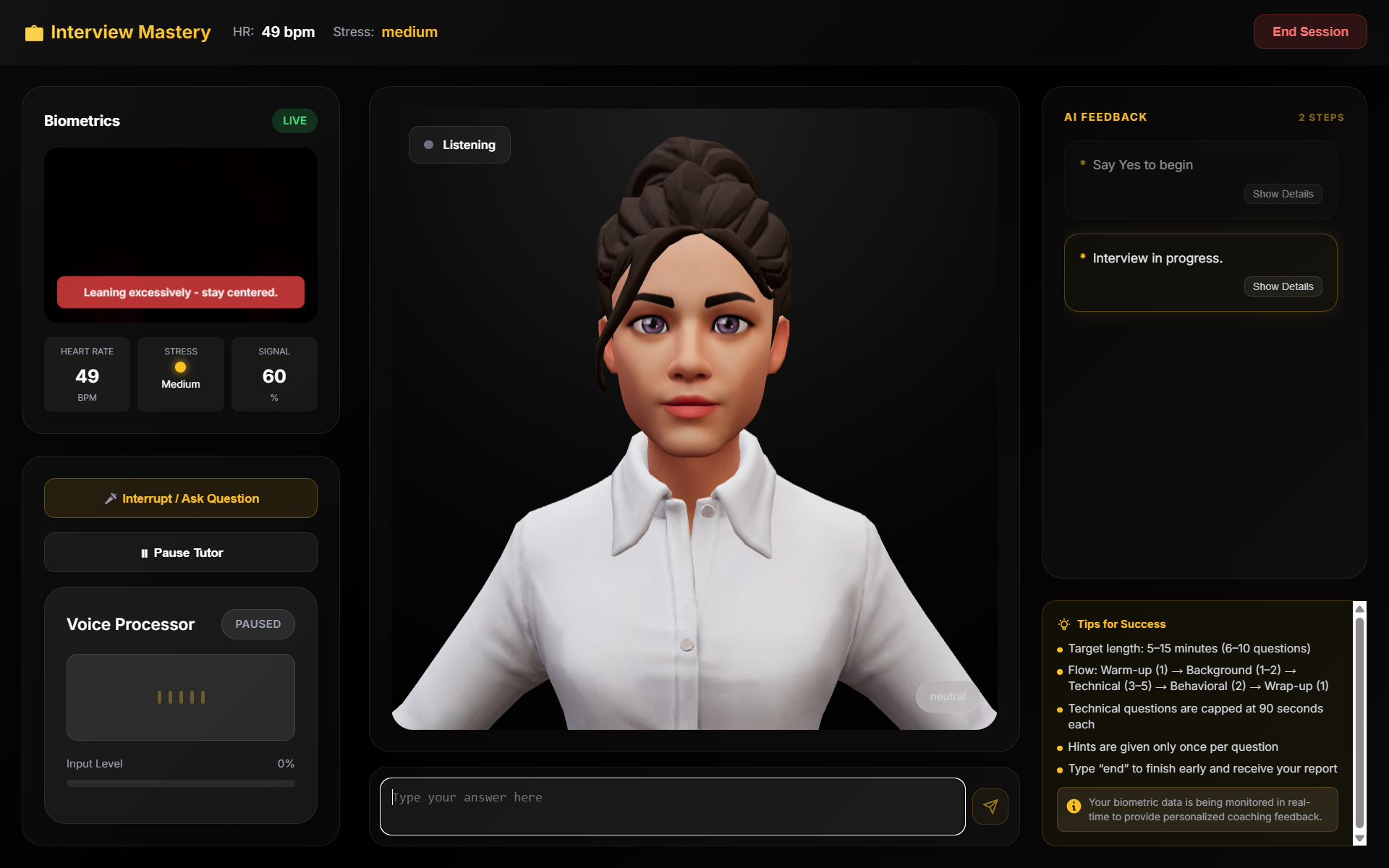
- Interview Preparation — Paste a job description and upload your resume. The AI conducts a structured mock interview cycling through background, technical, and behavioral questions with real-time evaluation.
