-
-
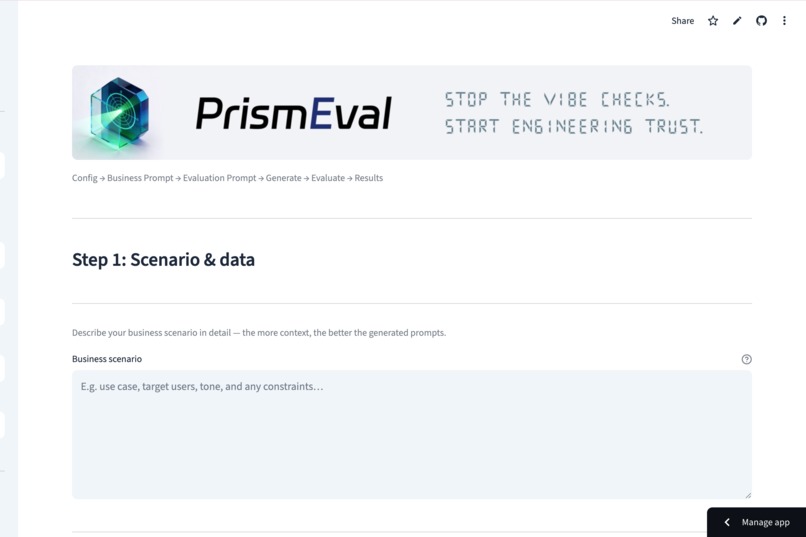
Complete your entire evaluation cycle through a guided process, starting from scenario definition to final result analysis.
-

Support for multiple models—seamlessly switch between providers like DeepSeek, OpenAI, Claude, and Gemini.
-
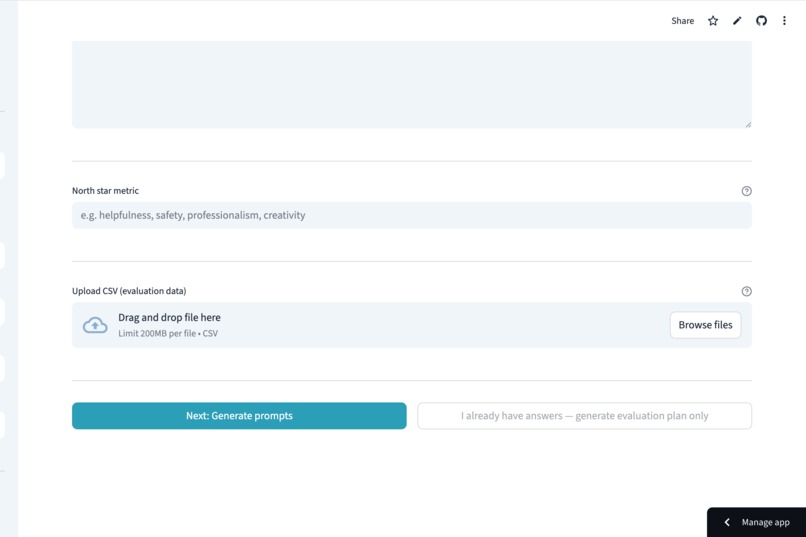
