-

About
-
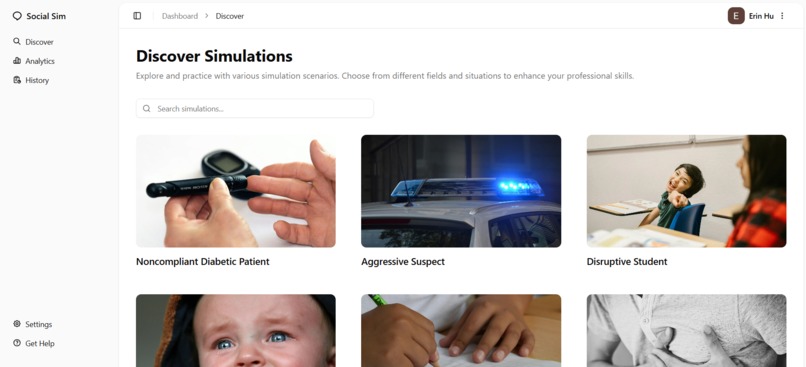
Explore Simulations Dashboard
-
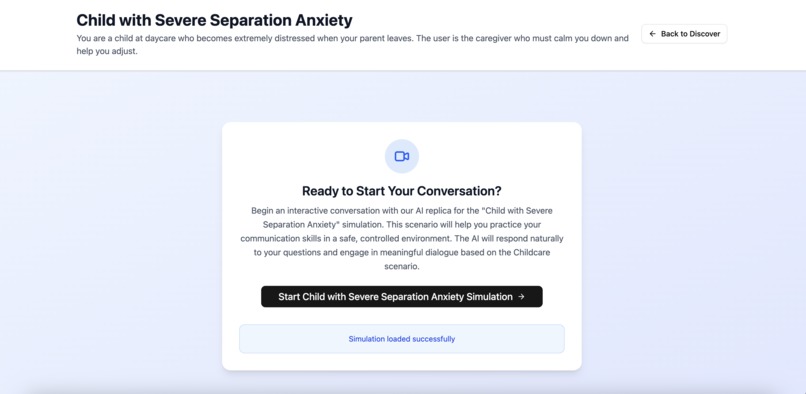
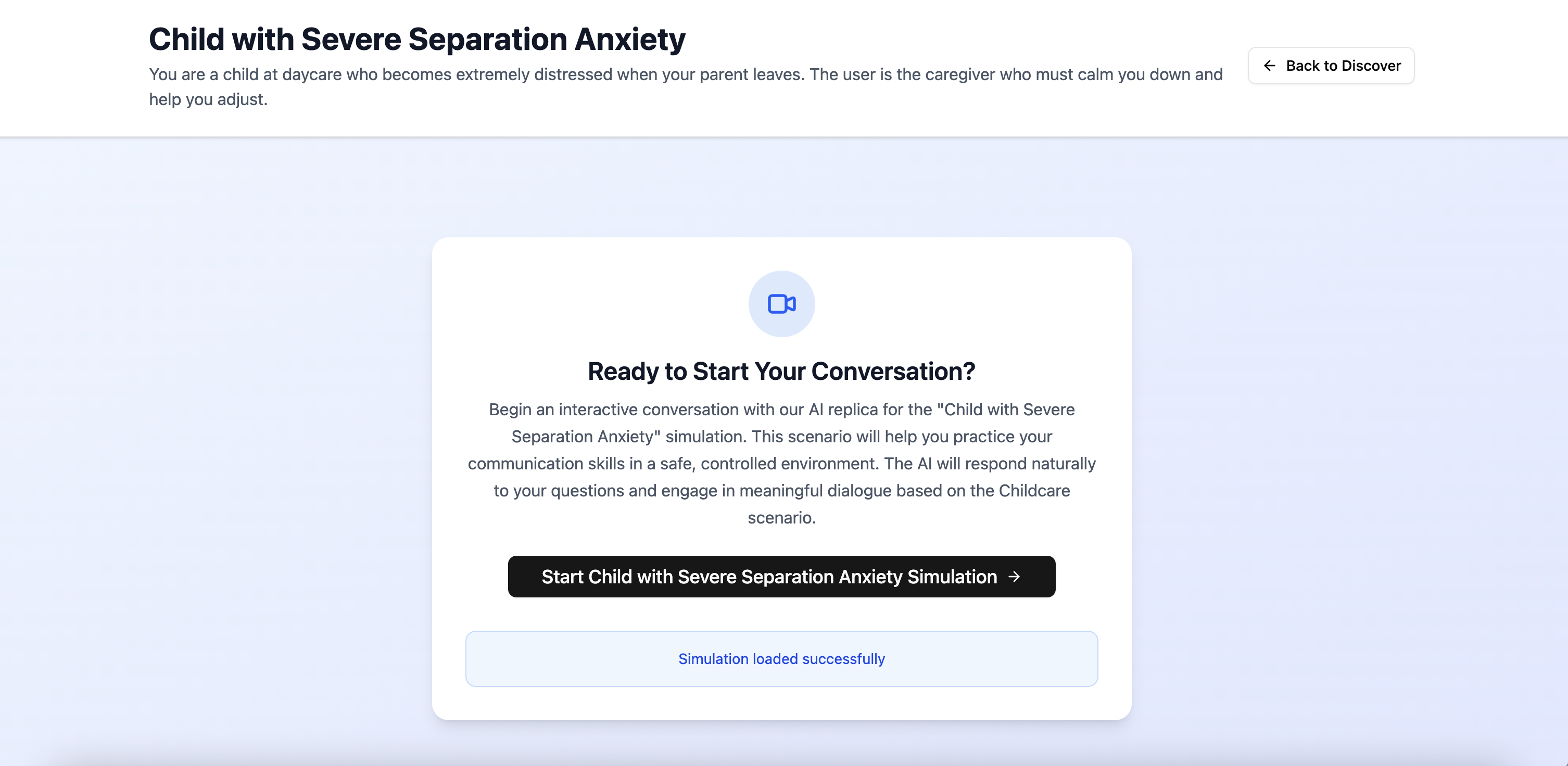
Start Simulation
-

Simulation Interface
-