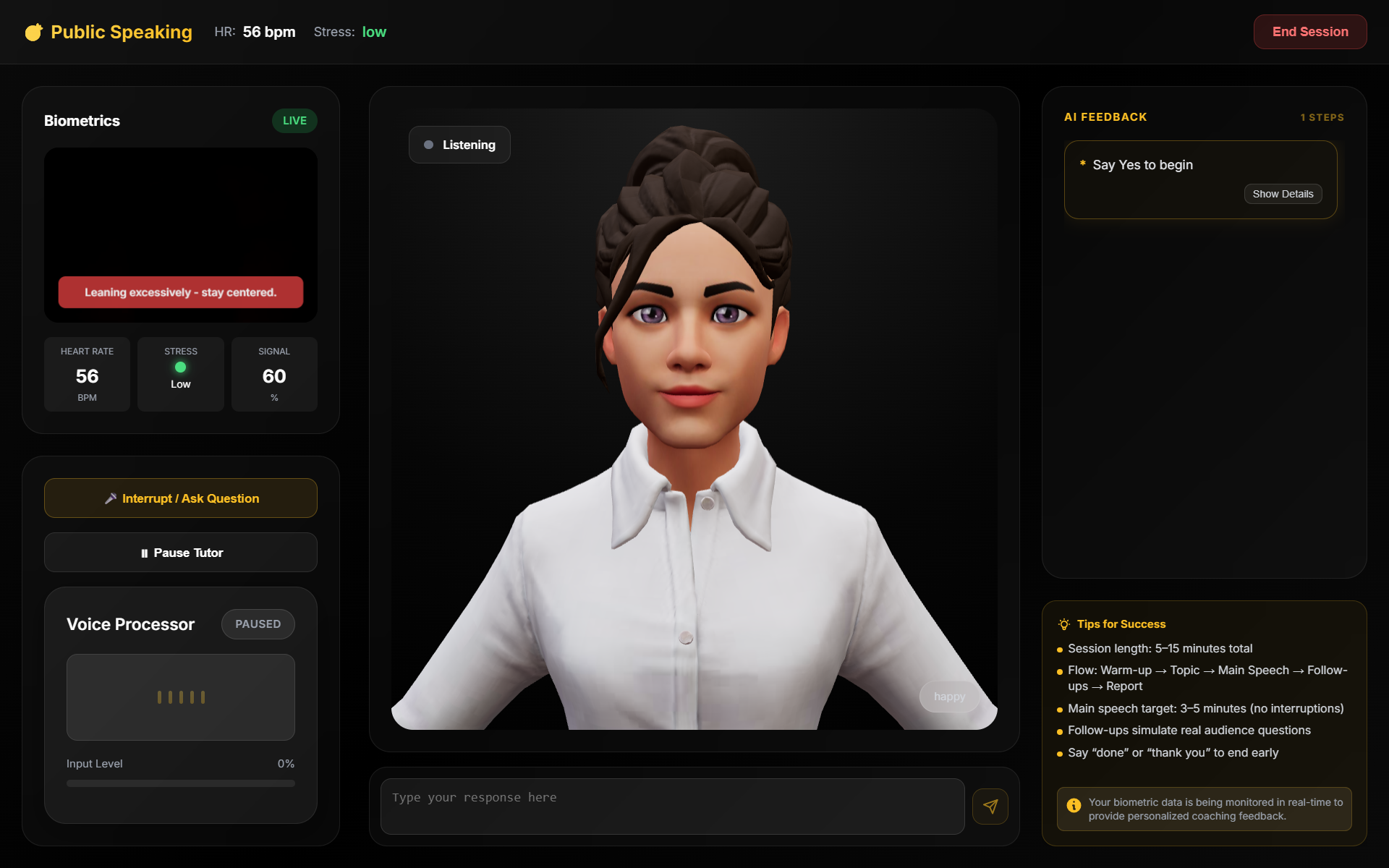
- Public Speaking — Choose a speech type, enter your topic, and practice delivering it. The AI tracks filler words, pauses, and pacing, then provides structured feedback.
