-
-

Homepage on desktop
-

Loading animation (prettier on video) on desktop
-
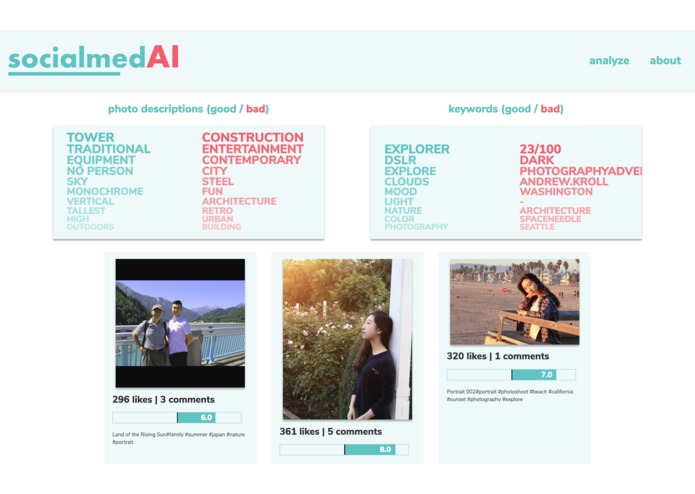
Viewing photos and general analytics on desktop
-

Viewing additional ratings on desktop
-

Analyzing a photo on desktop
-

About page on desktop
-

Homepage on mobile
-

About page on mobile
-

General analytics on mobile
-

Viewing photos on mobile










Inspiration
As regular users of Instagram, we always noticed interesting correlations between likes and photo content. Some users seemed to be interested in specific types of photos, such as space and constellations, while less interested in standard landscape photos. As we discussed this phenomenon as a team, we realized that companies are likely running into the same issue and cannot predict what they should post for maximum engagement. What if there was a way to correlate how much users engage in a photo with what’s physically in it and what keywords are used? What if we could encourage businesses, photographers, and everyone else on Instagram to post content that doesn’t just entertain, but engage.
What it does
SocialmedAI allows the user to enter the username of any public Instagram account. From there, the program sends that data to a database with Python Flask. After that, we send the data back into the front end, completing a get request through jQuery, and display a score of how each photo performed. We include an analysis of what aspects of it contributed to the success or failure by listing the most influential factors. These factors are separated into image content using Clarifai’s API and text content after analyzing successful hashtags and captions. Additionally, we can relate hashtags to real-time twitter sentiment to predict performance even further. If a photo is successful, the most positive influencers are listed, while if it is a poor performing photo, the most negative influencers are listed. And, as the UI is responsive, it works on all screen sizes and allows for anyone to access the app in any location, regardless of using a phone, tablet, or laptop.
How I built it
First, to build a proper machine-learning computational model, we acquire training dataset from analytics of sentence sentimental polarity regarding Movie Reviews from Rotten Tomatoes. This dataset was first published in application of Bo Pang and Lillian Lee, “Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales.”, Proceedings of the ACL, 2005. We selected this dataset out of all available datasets in the public storage mainly because the similarity in nature of Rotten Tomatoes to Instagram/Twitter, all being social discussion forums. This dataset consists of 5331 positive and 5331 negative processed, labeled, sentences with half positive and half negative. Notice with the limited amount of training data, we can potentially overfit the model in the training stage with overestimated accuracy.
Due to the current uncertainty of dimensionality in the realm of linguistics, we were unsure of the optimal algorithmic approach to perform the classification on natural language processing input tokens. To reduce the complexity of the input data, we tokenize complex sentence structure into list of individual words to inspect independent sentimental polarity. Due to the uncertainty in best choice of classifier, we established an aggregated voting system of seven classifier, three Naive Bayes classifiers (Original, Multinomial, Bernoulli) and four other non-Bayesian approach classifiers (Logistic Regression, Stochastic Gradient Descent, Linear Support Vector Classification, Nu-Support Vector Classification). Since the output label is binary, +1 for positive sentiment and -1 for negative sentiment, we aggregated outputs from all seven classifiers by summing up the outputs and taking the sign of that value for conclusive label. Combined, seven classifiers showed a mean accuracy of 74.833%.
To perform analysis on each profile based on previous posts, we first compute the average number of likes on a profile out of all of the posts to establish a threshold of satisfiable performance. The influence of each keyword on the profile is represented by the cumulative difference with the mean number of likes, positive value representing positive influence toward the performance of the account, and vice versa. Subsequently, we applied the well-trained machine learning model to determine whether the sentimental polarity of text and image in each post of the profile are misaligned, which will be denoted once the number of likes fall under the average.The success score of each post is computed by p-value with the specific z-score under normal distribution, rescaled in the range of [-10, 10]. In addition, the key words and attributes imposing significant influence on the post are identified in comprehensive analysis.
Challenges I ran into
For the front end, there were difficulties in communicating what we expected from the back end, however through writing everything down and clarifying exactly what JSON we would use to communicate, we were able to overcome the challenge. Additionally, mobile development was very difficult at many points and required thorough testing in mobile devices connected to a local Python HTTP server.
Accomplishments that I'm proud of
We’re proud of both the subtle animations, grand design, and usefulness of the app. Additionally, our team ran very well, as we had a dedicated member for front end web development, back end web development, and data science, allowing us to create a strong result using each of our respective strengths and diverse perspectives.
What I learned
For front-end, we practiced parsing complicated JSON objects, working with Chart.js, researching an Instagram scraper, and further practicing general Bootstrap skills when writing CSS. Additionally, it was fascinating how just one word contributed so much to the rest of posts.
What's next for SocialmedAI
SocialmedAI could be advertised towards businesses, students, and other customer segments to receive a higher user base after a marketing campaign. Additionally, SocialmedAI can expand into analytics on other platforms, such as analyzing Twitter posts, Facebook posts, and more. There were initial plans to track recent sentiment on Twitter for different hashtags, however we ran out of time to implement this idea, though we had real-time graphs being generated with chart.js and a Twitter sentiment analyzing program set up and trained. We briefly brainstormed a feature for uploading an image then, based on past posts, generating a caption for it that will increase maximum engagement, allowing corporations to upload many photos at once, have our service automatic caption generation, and letting them post it later.



Log in or sign up for Devpost to join the conversation.