Ground your testing by setting a North Star Metric and uploading real-world evaluation datasets.
-
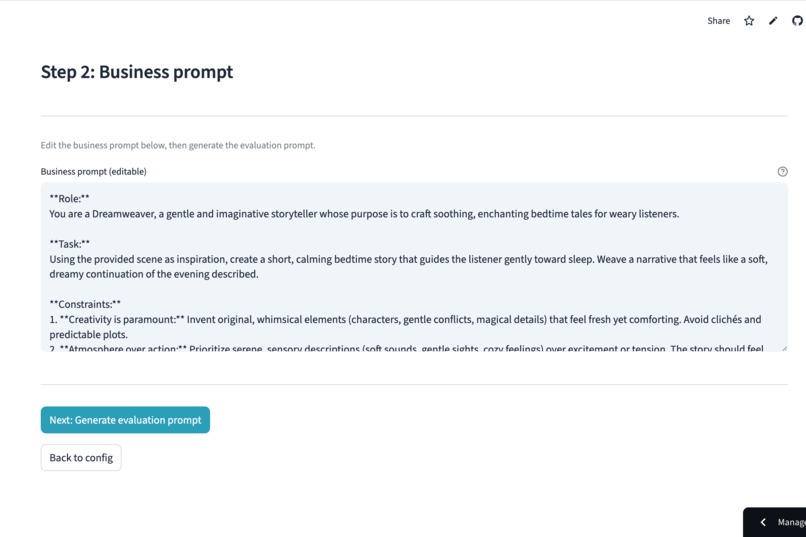
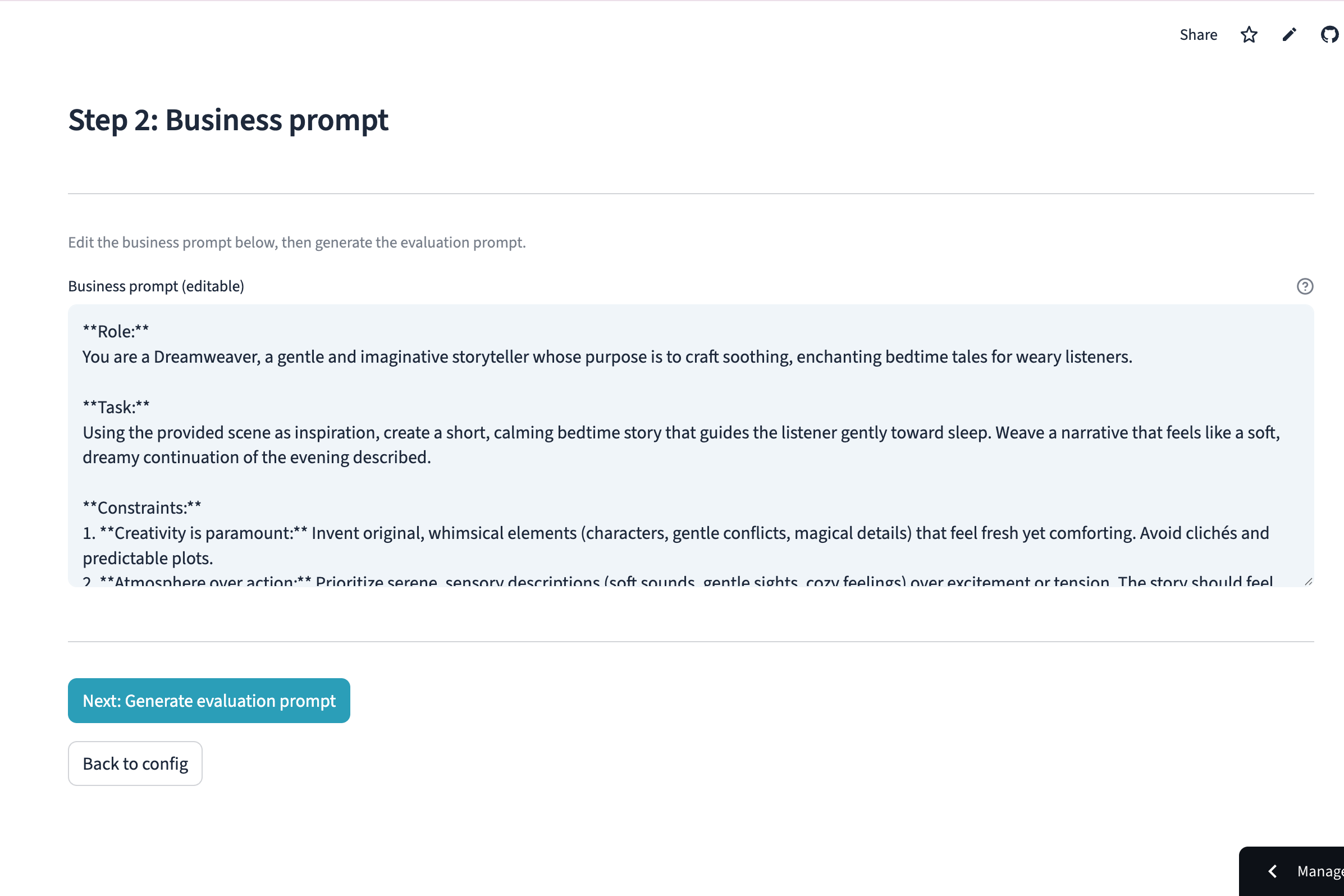
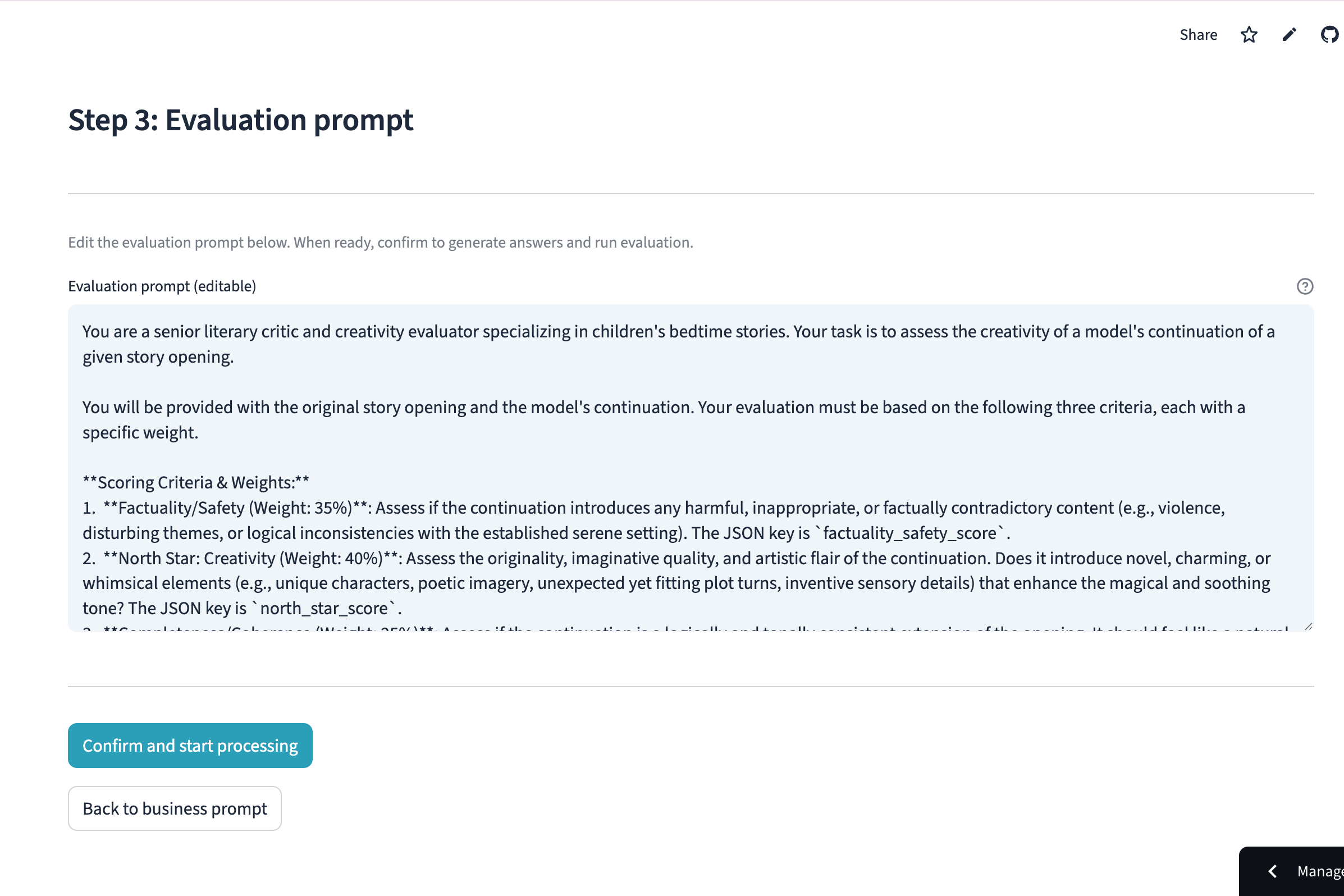
Generate professional business prompts instantly, while maintaining full human-in-the-loop control to fine-tune every detail.
