-
-
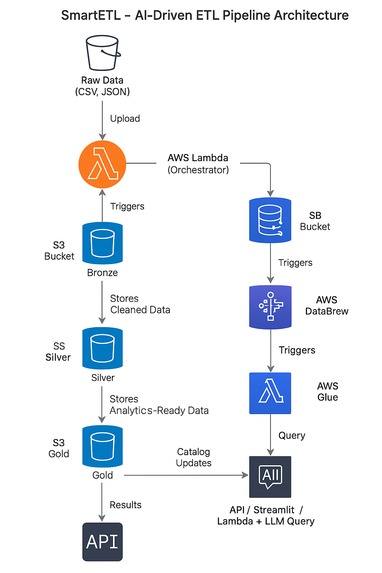
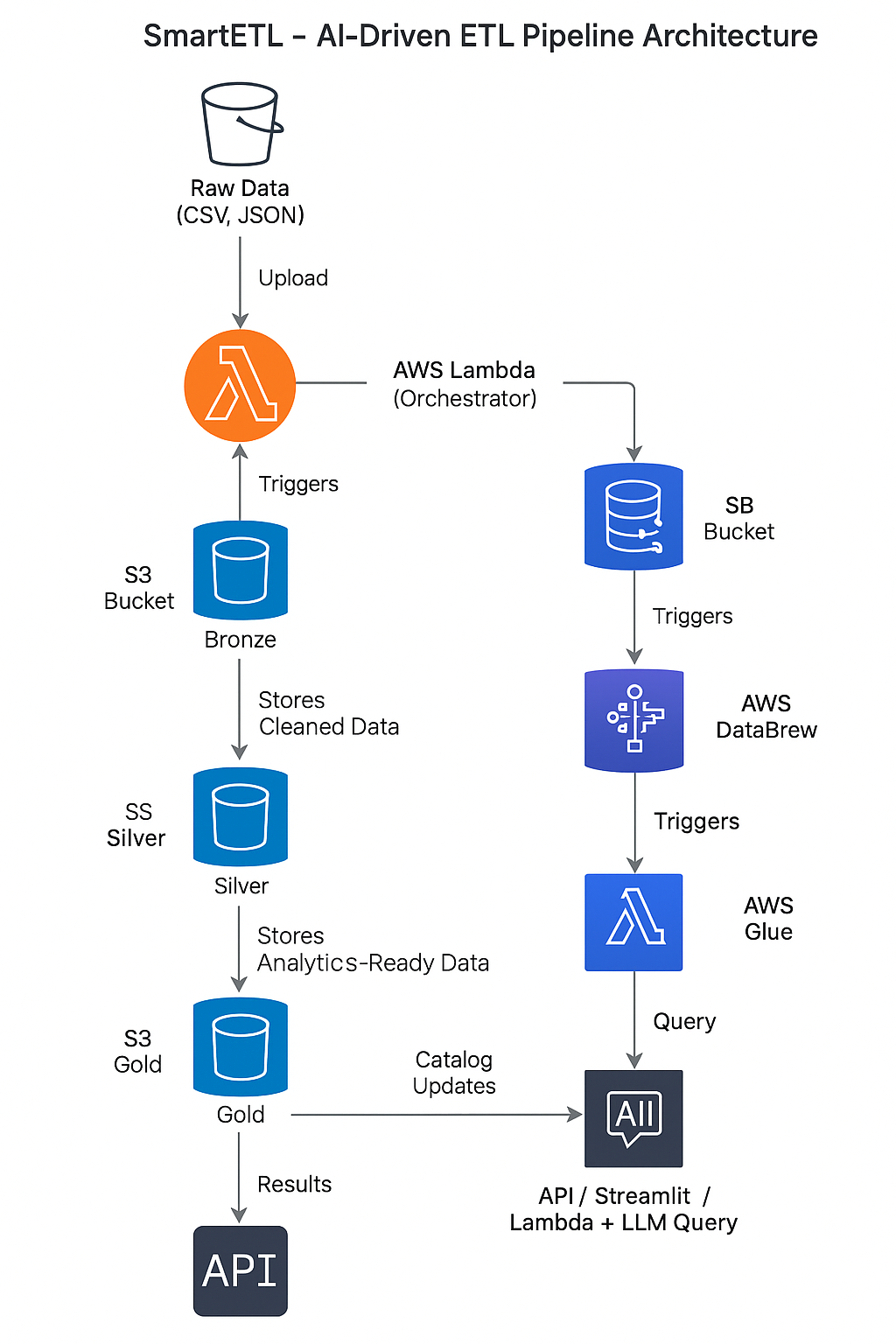
Architecture Diagram
-
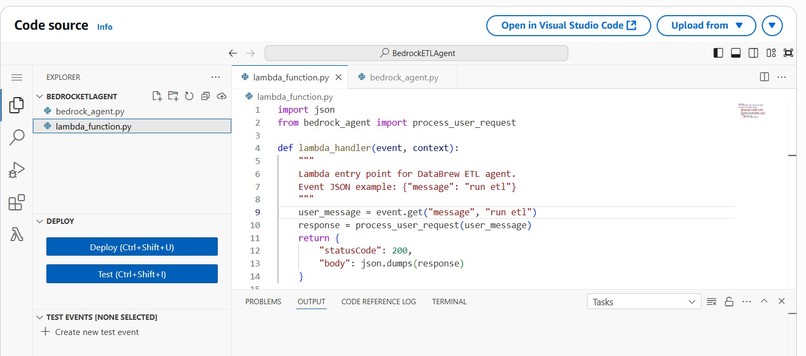
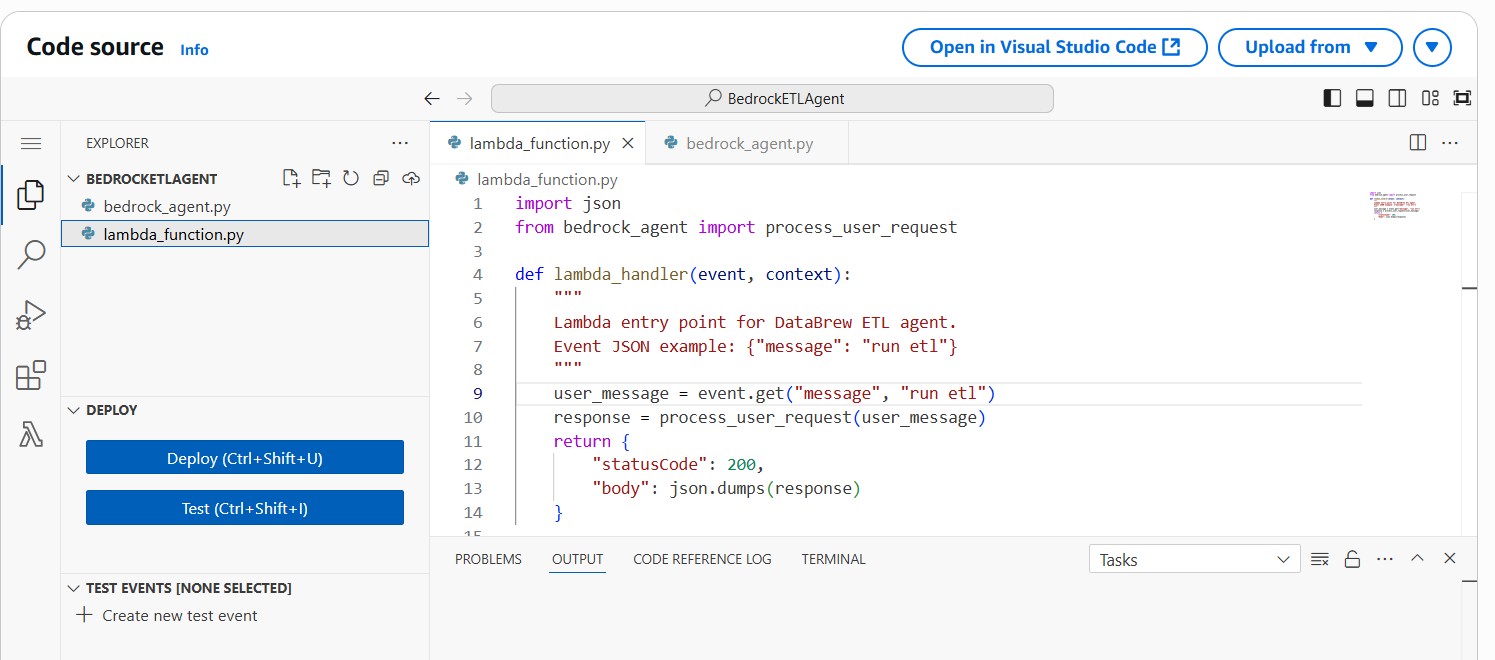
lambda function
-
Github repo
-
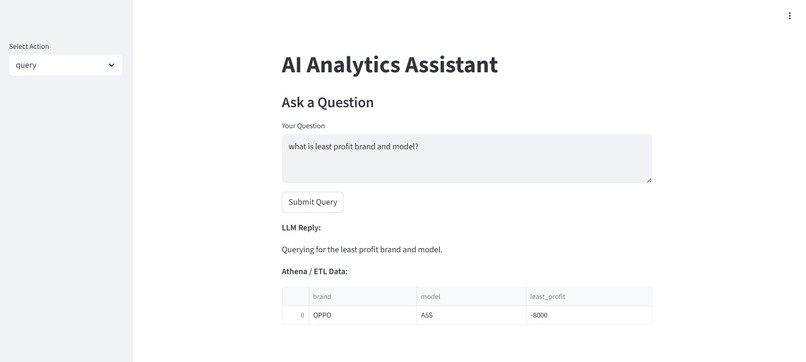
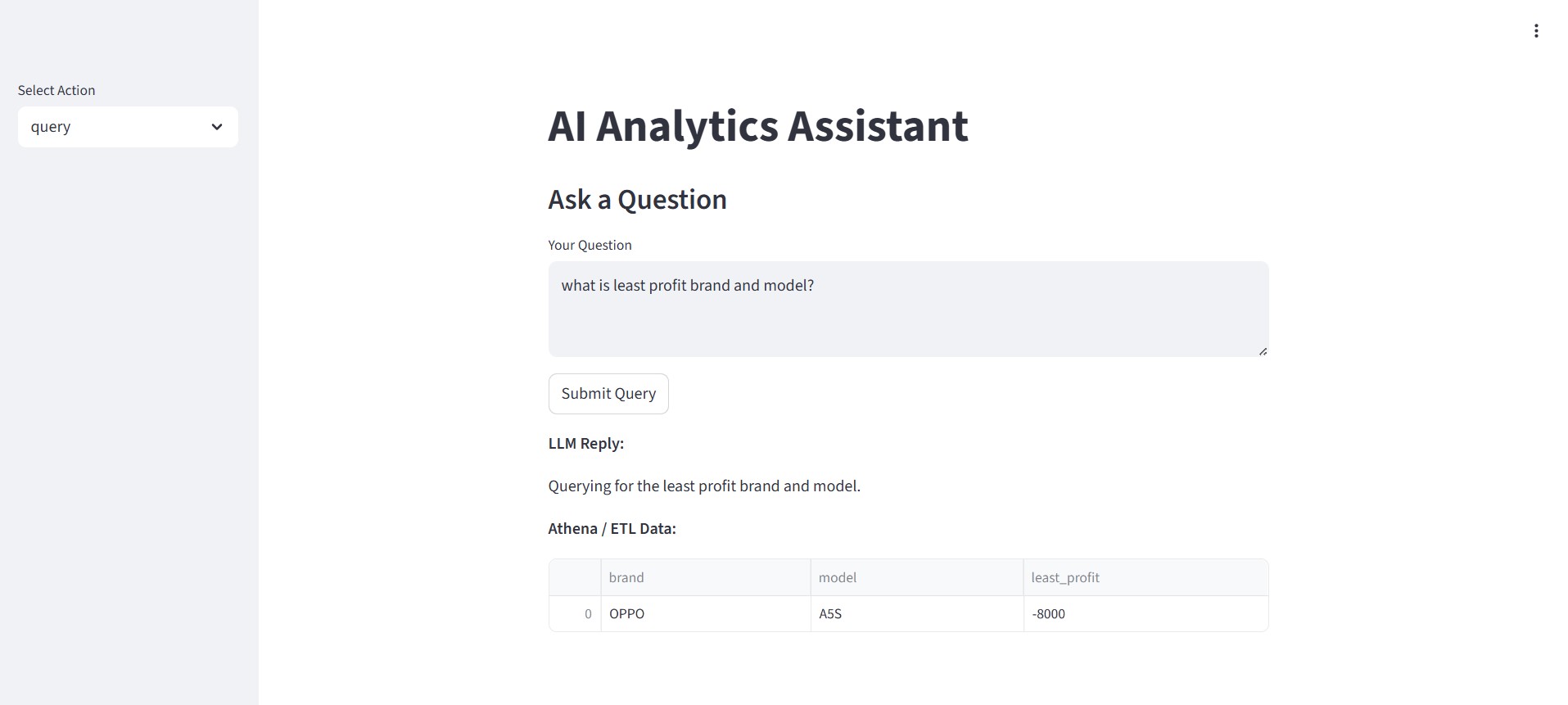
UI
SmartETL – AI-Driven Automation for Data Operations
Inspiration
Managing large-scale ETL pipelines manually is time-consuming, error-prone, and often lacks real-time insights. We wanted to build a system that automates the movement, transformation, and analysis of data, while also allowing business users to interact with it using natural language. Our goal was to make ETL pipelines smarter, faster, and more accessible.
What it does
SmartETL automates the ETL process across Bronze → Silver → Gold layers in a data lake:
