-
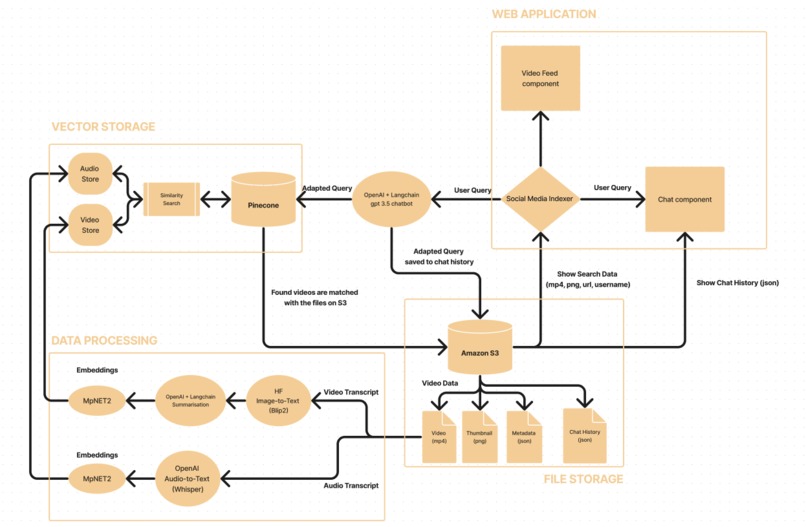
Workflow Diagram
Inspiration
Our inspiration arose from the desire to investigate how well could an LLM-based approach paired with Pinecone's abilities to better extract information from the massive quantity of content generated on social media. It is also a need each and every one of us in the team has - finding information in long tutorials/podcasts/ebooks or through sifting hundreds of short TikTok video's to gather marketing trends insights.
Our approach
The solution we bring forward looks primarily at embedding both visual and auditory content from videos of short and long duration from the all-known social media platforms. Our solution can be regarded as a multi-modal approach towards summarising digital content, with the usage of multiple models in the integration pipeline from data extraction all the way to user interaction.
Data extraction
The first step we undertook was to prepare a pipeline for scraping the data necessary for the undertaking of this project from 3 platforms: TikTok, YouTube and Instagram. Furthermore, after procuring the necessary data (videos, mp3, metadata) we applied the extraction pipelines, which contextualise all the sensory perceptions of a video (auditory + visual):
** Speech-To-Text (STT)** performed using OpenAI's Whisper API;
** Image-To-Text (ITT)** performed using Saleforce's Blip2 model, used on Hugging Face Inference.
The extraction methods looked at two separate components of the video, which have been extracted through separate pipelines. For the STT implementation we extracted both the full audio text transcription as a whole, but also segmented parts split separately by their timestamp. The second method of data extraction was also chosen in order to offer granularity to the similarity search results. Ultimately, for the ITT pipeline, we used the Blip2 image captioning model offered by Salesforce and we ran their 2.4 billion parameter model on the the T4 instance of AWS offered through the Inference Endpoint. In order to obtain a contextual description of the visual component of the video, we sampled the video with a frequency of 5 seconds, while for each capture generating a description. This gave us a list of descriptions for multiple points of the video, which with the help of the GPT3.5-turbo model together with the LangChain summarisation agents allowed us to create a full description over the video.
Data processing
In order to store the data in Pinecone, two different methods were investigated in the embedding process. The first used method employed using the MpNET tokeniser, which is a model derived from sBERT, and could be easily used on local machines. Investigations have shown that the OpenAI's tokeniser works better and can garner a wider context understanding.
Data storage
The piece-de-resistance for our system is of course, Pinecone for storing all the embedding vectors of both the visual and audio textualization of about 700 videos. Moreover we used Amazon S3 for storing all the adjacent files necessary for the core processes.
User interaction
The workflow behind the application is that the user logs-in the main page and is prompted with a chatbot that guides the journey of finding the desired content. The user queries are adapted using GPT3.5 and conversational agent chains from Langchain to allow a smooth user conversation with the chatbot, while maximising the usefulness of the similarity search queries.
How we built it
We used two main stacks throughout the development: Python and JaveScript. The former was used in the data extraction, processing and storing to databases tasks, whereas JavaScript was employed for the web application development and database querying. The workflow of our system is that the data is hosted and accessed on-demand, as we have found this to be the more efficient solution given the chaining of multiple AI models to achieve the final result.
Challenges we ran into
• Time management (2 full-time employees + 2 students) • Prioritising the essentials • Complicated data extraction (scraping is volatile as the front ends change often) and time-consuming processing tasks • Website development and integration with data pipeline
Accomplishments that we're proud of
• Having finished the data extraction pipeline and successfully uploaded the data to Pinecone and Amazon S3 • The minor success at custom chain prompting for a dual chat suggestions-semantic search query generation large language model application • The team's first use at using multi-modal AI integration and product development
What we learned
• Team communication is essential! • Understanding everybody’s strength • Individual improvement in coding and using the AI stack • Team management • The use of the new innovative technology
What's next for SocialScanner
• To make the main functionality fully functional • Improving UI and UX • Enlarging the video database • Make current data pipeline more efficient • Further test current techniques to find room for improvement • Develop better and more reliable methods for visual and auditory extraction • Investigate the business feasibility of offering users on-demand video audio-visual transcriptions
Built With
- amazon-web-services
- amplify
- bootstrap
- css
- huggingface
- huggingfaceinference
- javascript
- langchain
- node.js
- openai
- pinecone
- python
- react
- s3
- tailwind


Log in or sign up for Devpost to join the conversation.