Inspiration
Lawyers spend a lot of time reviewing contracts and other documents. These documents often contain information, which require outside information to fully understand the context and relevance of the document at hand (e.g. a purchase price listed in a foreign currency makes it difficult to understand, at first sight, if a contract is important). A constant back-and-forth between the document and Google and, as a consequence, a loss of time is the result.
What it does
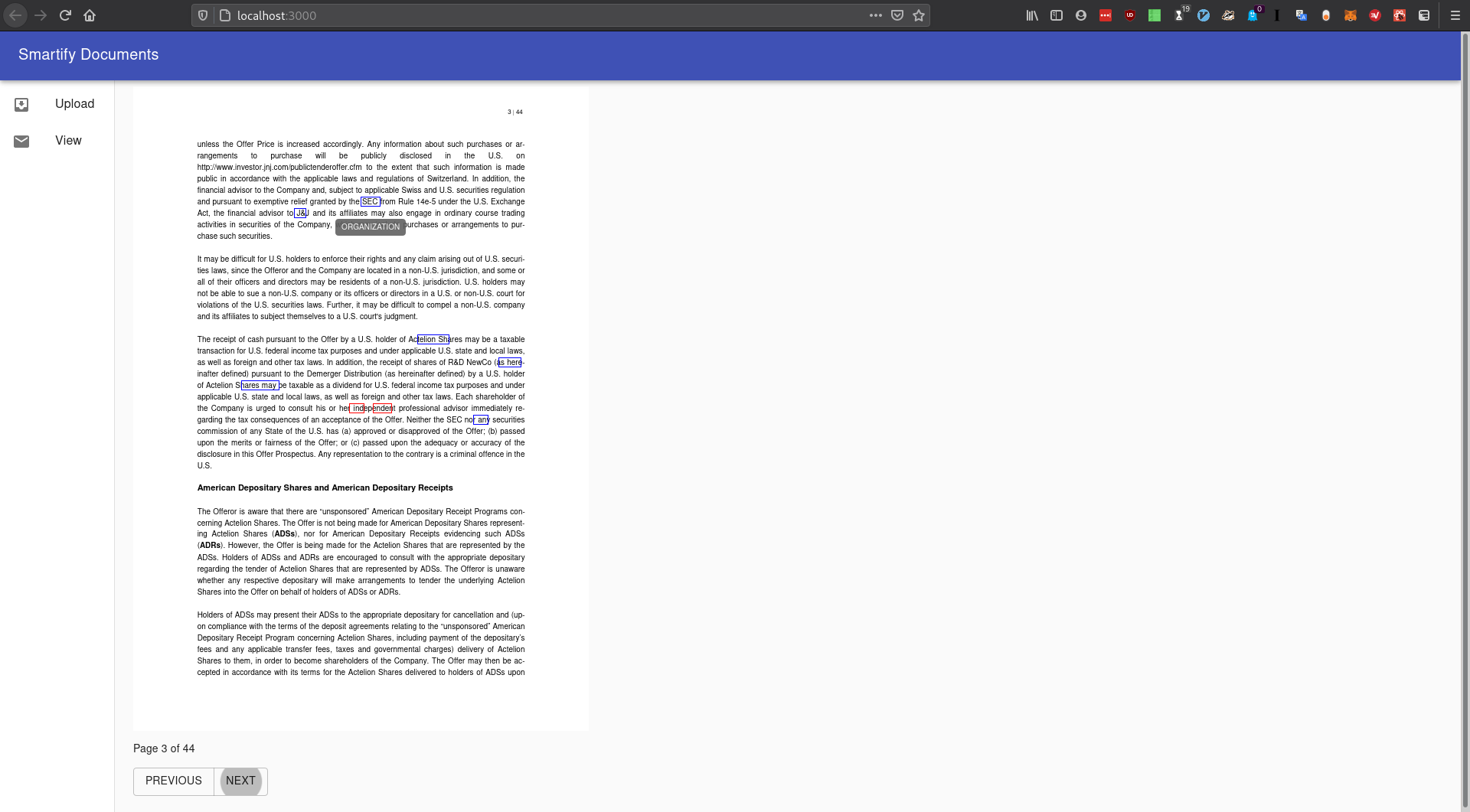
We created a service that enhance legal documents by recognizing important elements such as person names, company names, addresses and currencies and adding a hover-overlay which provides useful related information on these elements.
The user uploads their document (in PDF format for the moment, but eventually more types of document could be added) to the service. The document is then processed in order to extract the relevant information. Finally the result is displayed in a user friendly Webapp interface that runs locally.
How we built it
The project consists of two main parts: front end and back end.
The front end part has the responsibility for displaying the content of the document, matching the tagged information with its position on the page and showing an overlay.
On the back end side, the text content of the document is extracted and important information is selected using Named Entity Recognition (NER). The elements that the program looks for are: name of persons, reference to money/currency, company names and IDs, addresses.
Challenges we ran into
Finding the right tool was a long process. In particular we needed to find a free NER system that works reasonably well enough to be used as a starting point. We tried several open-source libraries (NLTK, Spacy, Flair), and they both have advantages and disadvantages to them. The best result was proced by flair, but recognition on one page takes on average 3.5 seconds on laptop hardware.
PDF is very unpleasant to work with programmatically, and it is quite difficult to make it render correctly in the browser. Not all aspects of PDF rendering in browsers is supported, adding interactivity on top of the render was especially hard. If we had more time and manpower, we could have probably made more finished frontend, but we made a successful POC.
Accomplishments
We made a program that is able to process PDF documents and find which where is the relevant information. The generated output is used to highlight corresponding parts of the document and the type of entity is also indicated.
What I learned
I have never used NER system before. I realised that there is a big diversity of such systems, with different levels of functionalities, such as Microsoft's Azure to NLTK which both sits at opposite ends of the spectrum, and intermediate systems such as Spacy and MonkeyLearn. (Alexandre)
I learned a lot about NER, and was impressed by pre-built classifiers provided with flair project. I think we also had an interested experience working remotely. (2 in Zurich, 1 in London)(Dmitrii)
What's next for Smartify Legal Docs
- Improve the recognition of the information, for example by fine tuning the Named Entity Recognition models. The recognition of addresses in particular need to be improved a lot.
- Improve the quality and quantity of the extra data in the overlay.
- Search for other elements to enhance, such as legal statuses and definitions, and anything that lawyers would find useful.
- Improve the rendering of the output, especially the alignment.
- Display more useful information based on the type of entity that is being highlighted.



Log in or sign up for Devpost to join the conversation.