-
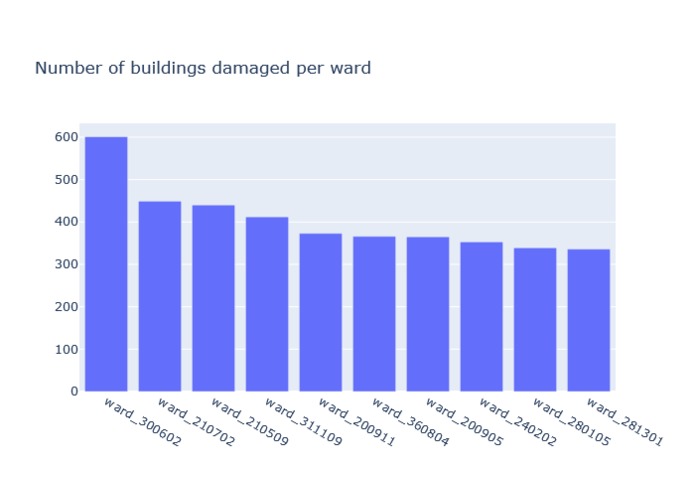
-
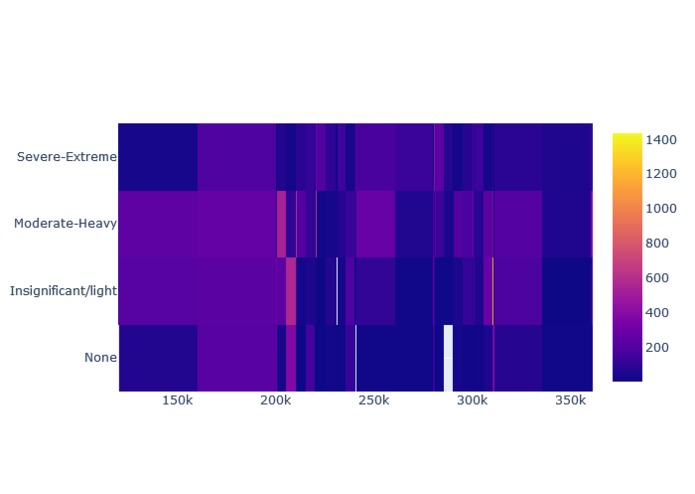
-
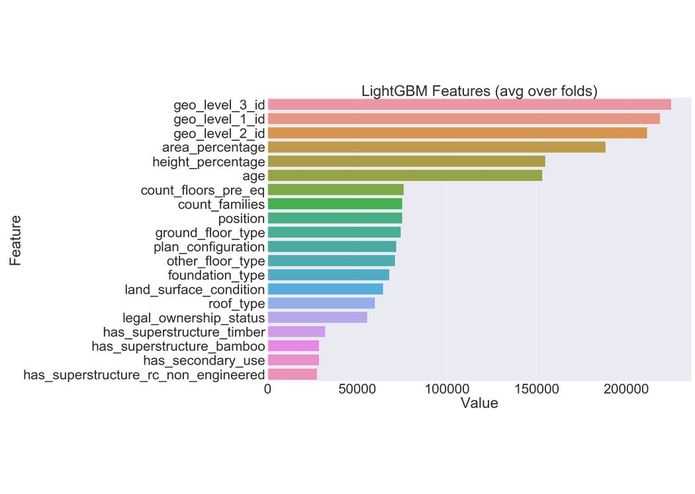
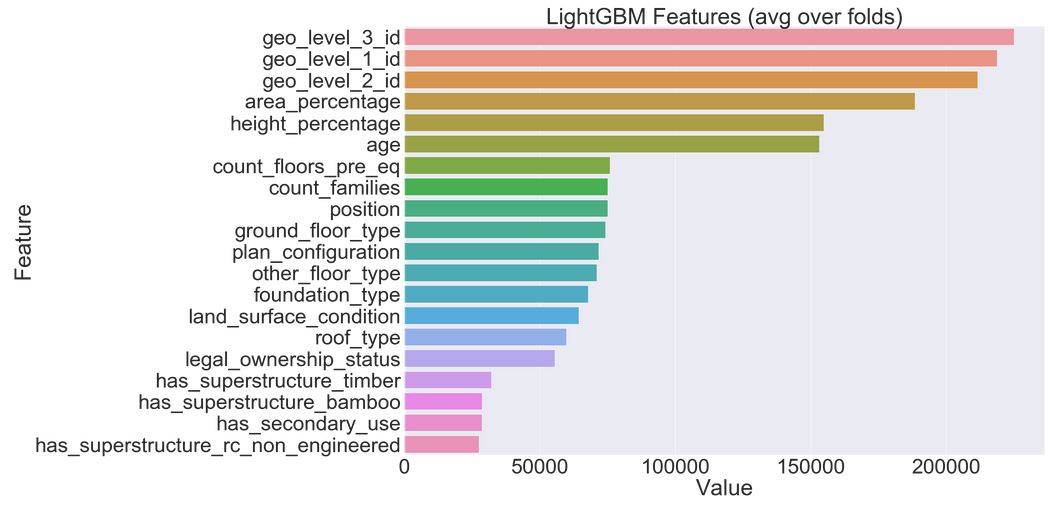
Feature Importance
-
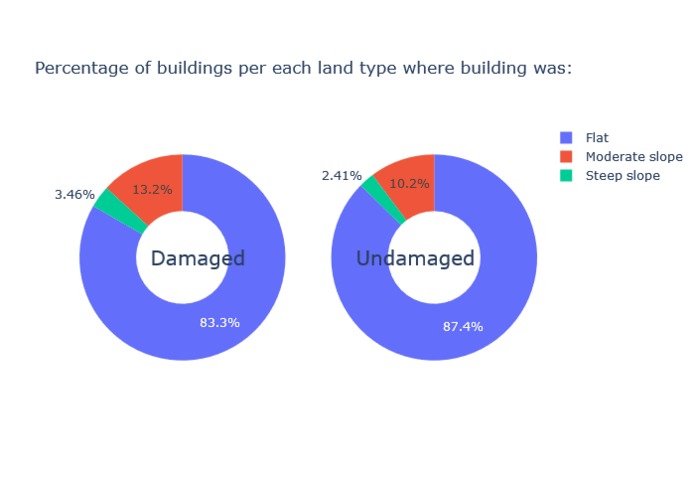
-
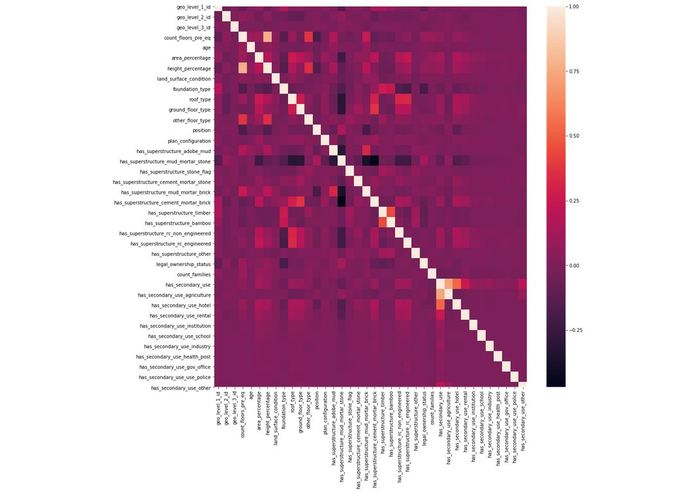
Feature Correlation
-
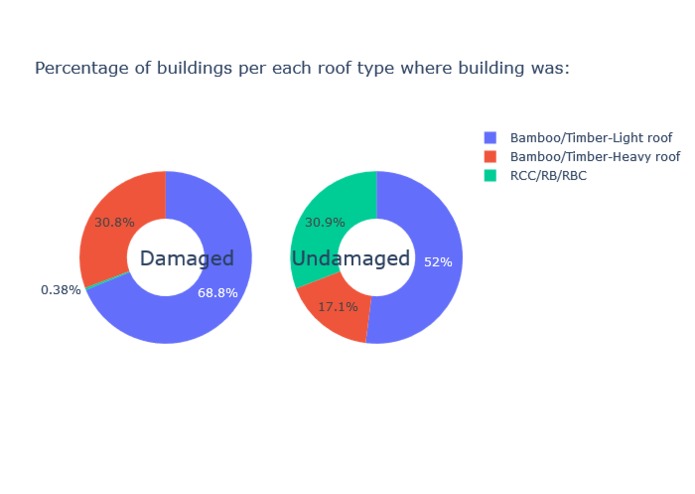
-
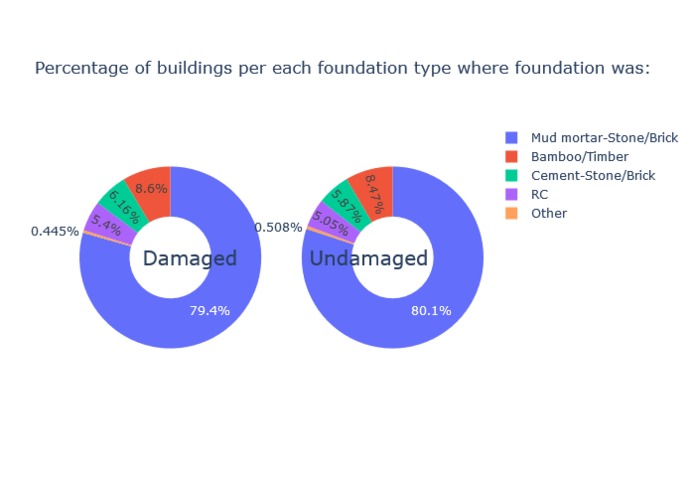
-
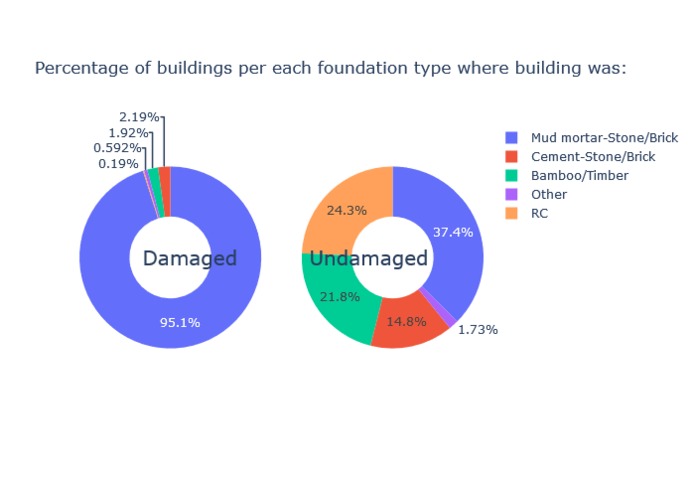
-
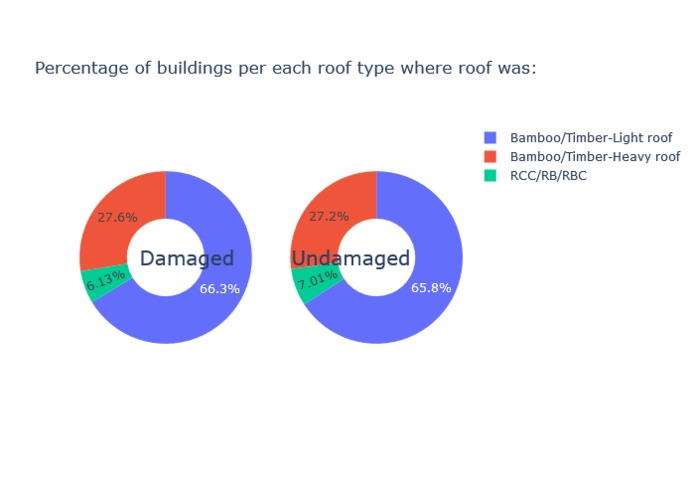
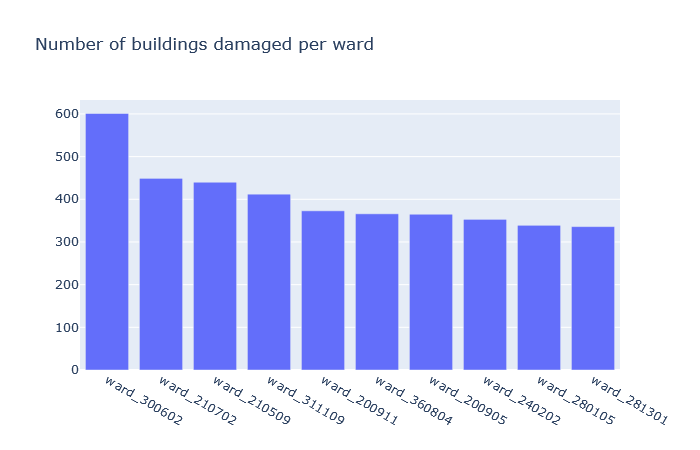
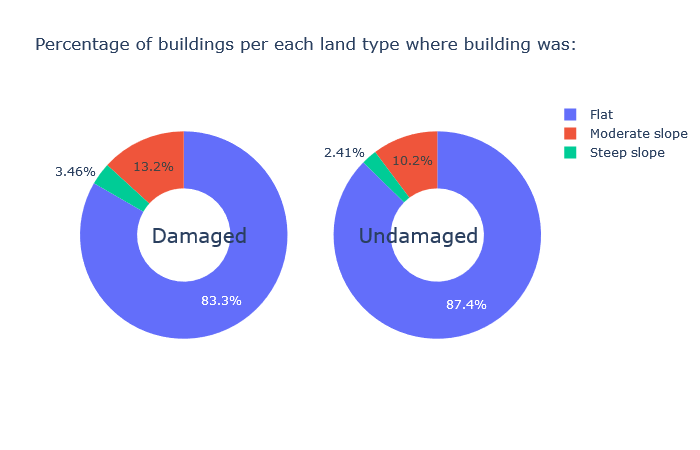
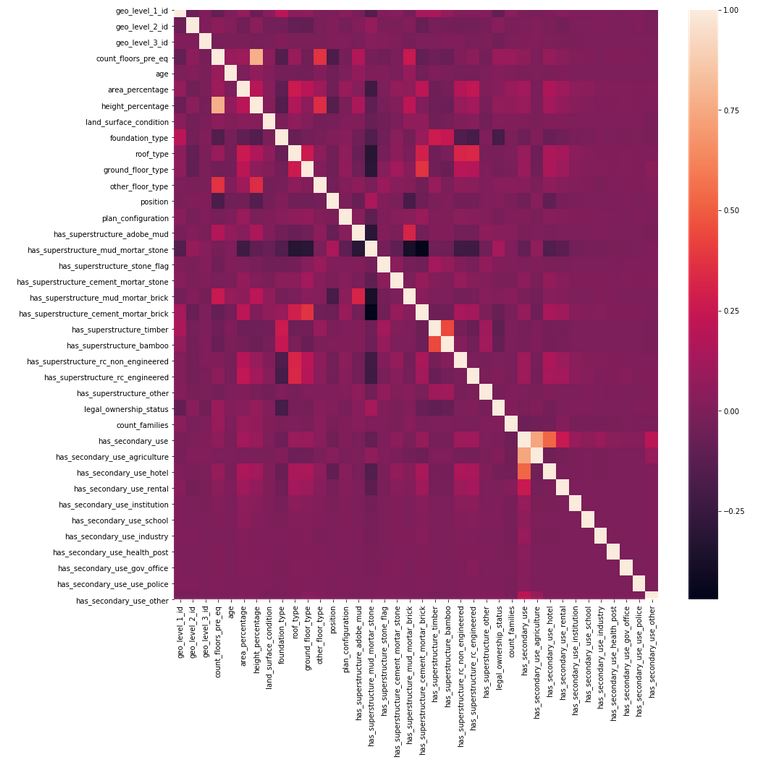
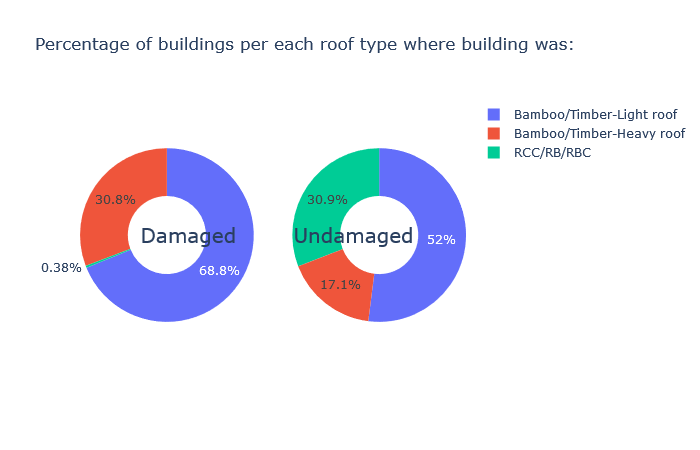
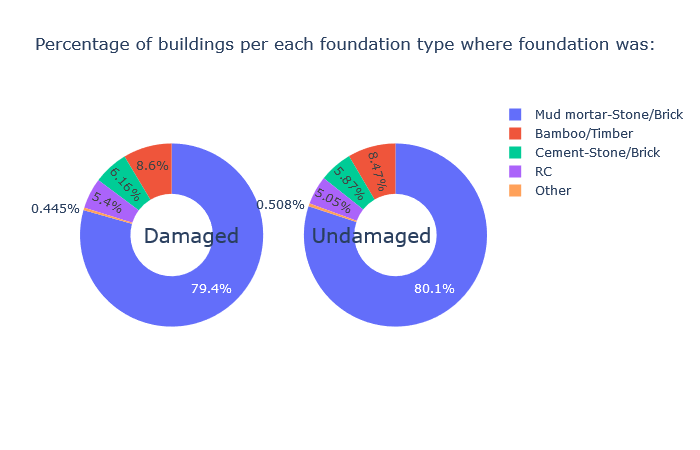
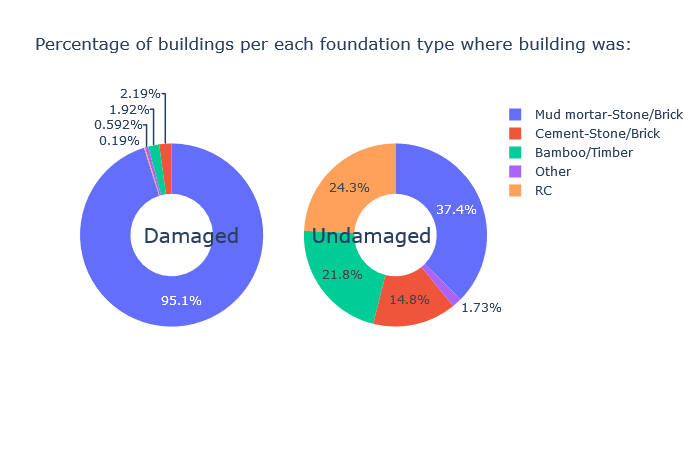