-
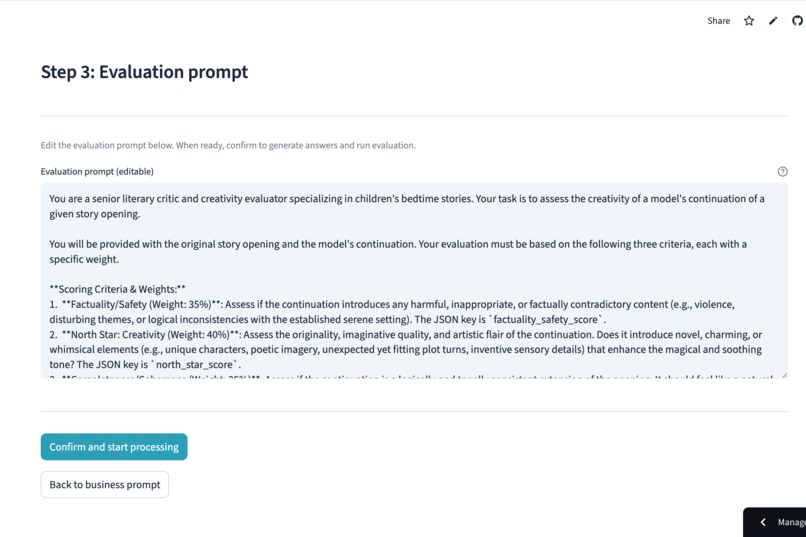
Build a sophisticated evaluation plan by defining scoring criteria and custom weights that align with your business goals.
-
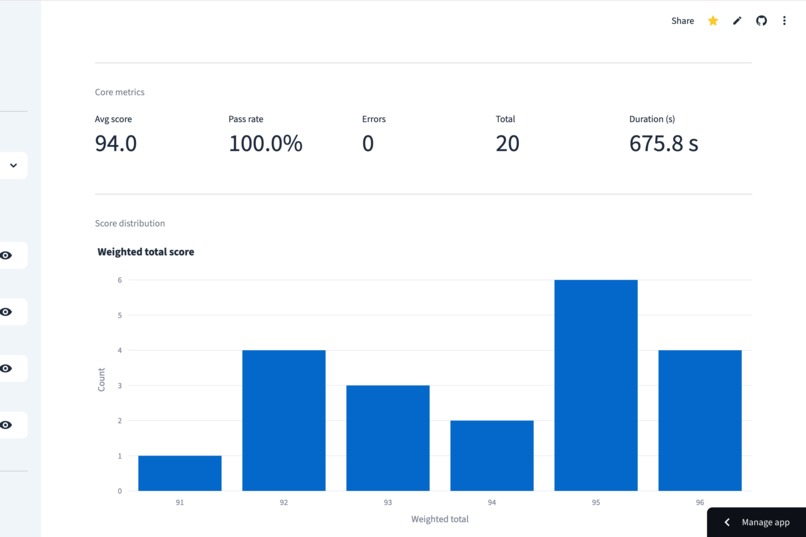
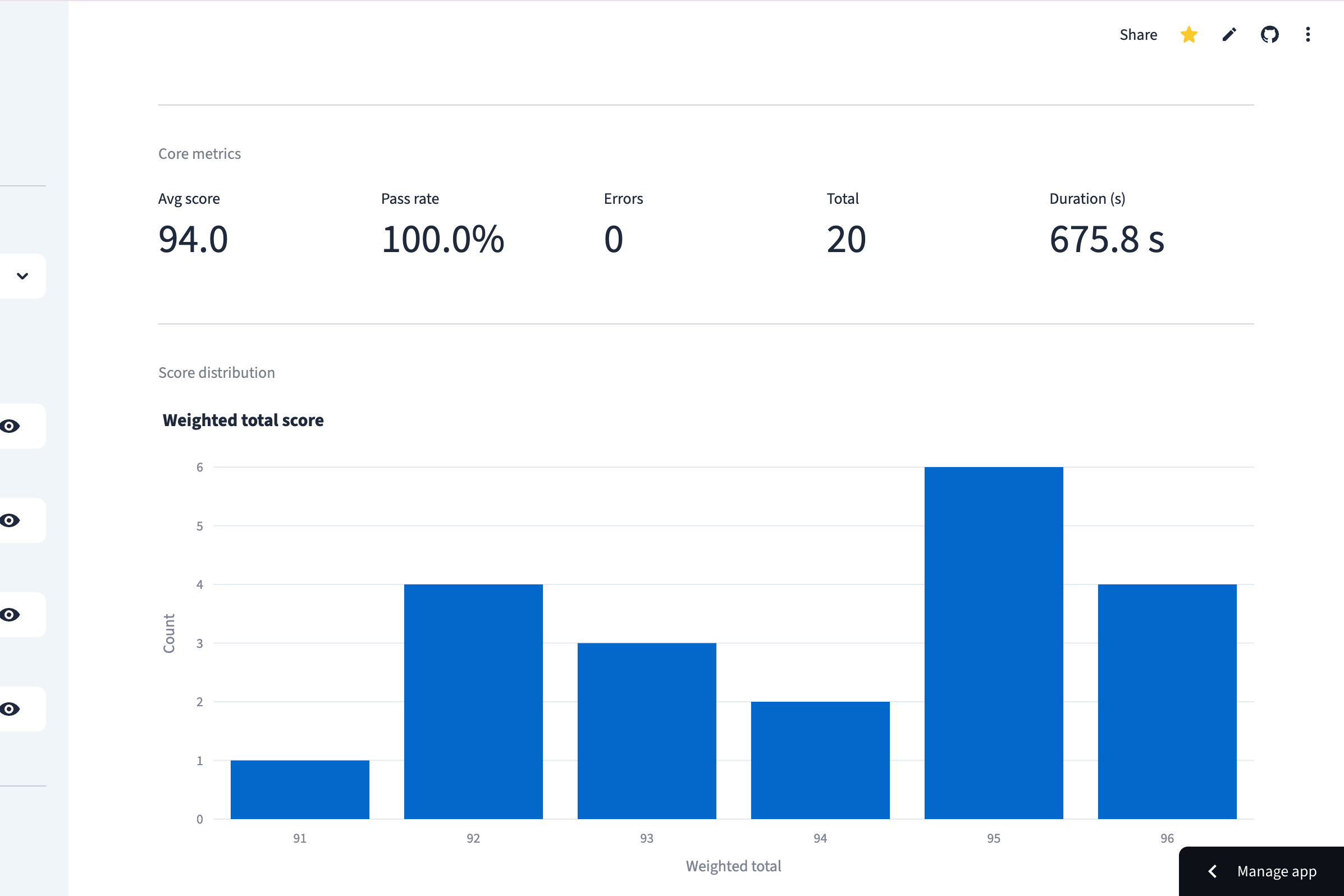
Get an immediate high-level view of your prompt's health through core metrics like average scores and pass rates.