Across all modes, a 3D avatar with procedural lip-sync, gestures, and facial expressions responds naturally. A webcam-based biometric monitor tracks heart rate and stress level. If the system detects excessive filler words, high stress, or gaze deviation, it triggers a barge-in — interrupting with corrective coaching feedback. After each session, a Vibe Report summarizes your performance with scores, strengths, and areas for improvement.
How we built it
- Frontend: Next.js 14 with TypeScript. The 3D avatar uses React Three Fiber with a Ready Player Me
.glbmodel, custom bone rigging for gestures (explaining, pointing, greeting, idle), and procedural lip-sync driven by speech energy. KaTeX renders math on the whiteboard. Voice input uses the Web Speech API; voice output uses browser SpeechSynthesis. - Backend: Python FastAPI server communicating over WebSocket for real-time bidirectional messaging. The coaching engine manages mode-specific state machines (interview question flow, tutoring step progression, public speaking stages).
- AI: Google Gemini API with automatic multi-model fallback (flash for real-time responses, pro for deep analysis). Structured JSON prompts ensure consistent output across tutoring steps, interview evaluations, and speech feedback.
Gemini Integration
The Socratic Mirror Agent uses the Google Gemini API as its core intelligence layer, powering all three coaching modes in real time.
Adaptive model routing. The backend dynamically discovers available Gemini models via the API and selects the optimal one based on task complexity. Real-time coaching responses (speech feedback, tutoring steps, interview questions) use Gemini Flash for sub-200ms latency, while post-session Vibe Report generation uses Gemini Pro for deeper analytical reasoning. A multi-model fallback chain ensures reliability — if one model is unavailable, the system automatically tries the next candidate.
Structured JSON generation. Every Gemini call returns structured JSON with mode-specific schemas. Tutoring responses include whiteboard visuals (equations, diagrams, step lists) and pedagogical state. Interview responses include answer evaluations and follow-up questions. Public speaking responses include delivery metrics and coaching feedback. A robust parser handles output inconsistencies by extracting JSON from fenced code blocks, brace-matched substrings, and raw text.
Mode-specific system prompts. Each coaching mode uses a tailored system prompt that controls the AI's persona, response format, and pedagogical strategy — Socratic questioning for tutoring, skeptical evaluation for interviews, and supportive feedback for public speaking. Conversation history is windowed to the last 12 messages to keep responses contextually focused.
- Biometrics: rPPG (remote photoplethysmography) algorithms extract heart rate from webcam video using green channel analysis and Butterworth bandpass filtering. Stress detection uses hysteresis with a 20% threshold and 5-second persistence.
- Testing: Property-based tests with fast-check validate signal processing invariants across 100+ random inputs.
Challenges we ran into
- Real-time coordination: Synchronizing voice recognition, TTS narration, avatar animation, biometric capture, and WebSocket messaging without race conditions required careful state management and a narration queue system.
- Barge-in timing: Detecting when to interrupt the user mid-speech without being annoying meant tuning multi-modal thresholds across filler word counts, stress levels, and gaze deviation.
- Gemini output consistency: Getting the AI to return well-structured JSON reliably across different models required robust parsing with multiple fallback strategies (fenced blocks, brace matching, raw text).
- Avatar expressiveness: Making the 3D avatar feel alive with only morph targets and bone transforms meant building a procedural animation system for breathing, gestures, expressions, and lip-sync from scratch.
What we learned
- Browser-native APIs (Web Speech, SpeechSynthesis, getUserMedia) are surprisingly capable for building multimodal applications without external services.
- Property-based testing with fast-check catches edge cases in signal processing that unit tests miss entirely.
- Gemini's multi-model ecosystem lets you optimize cost and latency by routing different tasks to different model tiers.
What's next
- Wire the real rPPG pipeline into the live biometric monitor (currently using simulated data for demo reliability).
- Add Gemini's native audio streaming for lower-latency voice interaction.
- Expand coaching modes with collaborative whiteboard editing and multi-user sessions.
Built With
- css
- fast-check
- fastapi
- google-gemini-api
- katex
- next.js
- python
- react-three-fiber
- ready-player-me
- tailwind
- three.js
- typescript
- web-speech-api
- websocket