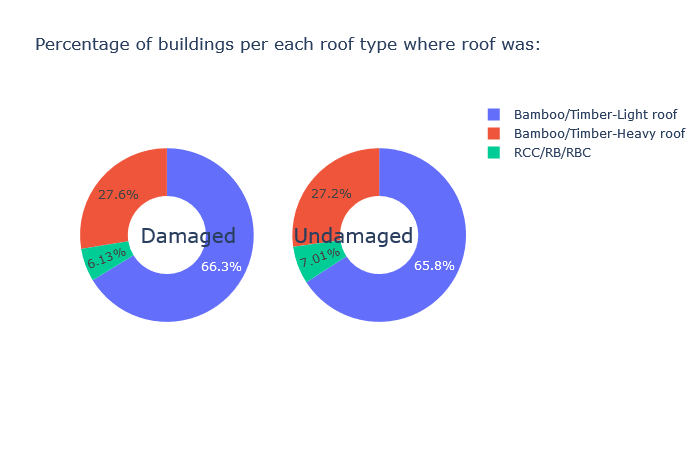
Inspiration
The aftermath of earthquakes, especially in underdeveloped and developing nations is a trauma the nations struggle with. The 2015 Nepal Earthquake was a massive one with even historic sites getting damaged and ending up in ruins. We want to help such nations in handling and predicting damage during earthquakes. We propose a smarter way of recuperating from such natural calamities and be prepared for such future incidents.
What it does
We have done exploratory data analysis on data set which is a result of a huge survey post a very deadly earthquake in Nepal that happened in the year 2015. The government decided to make this data