Inspiration
Many university students rely on lecture recordings to study, catch up on missed classes, or review difficult concepts. However, when watching these recordings independently, students often encounter moments of confusion or questions without a way to get immediate answers.
Our team recognized this gap in the learning experience and set out to make lecture recordings more interactive and supportive. To address this challenge, we created Lectura, an interactive AI tutor that learns alongside students as they watch lecture recordings.
What it does
Lectura enhances the lecture-watching experience by providing real-time academic support. Using facial recognition, the system can detect when a student appears confused and provide immediate assistance before they fall behind.
The AI is also trained on historical data about course concepts, allowing it to identify topics that students commonly struggle with. When these topics arise, Lectura provides targeted explanations, helpful tips, and practice problems to reinforce understanding.
How we built it
Because real educational datasets containing student performance and confusion signals are often confidential, we started by building a small-scale prototype.
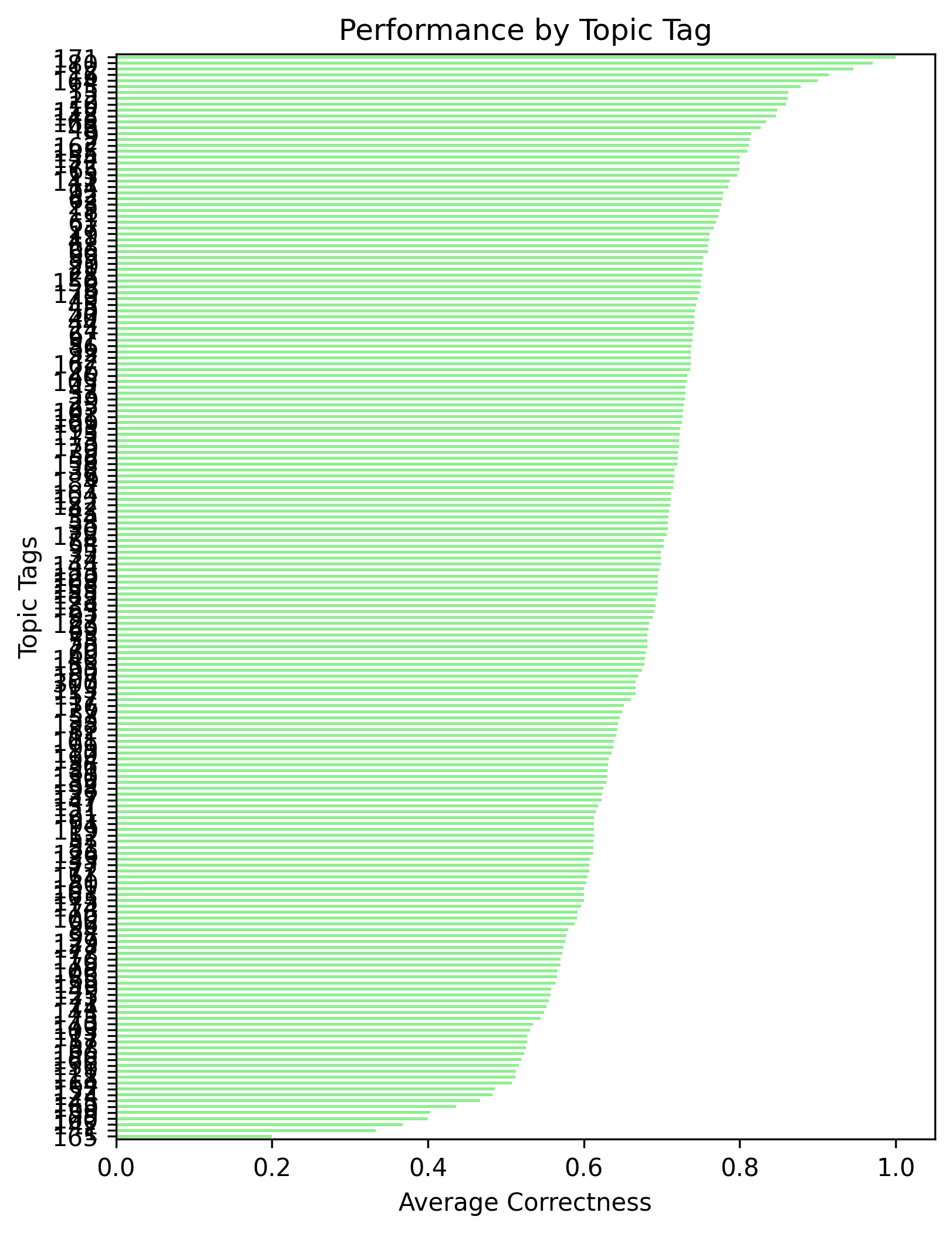
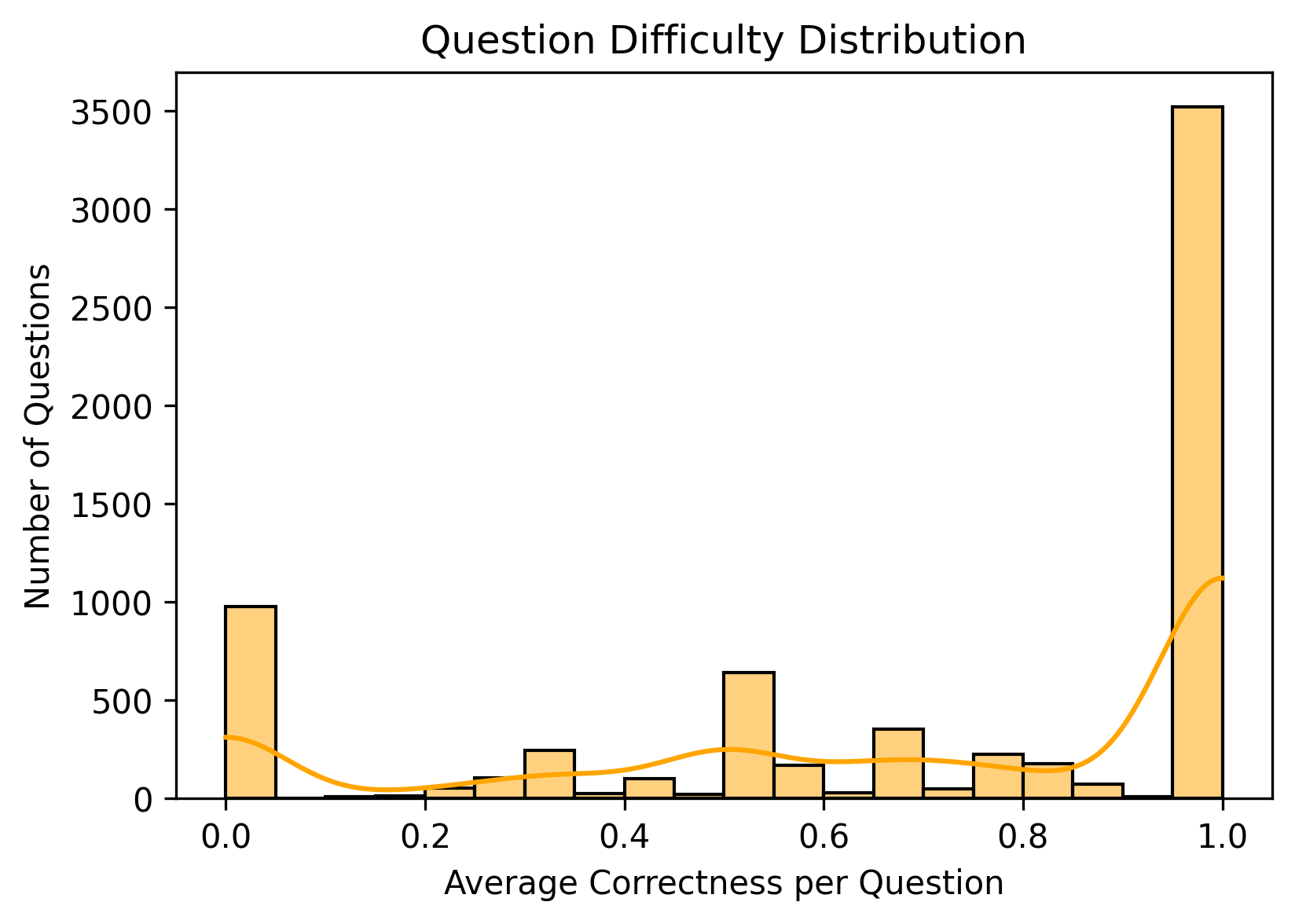
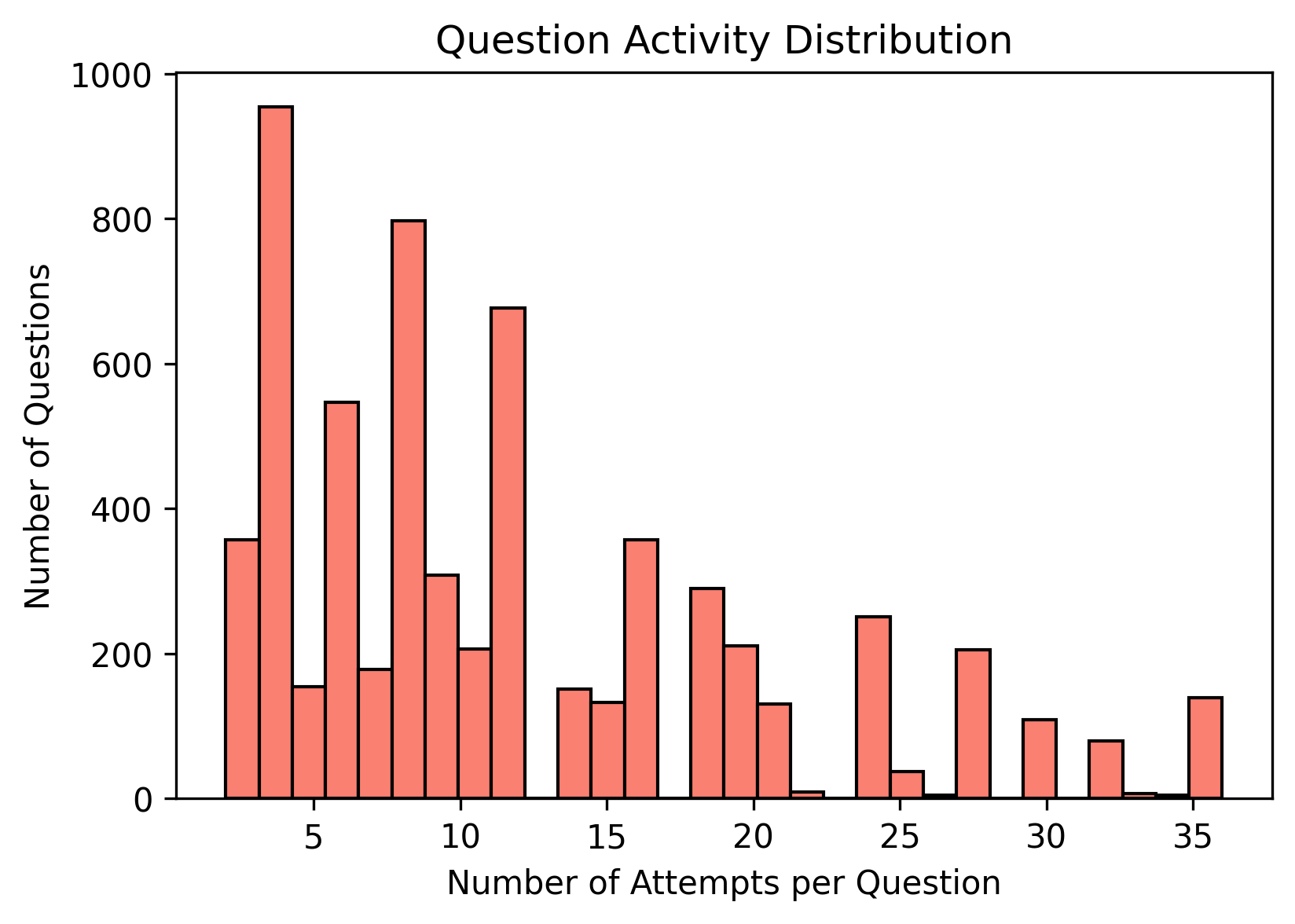
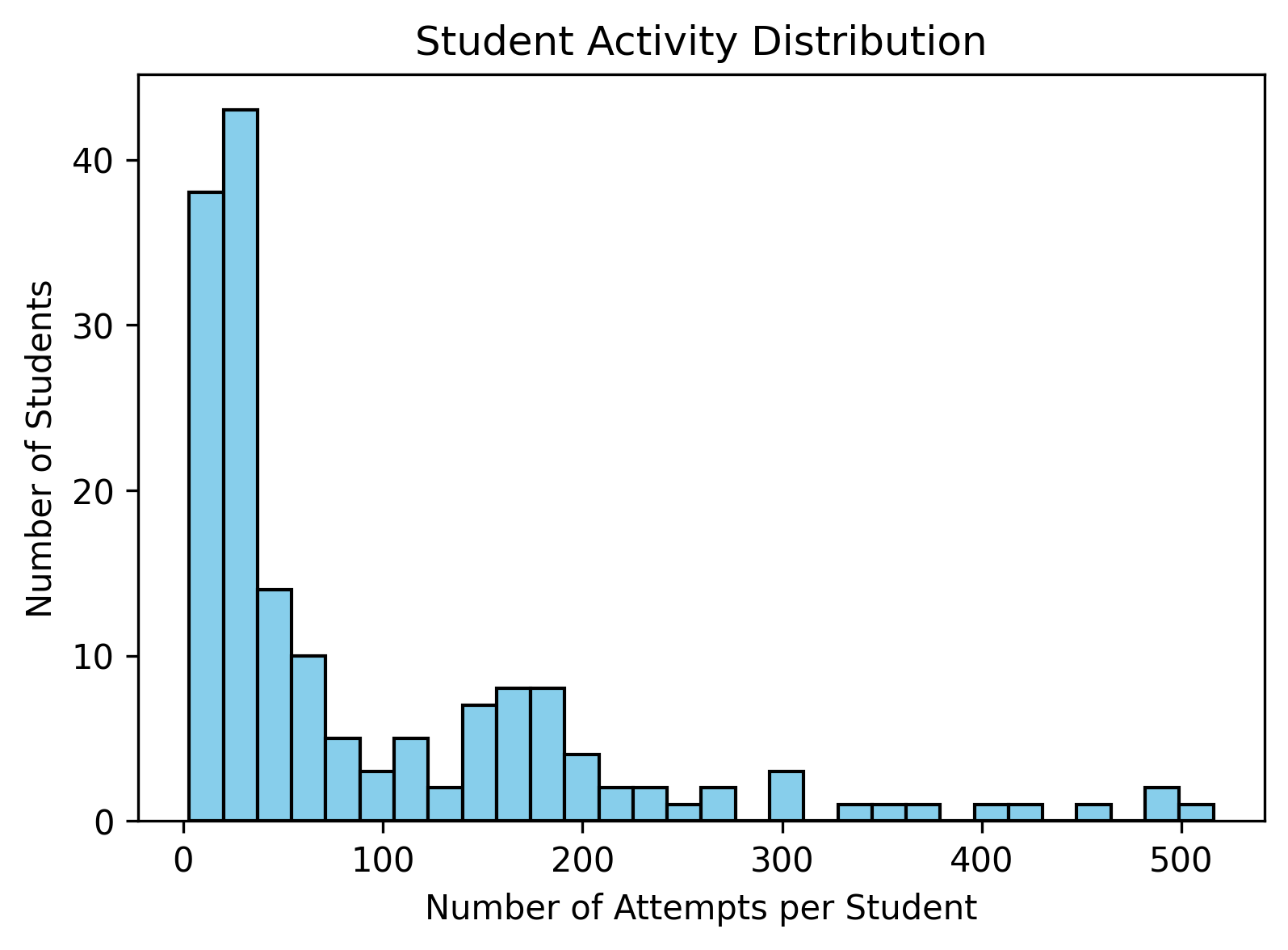
We used a YouTube video on basic algebra as our lecture content and generated synthetic data around concepts mentioned in the video. These concepts were not randomly chosen; we selected topics that students frequently struggle with in real life, such as inverse operations.
The synthetic dataset included:
- Practice questions
- Whether students answered correctly
- Time taken to complete the question
- Common mistakes made when answering incorrectly
For the AI tutor, we used the Google Mediapipe Facial Landmarker API to detect facial expressions and identify moments when a student may be confused. We used the Claude API to generate explanations and learning support. We also used a YouTube Transcript API to extract the lecture transcript so the AI could identify the concepts currently being discussed in the video.
Using Python, we connected these APIs with our generated dataset to create a fully functioning prototype of Lectura.