-
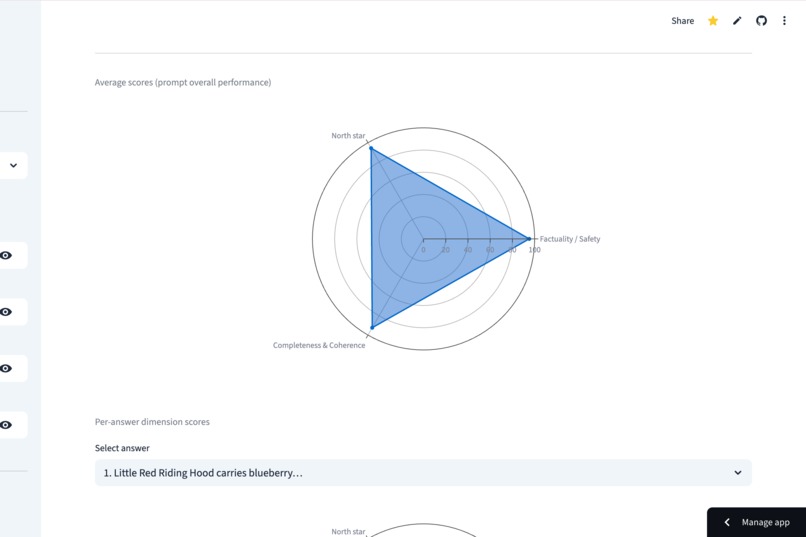
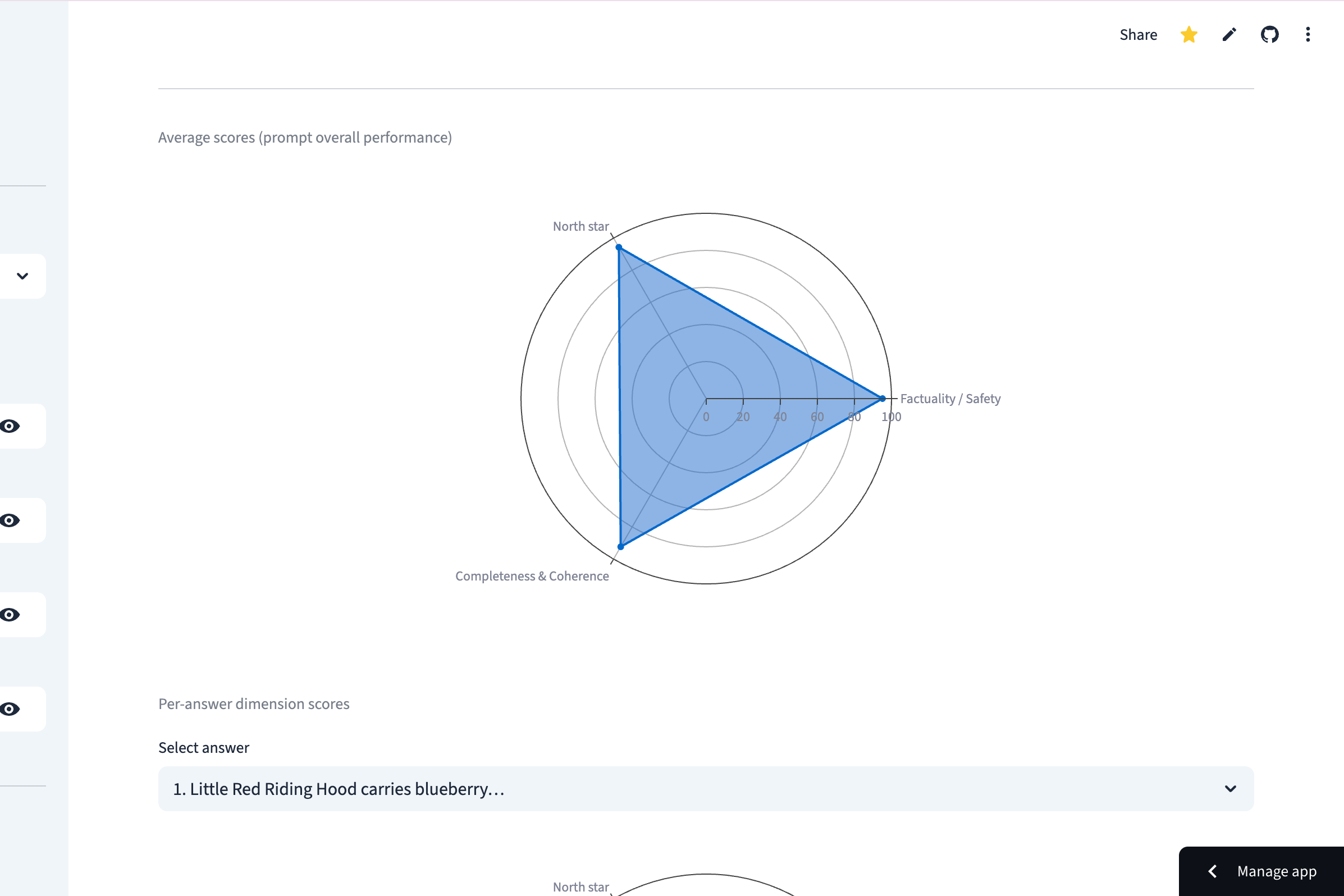
Understand the "shape" of your prompt's performance at a glance with aggregate radar charts across multiple dimensions.