public so that it can be used in future to prevent such a massive hit, or at least reduce the damage and also recover from such natural disasters the next time it happens, as those lands are prone to frequent earthquakes. Also, this can be generalized to any earthquake prone areas. We have also visualized our findings and built a Machine Learning model to make smarter predictions for assessing damages post an earthquake.
How we built it
There are two major datasets to be used here. One includes the damage assessment of buildings and the other one gives details about the structure of the building including the architecture and materials used.
We used Spark and Pandas to perform data analysis and visualized our findings using Plotly and Seaborn.
We then built a multiclass classification model to assess the damage caused by the earthquake. We tried three approaches namely bagging, boosting and the third one that cleverly balances between these two methods and called DART. We went ahead with the third one and got an F1 score of 0.7512 on the validation set.
We then plotted the feature importance and verified our findings of EDA.
Challenges we ran into
We initially got an F1 score of around 0.691 with bagging with Random Forest and tried MLP, boosting with Gradient Boosting as well. But we were able to increase the performance substantially when we used DART which is a relatively new algorithm and we had to learn it from scratch to be able to tune our ML model.
Accomplishments that we're proud of
We were able to do a lot of things with the dataset like a thorough EDA as well as a good ML model search with hyperparameter tuning.
What we learned
DART- A good balance between boosting and bagging, Plotly, Seaborn.
What's next for SmartShake
Our current model works well for the Nepal Earthquake dataset. This is a solution that works well as a generalized model. We want to apply this solution to handle this problem on a much bigger scale.
Built With
- jupyter
- lightgbm
- pandas
- particle
- plotly
- python
- scikit-learn
- seaborn

Log in or sign up for Devpost to join the conversation.