Despite generating synthetic data for our prototype, we also discovered EdNet, a dataset that closely resembles the type of data we would ideally use to train our AI. EdNet contains student–system interaction data collected over two years by a multi-platform AI tutoring service called Santa.
The dataset includes information such as questions grouped by the concepts they test, lectures grouped by the concepts they cover, the time students spent on each question, student responses, and the correct answers. This type of structured learning data is exactly what our product would need to provide accurate explanations and timely interventions when students struggle with certain concepts.
In the future, integrating datasets like EdNet would allow Lectura to train on large-scale real student learning patterns, enabling the AI to better predict when students are confused and provide even more personalized explanations and support.
Challenges we ran into
One of our biggest challenges was defining exactly how we wanted to address the problem. Even after deciding to build an AI tutor, identifying the right features and datasets took significant discussion and iteration.
Each member of our team initially had different ideas for how the system should work. However, through collaboration and continuous refinement, the final product emerged from our combined perspectives and teamwork.
Accomplishments that we're proud of
We are proud that our prototype successfully demonstrates the core functionality we envisioned. Even though it is currently a small-scale system, we were able to build a working version in a very short amount of time and prove that our concept is feasible.
What we learned
Through this project, we gained experience in several areas of AI and software development, including:
- Frontend and backend development
- Working with APIs
- Data scraping and transcript extraction
- Data generation, cleaning, and analysis
- Identifying real-world pain points and designing solutions around them
- Coding in Java, Python, and HTML
What's next for Lectura
Our long-term vision is for Lectura to support students across many disciplines and learning environments. In the future, we hope to train the system on larger and more diverse datasets so it can assist students in subjects ranging from molecular biology to machine learning.
Ultimately, we aim for Lectura to make lecture recordings a more interactive, personalized, and effective learning experience for students around the world.

Log in or sign up for Devpost to join the conversation.