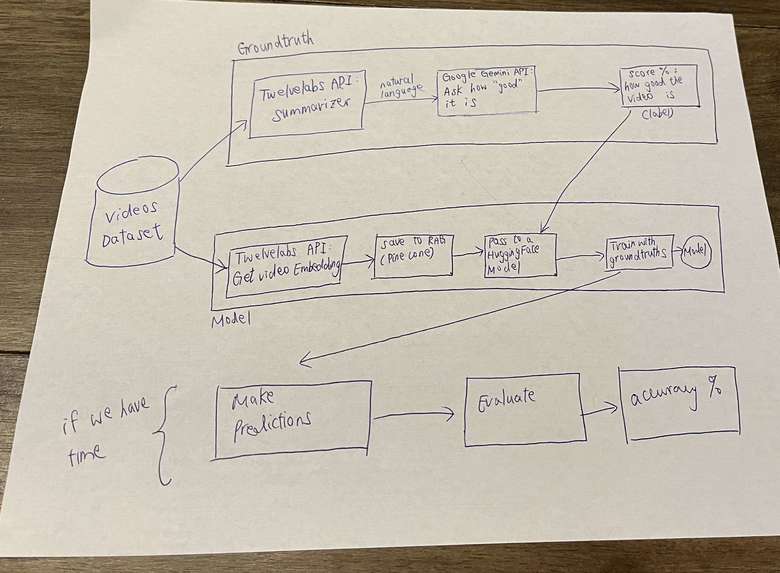
Training Algorithm
-
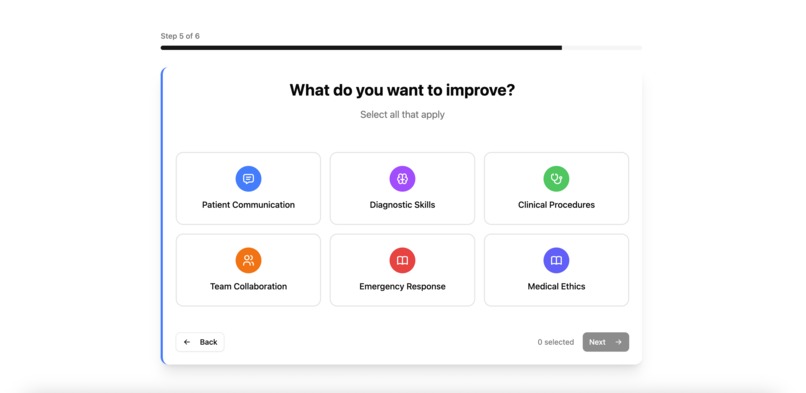
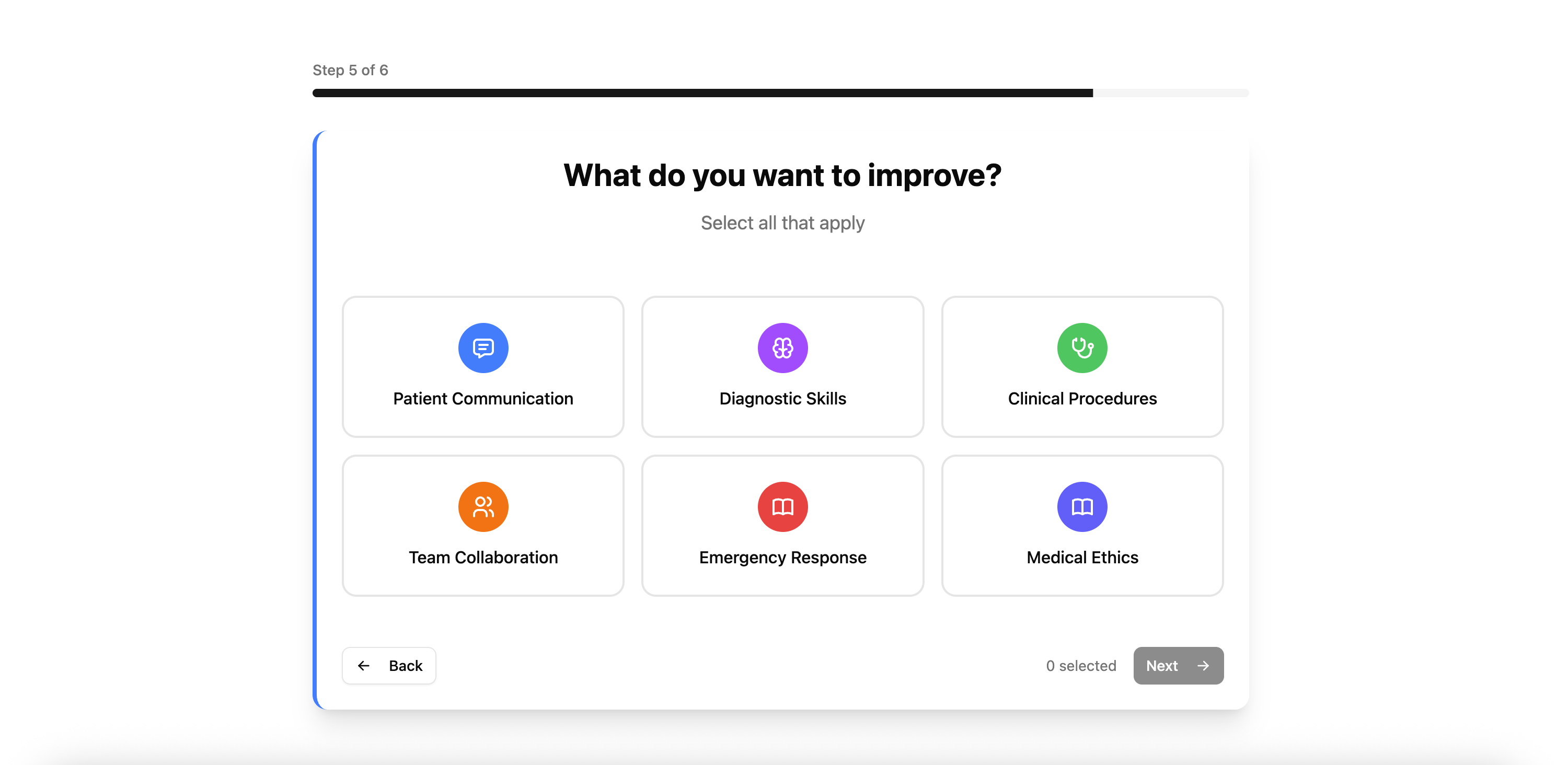
Onboarding System


Inspiration
The idea is for people working in fields like medical processionals (mainly), law enforcement, childcare, education and social workers to gain experience interacting with patients and colleagues (focus on the social aspect of the industry).