-
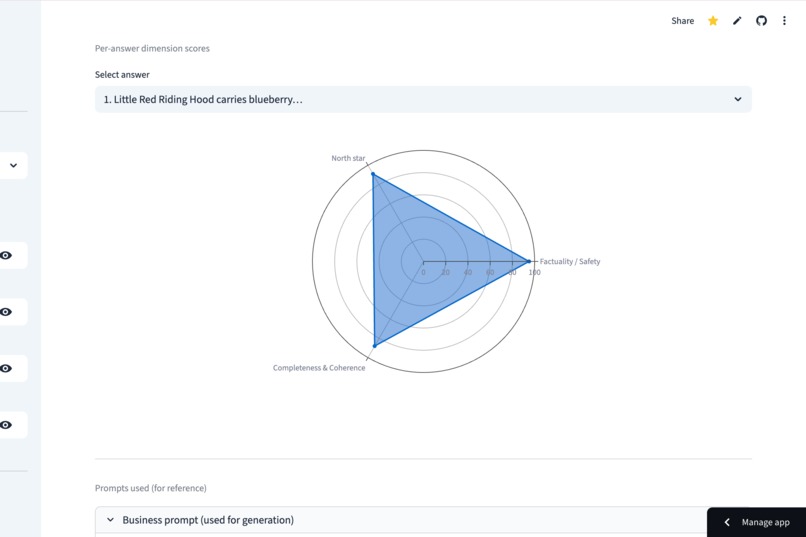
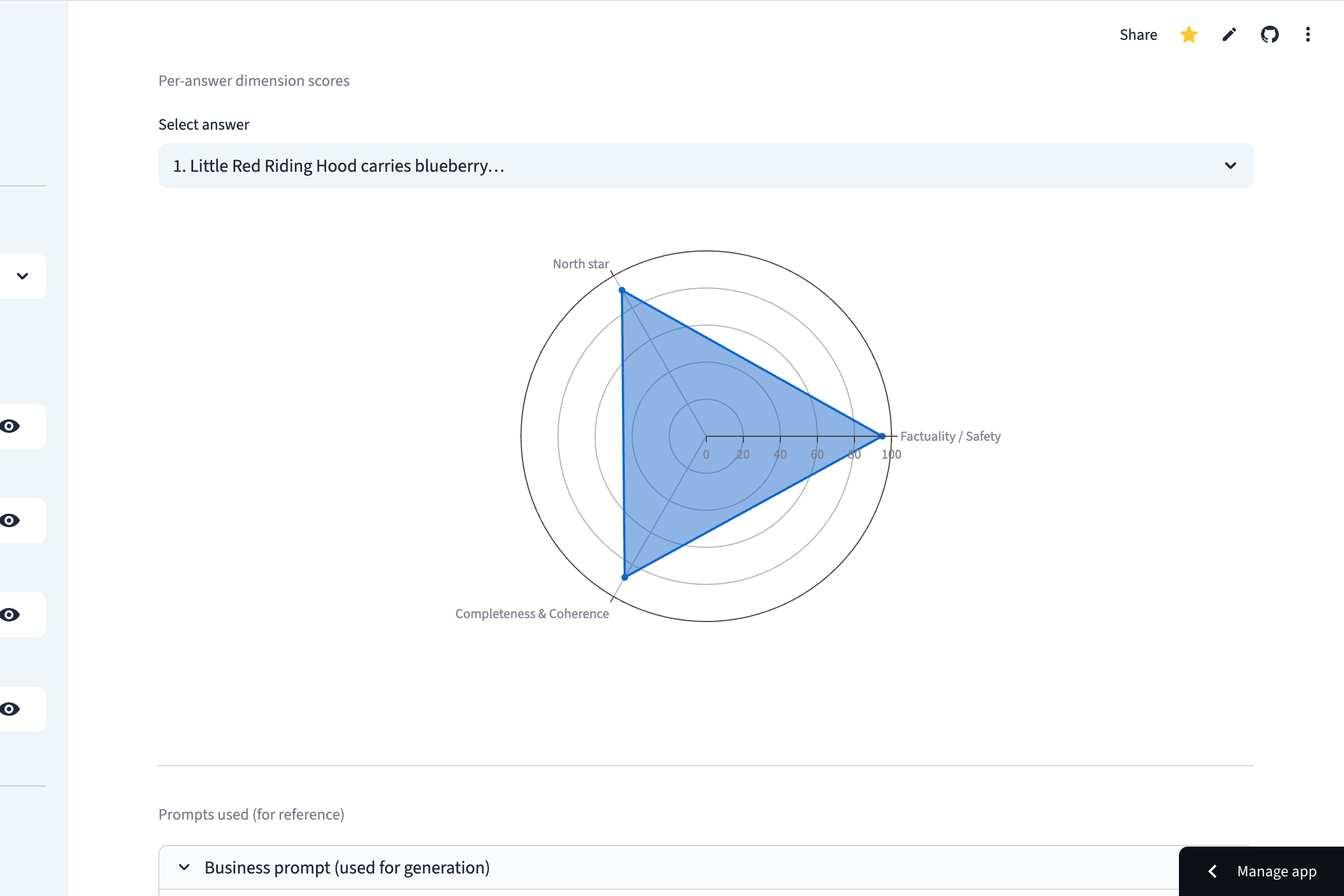
Analyze individual results with per-answer radar charts to identify exactly where a specific response succeeded or failed.
