-
-

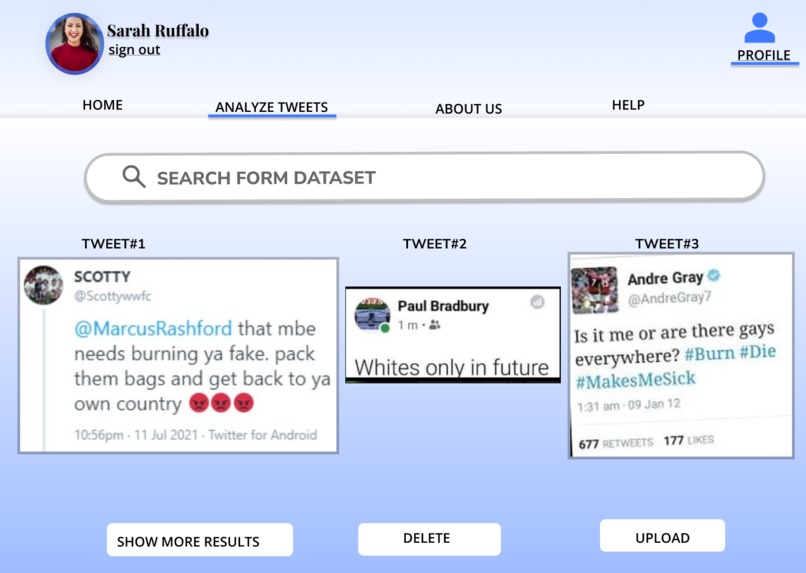
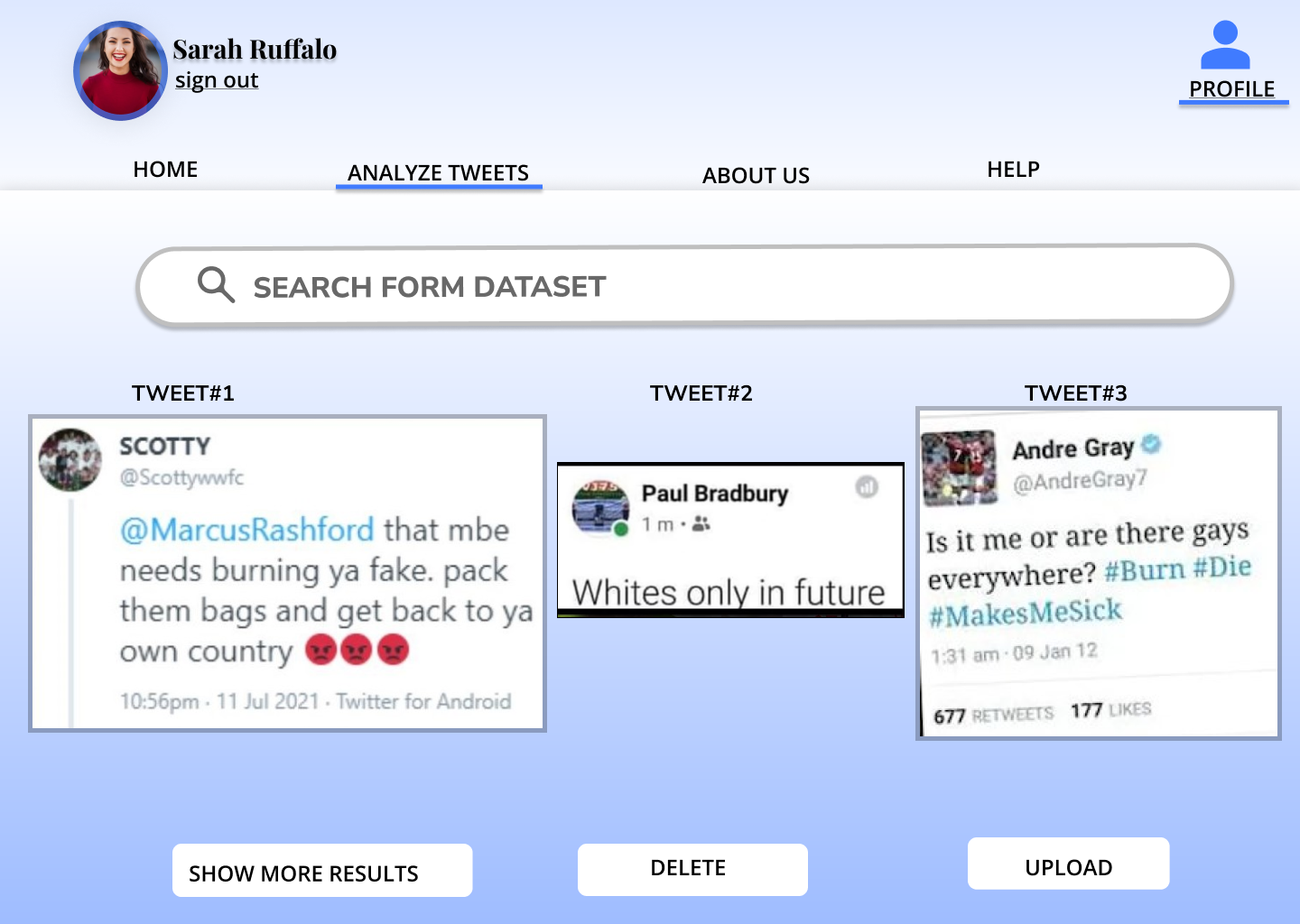
GUI
-

Models comparisons based on performances on validation set
-

Tree classifier model output
-

GUI
-
home




How we built it
First, Mason trained a set of a binary classifier models on a general racism speech dataset and selected the one with the best performance on the validation dataset. He plotted out the first three layers of the tree. Mason also derived a list of potentially racist words from the general dataset that has the highest information gain with respect to being potentially racist. Those words in the tree nodes and the list of highest information gain will come in handy when we plug them in the tweet scraper. The tweet scraper Mason made would allow us to search for parallel keywords including soccer players names and potentially racist keywords previously derived. This guarantees us to have racist speech on twitter that are targeted against the top racially abused soccer players.
Challenges we ran into
One challenge we ran is low validation recall. The dataset response is fairly skewed, so there are that many racism speech in the first place, we didn't want to flip the label, so prediction recall will hence be sacrificed. Other challenges include plotting out the model. The Matplotlib library has super delicate nuances that needs to be adjusted according to your features of graphs. I spent a long time figuring out the API for plot_tree(), including what each argument means.
Due to time constraints the details of the project is available via GitHub through the link


Log in or sign up for Devpost to join the conversation.