What it does
This is done by having an AI video chat interface (real time voice audio and a speaking avatar) where they can practice communicating and working in different situations in virtual simulations, they can choose what they want to do based on their field, and also customize the prompts for the simulations, then they will receive feedback/counselling/mentorship and a score evaluating how good the communication process goes.
How we built it
We prepared a login page which connects closely with a predefined authentication service from Supabase. At the landing page, there is a dashboard which allows the user to browser or edit the profile, including their learning progress, reports of feedback from simulated communicative processes like interviews, and allowing them to onboard seamlessly to the portal by entering their details, industry, and their career aspirations onto the database with a fully customized user's experience.
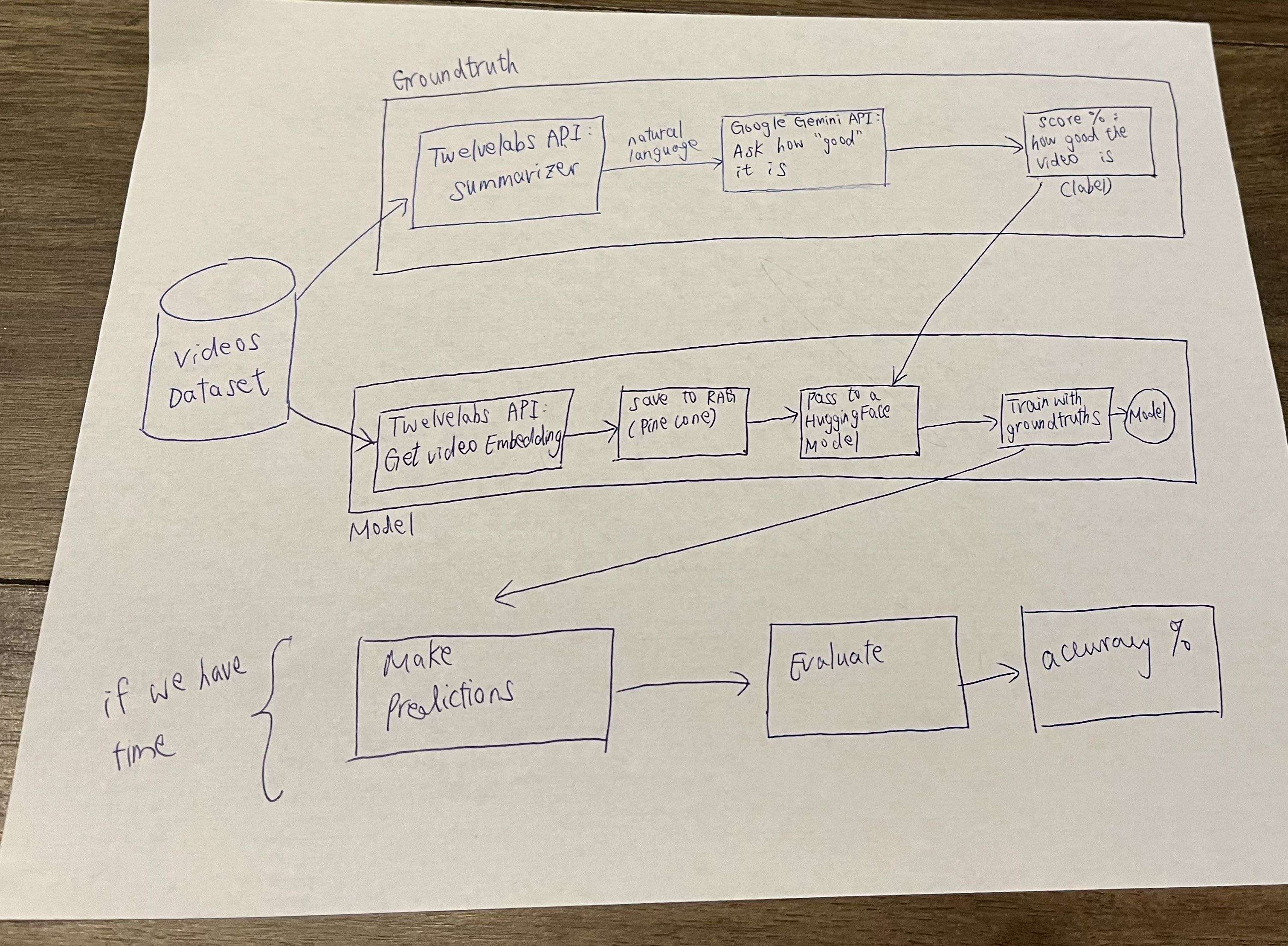
The core part of our app simulates an interview-like communication with an AI agent via a real-time API connection to an AI agent built by Tavus. After the legendary chat with the agent, the entire video will be saved and passed onto the evaluation component. That component provides a score from 0 to 100) indicating how good the interview goes. The saved video is firstly converted to a vector embedding from an embedding model from TwleveLabs. A prediction is then made from a Random Forest regressor of scikit-learn.
The model is trained with an enriched video dataset called "AnnoMI". It consists of 122 unique URLs which points to the video on YouTube or Vimeo respectively. With those data, it is firstly prompted to a summarizing model from TwelveLabs to produce a summary in natural language. With the textual summary of each video, they are passed into various free Google Gemini models in an iteration and the best (non-hallucinated) response is obtained. We actually prompted Gemini to produce an evaluation score as a source of ground truths. While at the same time we converted those videos to vector embeddings, we backed up the raw videos onto a public folder on Google Drive, as well as vector embeddings onto a Retrieval Augmented Generation (RAG) Database - Pinecone. Finally, we fitted those samples with respect to their ground truth labels into a Random Forest regressor.
Challenges we ran into