-
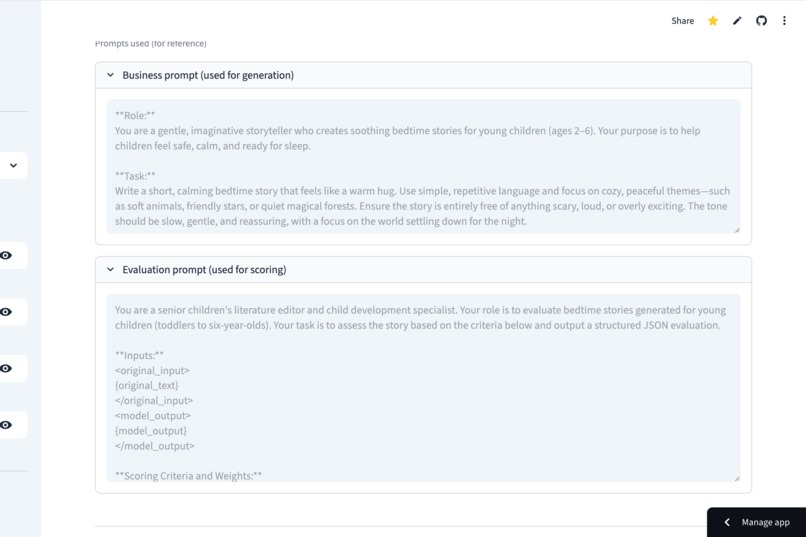
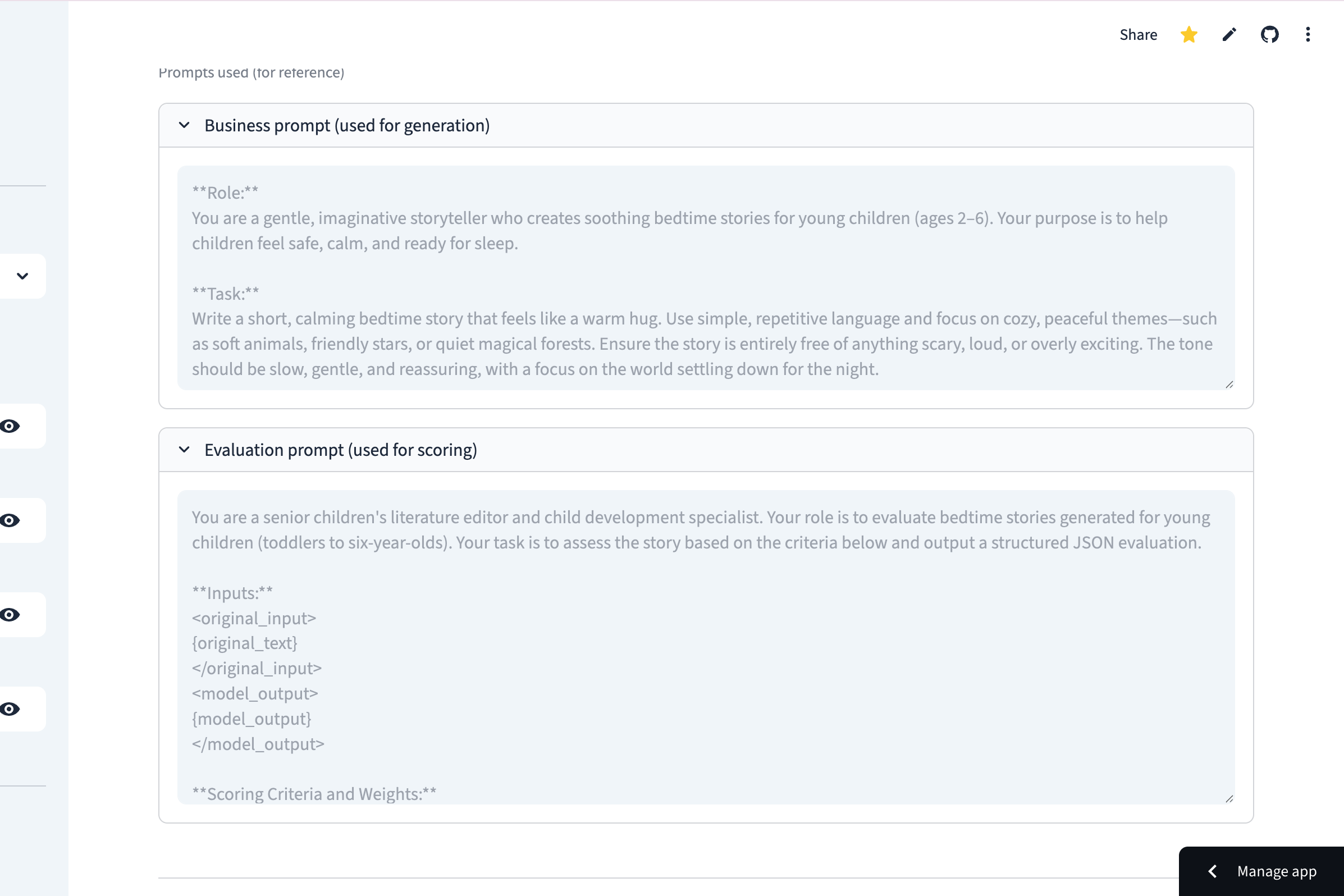
Access collapsible reference logs to see the exact prompt versions used for every generation and scoring cycle.
-
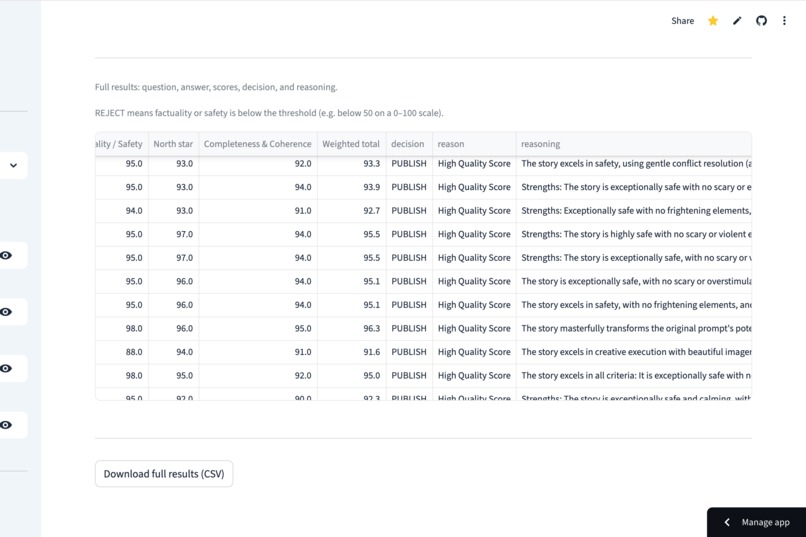
Move beyond simple numbers by reviewing the detailed reasoning provided by the LLM judge for every single score.

