-
-
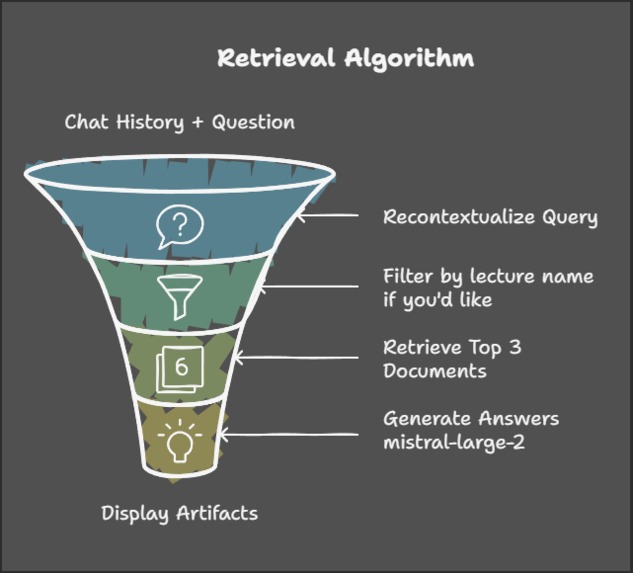
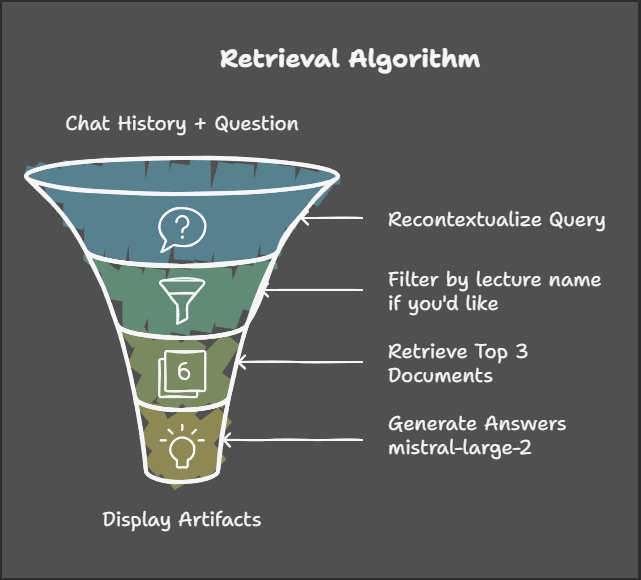
retrieval pipeline
-
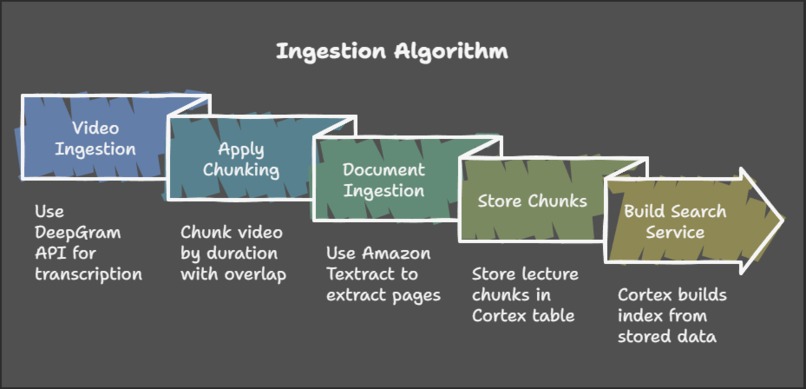
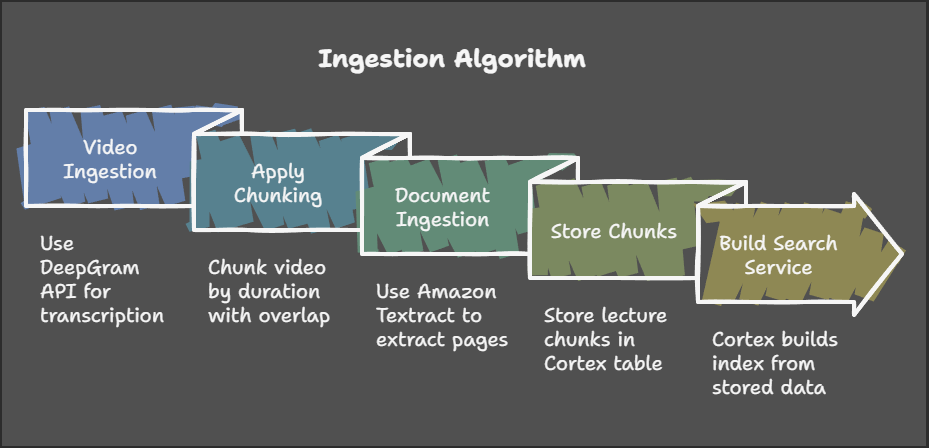
ingestion pipeline
Inspiration
The inspiration for "SnowTrail" came from observing students' desire for a more immersive e-learning experience. Often, students struggle with short attention spans and finding precise information in long lectures. "SnowTrail" addresses this by providing an interactive platform that navigates students to key moments in lectures, ensuring they receive accurate answers quickly and efficiently.
Technology Behind
Ingestion Process
Video Transcription with Deepgram:
- Why Deepgram? For video ingestion, transcription is crucial. Deepgram’s API is leveraged to extract sentence-level timestamps, allowing precise mapping of spoken content to video durations.
- Chunking Videos: Using sentence-level timestamps, videos are segmented into chunks of specific durations. A sliding window approach with overlapping chunks is applied to maintain context continuity between segments.
Document Processing with Amazon Textract:
- From Cortex to Textract: Initially, Cortex’s parse document function was considered. However, its lack of page-level extraction led to a switch to Amazon Textract, which supports fine-grained processing.
- Storing Processed Chunks: Once processed, lecture chunks are stored in a Cortex table, which forms the backbone of the search service, enabling efficient indexing and retrieval.
Retrieval Process
Query Processing:
- Queries are derived from the user’s chat history and rephrased to resolve ambiguous references.
- Users can apply filters, such as lecture name, triggering metadata filtering to narrow down search results.
Cortex’s Hybrid Search:
- Cortex combines metadata filtering with semantic search to identify the most relevant lectures.
- The system retrieves the top three documents, complete with their associated content.
AI Response Generation:
- The Mistral-Large-2 model generates AI-driven responses using the retrieved documents.
- Users are provided with response context, including page numbers and timestamps, for quick access to source materials.
Trulens Evaluation
During development, Trulens was instrumental in evaluating and refining the retrieval system. Two key areas were assessed:
Metadata Filtering vs. Global Search:
- Local search (using metadata) and global search were compared for lecture content localization.
- Results: Cortex’s search algorithm proved robust, delivering comparable relevance in both approaches. Metadata filtering, however, provided faster results by narrowing the search scope.
Chunk Duration Optimization:
- Three chunk durations were tested: 30 seconds, 1 minute, and 2 minutes, each with a slight overlap to preserve context.
- Findings:
- Larger chunks increased latency due to higher token consumption.
- 60-second chunks struck the optimal balance, achieving 90% answer relevance while maintaining efficiency.
Next Steps
- integration with image captioning to understand whiteboard stills from lecture videos
- general summary of the lecture by breaking it down into meaningful shorts
- generate flashcards from lecture content to quiz students what they learn
- store lecture files in AWS S3 buckets for better file management.
Built With
- cortex
- mistral
- python
- snowflake
- trulens











Log in or sign up for Devpost to join the conversation.