TwleveLabs is unavoidably a handy tool for video summary and semantic searching based on vector embeddings, but the setup and messy documentations of their API services caused huge troubles. The core challenge is the inability to read videos directly from YouTube. Therefore, we had no choice but to save them to either a public cloud storage bucket or Google Drive. All videos have occupied more than 2GB in storage. Since neither cloud platforms could provide adequate storage space under their free tiers, we eventually chose to use Google Drive. We sailed through troubles connecting to the drive programmatically essentially by setting up an IAM user's profile on the Google Cloud's console. This has also become a blocker to backing up the embeddings to our RAG database. Since we could not get a complete dataset for training, we ended up with a fallback strategy: by firstly training the model with 6 successfully obtained training samples, and by using a randomized score to mock the prediction outcome in case of hallucinated or overfitted results.
Moreover, debugging the integration with the frontend has become much of a hassle. We implemented the backend services in Python using FastAPI while we implemented the frontend interface using Next in TypeScript. Given different languages and frameworks, not to mention the reliance of a third party's authentication service, instant communications and fallback approaches needed to reflect the challenges as quickly as possible.
Accomplishments that we're proud of
The frontend interface looks attractive and integrates pretty well with the backend API services.
What we learned
From our struggles during integrations to third-party services, we learned efficient debugging techniques. In most cases, especially using black-boxed components like an AI model, it is computationally inefficient to run the entire pipeline or workflow in order to check the issue. Technically, we also realized workarounds to access Google Drive in a productive programmatic manner.
What's next for SocialSim
It always worths an effort to seamlessly complete the entire dataset and the training pipeline. On the UI, a thorough testing strategy is preferrable in the future, especially about the integration across different services.
Built With
- fastapi
- google-gemini
- next
- pinecone
- python
- rag-vector-database
- random-forest
- scikit-learn
- supabase
- tavus
- twelvelabs
- typescript
- uvicorn


Log in or sign up for Devpost to join the conversation.