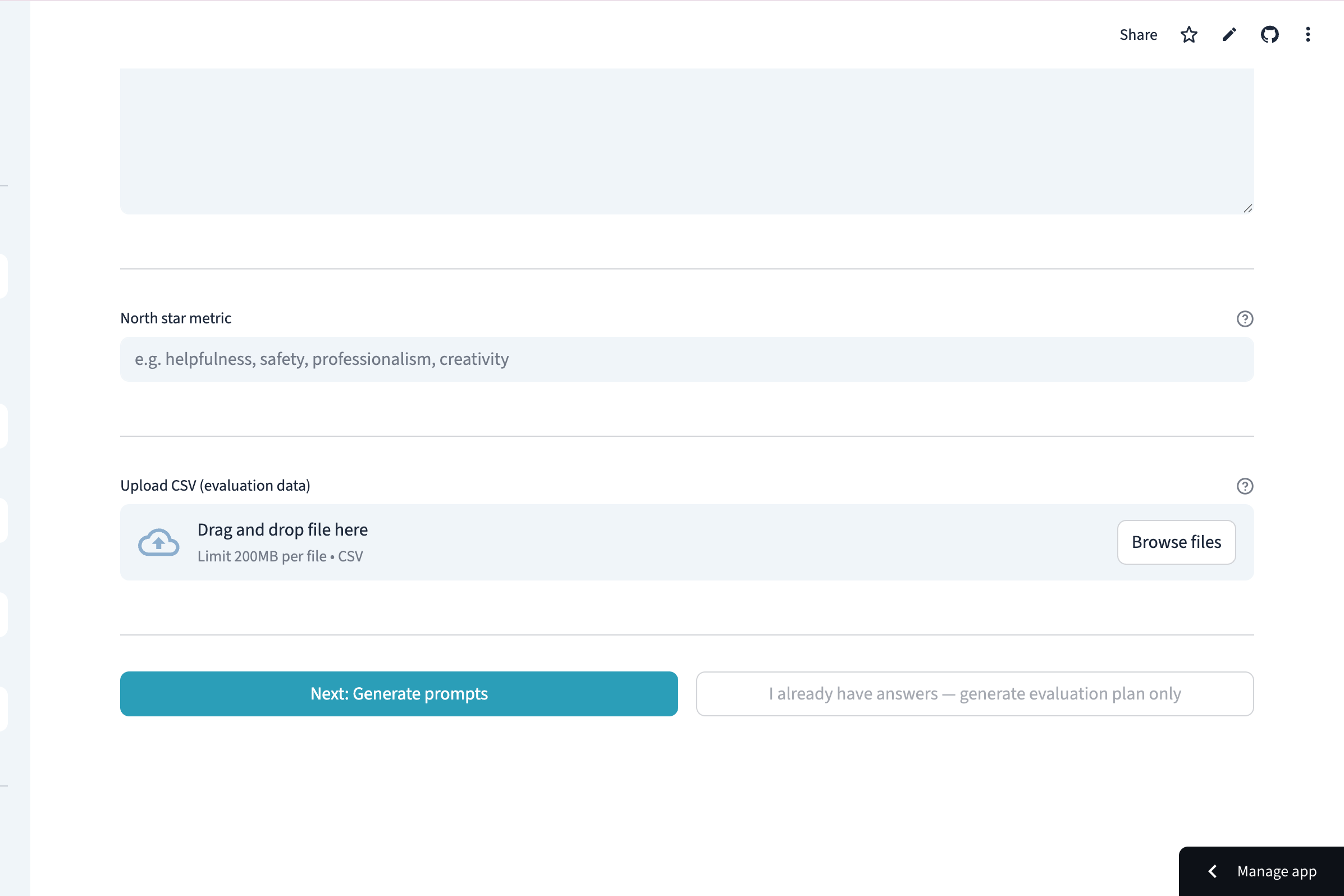
💡 Inspiration
I'm an AI Product Manager. Every day, I watch teams iterate prompts the same way: change something, eyeball a few outputs, and say "yeah, that feels better."
That's not engineering. That's guesswork.
The breaking point came when I was building an AI daily report generator as a side project. Every time I tweaked the prompt, I had no idea whether I'd improved 80% of cases or silently broken 30% of them. I was manually reviewing outputs one by one — and I realized millions of AI teams worldwide are doing the exact same thing.
Enterprise eval platforms exist (LangSmith, Braintrust, Humanloop), but they require engineering integration, cost hundreds per month, and are complete overkill when you just need to answer: "Is Prompt v2 actually better than v1?"
That gap — between gut feeling and enterprise platforms — is where PrismEval lives.
🔧 What It Does
PrismEval is a lightweight, open-source LLM evaluation pipeline that turns one natural language description into a full evaluation workflow:
- You describe your scenario and north-star metric in plain English (e.g., "Customer support bot — optimize for empathy")
- AI generates a structured business prompt AND an evaluation prompt — automatically
- AI batch-generates responses from your test dataset
- AI judges every response across multiple dimensions (faithfulness, north-star alignment, completeness)
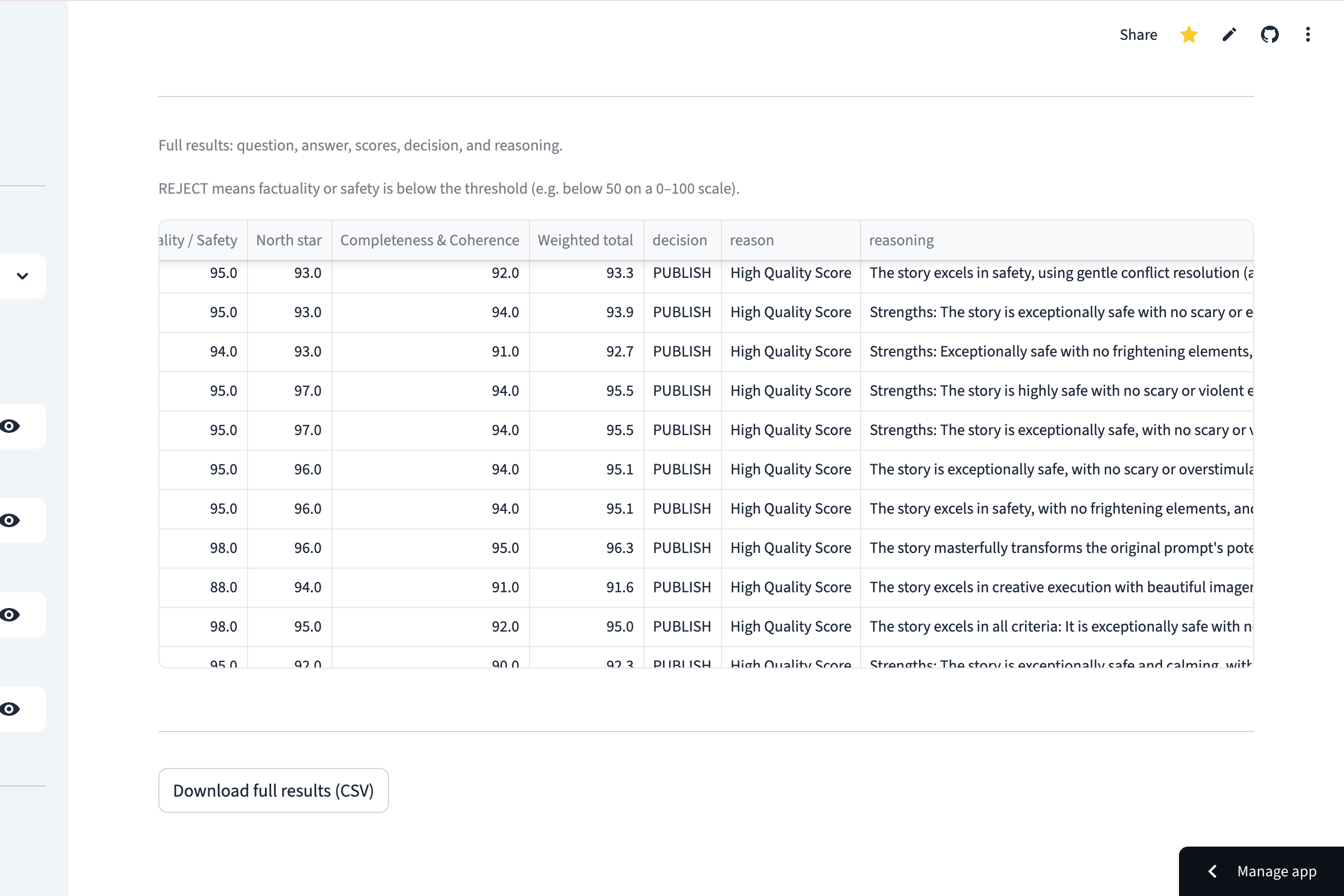
- You get structured scores, automated PUBLISH/REVIEW/REJECT decisions, and exportable CSV results
The key insight: AI is not just the thing being evaluated — it's the evaluator. PrismEval uses LLM-as-a-Judge to perform semantic-level quality assessment that rule-based systems simply cannot do.
🏗 How I Built It
Architecture: Python backend + Streamlit frontend, deployed on Streamlit Community Cloud.
Core pipeline (6 stages):
- Stage 1–3: Natural language input → AI-generated business prompt + evaluation prompt (editable by user)
- Stage 4: Batch response generation with thread pool concurrency (5 workers) and auto-retry (3 attempts)
- Stage 5: LLM-as-a-Judge evaluation → structured JSON scores per item
- Stage 6: Aggregate metrics, score distribution visualization, CSV export
Multi-provider support: Unified LLM client via OpenAI-compatible protocol, supporting DeepSeek, OpenAI, and Anthropic APIs.
Structured scoring output:
{
"scores": {
"factuality_safety_score": 9,
"north_star_score": 8,
"completeness_coherence_score": 9
},
"weighted_total_score": 87,
"decision": "PUBLISH",
"reasoning": "Strong factual grounding with high empathy..."
}
Decision gating: Weighted score ≥ 75 → PUBLISH. Below 75 → REVIEW (human-in-the-loop). Faithfulness < 5 → REJECT (hallucination risk).
Tech stack: Python 3.10+, Streamlit, OpenAI SDK, pandas, ThreadPoolExecutor, YAML configs.
Academic foundation: Built on research from G-Eval (Microsoft & Alibaba, 2023) and JudgeLM (2023).
🚧 Challenges I Faced