- Detects and processes new data in S3.
- Cleans and transforms data using AWS DataBrew.
- Catalogs data with AWS Glue Crawlers.
- Allows ad-hoc queries using Athena.
- Provides a conversational interface through LLM integration, enabling users to request data insights using plain English.
- Logs all job metadata for traceability and monitoring.
How we built it
- AWS Lambda: Central orchestration of ETL jobs, crawlers, and Athena queries.
- DataBrew: Transformations and cleaning of data in a serverless environment.
- Glue Crawlers: Automatically detect and catalog datasets at each layer.
- Athena: Run SQL queries for business insights.
- EventBridge: Trigger Lambda for automatic ETL when new data arrives.
- LLM (Bedrock or ChatGPT API): Conversational interface for business users.
- S3: Bronze/Silver/Gold data lake storage and metadata logging.
Challenges we ran into
- Handling long-running jobs and Lambda timeouts.
- Configuring permissions across multiple AWS services (S3, Glue, DataBrew, Athena).
- Integrating LLMs with ETL pipelines to provide meaningful, context-aware responses.
- Ensuring data consistency and schema updates across different layers.
Accomplishments that we're proud of
- Successfully automated the entire ETL lifecycle from raw data ingestion to clean, queryable datasets.
- Enabled natural language querying for business users via LLM integration.
- Built robust logging and monitoring for all ETL operations.
- Created a scalable serverless architecture, reducing maintenance overhead.
What we learned
- The importance of fine-grained IAM roles and policies for multi-service orchestration.
- How to handle asynchronous service calls (DataBrew, Glue) in Lambda efficiently.
- Techniques for automating ETL pipelines while maintaining flexibility for future transformations.
- How to integrate AI/LLM tools to bridge the gap between technical data pipelines and business users.
What's next for SmartETL – AI-Driven Automation for Data Operations
- Enhance the LLM interface to provide richer insights and automated recommendations.
- Expand real-time data processing capabilities for streaming data.
- Implement more advanced transformation and anomaly detection with AI.
- Integrate with custom dashboards for visualization and interactive reporting.
- Extend to multi-cloud or hybrid architectures for broader enterprise adoption.


Log in or sign up for Devpost to join the conversation.