-
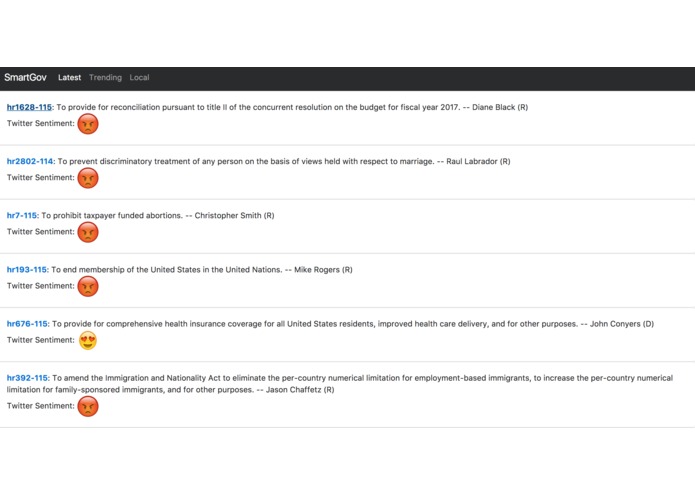
Main Dashboard
Inspiration
We were inspired by the crazy political times that we live in to build a tool that not only informs people about what is going on in congress but can potentially give insights to congress on public views on their work.
What it does
The app pulls popular legislation from the Sunlight Congress API. From the API we are able to get a summary of the legislation along with keywords, sponsors of the bill, status, and a link to the full bill itself. Then the app takes the summary of the bill and uses IBM Watson's keyword analysis to extract all of the important keywords from the summary. Using the keywords from Watson we then use the Twitter Search API and find popular tweets with the keywords. Finally we grab all of the tweets we searched for and do a sentiment analysis on each one. All this data is sent back to the Angular front-end view and populates the dashboard.
How I built it
The web app was built using NodeJS, Express.JS, and AngularJS. We used NodeJS and ExpressJS to build the API for the site and AngularJS to build the frontend webpages. All of the NLP(Natural Language Processing) was done using the IBM Watson Natural Language Understanding service along with the Python SDK. We also accessed the Twitter Search API through a Python SDK.
Challenges I ran into
We ran into many challenges with this project. The first challenge we ran into was finding summaries of the bills. Major legislation had good summaries but most legislation in the public datasets had no summaries at all. We spent a lot of time trying to use IBM Watson to do text summarization of the legislation but this led us down a deadend. We then decided to only use our service with legislation that has summaries. The next challenge we ran into was with the Twitter sentiment analysis. The generalized sentiment analysis from Watson was label many statements as neutral that should have been negative or positive because certain weights that were being given to words in the sentence. We talked to mentors from IBM and both of us came to the conclusion that we would have to use a hacky solution since we didn't have enough time and data to retrain Watson. The solution we used was to hand classify certain words as neutral so they wouldn't throw off majority of the sentiment analysis.
Accomplishments that I'm proud of
This hackathon was far more challenging than we initially thought. We ran into issues throughout the 24 hours but were eventually able to still ship a demo. I am proud of how we stuck with the project despite all of the setbacks and were able to quickly come up with solutions to our problem.
What I learned
We learned a lot about Watson and its abilities as a super computer. Our work with Watson taught us how high level machine learning and deep learning work in practice. In addition, this project taught us a lot about how to solve problems very quickly and adapt our project as the circumstances change.
What's next for SmartGov
At HSHacks SmartGov didn't work the way we wanted to. We barely found any legislative bills with summaries which made our dataset very small. In addition, we spent a lot of time on the sentiment analysis that we weren't able to optimize the querying. The querying was so slow that for the demo we pre computed the analysis and saved them to a .json file that the server would read from. This means the current service isn't in realtime. The first thing we want to do is take a deep learning approach to doing summarization. We know we need a summarized version of the legislation to make it both easy to understand for people but also computers. We are planning on setting up a neural network that is trained on legislation that already has summaries written for them. With the ability to summarize the bills on the fly we will be able to move more of the app to real time. We also want to optimize the whole process of querying tweets and doing sentiment analysis. One approach is to utilize multi-threading with the sentiment analysis since we are doing sentiment analysis on over a hundred tweets. By spreading the load we will be able to do sentiment analysis faster. Another thing we noticed is many pieces of legislation have similar keywords that result in similar tweets that we end up analyzing; we want to use Redis to cache the results so we can grab cached results of sentiment analysis of tweets we have already analyzed in the past. Finally we want to make this an open source project that others can contribute to

Log in or sign up for Devpost to join the conversation.