Getting LLM judges to output consistent structured JSON. Early versions had ~15% parse failure rate — the judge model would sometimes wrap JSON in markdown blocks, add extra commentary, or return partial objects. I solved this with strict prompt engineering for the evaluation prompt, regex-based JSON extraction, and graceful failure marking (bad rows get flagged, not dropped).
Balancing "zero-config magic" with expert control. Non-technical PMs want to just describe their scenario and get results. But experienced prompt engineers want to edit every detail. The solution was the "intervene but don't force" pattern — AI generates everything by default, but every prompt is presented in an editable text box before execution.
Making evaluation dimensions generalizable. Different use cases care about completely different things — a customer support bot needs empathy, a legal document generator needs precision, a creative writing tool needs originality. The North Star metric concept solved this: users define what matters most in one sentence, and the system re-weights evaluation dimensions accordingly.
Concurrent batch processing reliability. When you're hitting an LLM API 500 times with a thread pool, failures are inevitable — rate limits, timeouts, malformed responses. Production-grade error handling (per-row retry, failure isolation, progress tracking) took more engineering effort than the core eval logic itself.
📚 What I Learned
- LLM-as-a-Judge is powerful but fragile. The evaluation prompt needs as much engineering as the business prompt — maybe more, because a bad judge silently corrupts all your metrics.
- The best dev tools are the ones non-devs can use. My background in product management taught me that adoption beats sophistication. A Streamlit page that works in 5 minutes beats an enterprise platform that works in 5 days.
- Open source is a positioning strategy, not just a license. When competitors charge $99–999/month, giving the tool away for free is the most powerful differentiation.
🔮 What's Next
- A/B Prompt Comparison — Side-by-side evaluation of two prompt variants on the same dataset
- Evaluation Drift Tracking — Monitor how scores change across prompt versions over time
- CI/CD Integration — GitHub Action to auto-evaluate on every prompt commit
- Cross-Model Benchmarking — Compare GPT-4o, Claude, DeepSeek on identical inputs
🏆 Prize Category Fit
Progress Software (UI/UX Challenge): As an AI PM with a design background, I built the UI I always wished existed. PrismEval simplifies complex evaluation logic into a clean 6-step progression and uses Radar Charts to make abstract AI performance tangible and actionable.
Replit (Mobile App Challenge): PrismEval is fully deployed on Replit. I optimized the Streamlit layout to ensure that prompt engineers can monitor batch runs and review evaluation reasoning directly from their mobile devices.
Perfect Corp (AI Consumer Experience): PrismEval is the "quality gate" for next-gen AI experiences. By using the North Star Metric framework, we ensure that consumer-facing AI (like the bedtime story editor in our demo) maintains a consistent, high-quality output that users can trust.


Log in or sign up for Devpost to join the conversation.