-

Analysing effect on cosine similarity using Google Universal Sentence Embedding
-
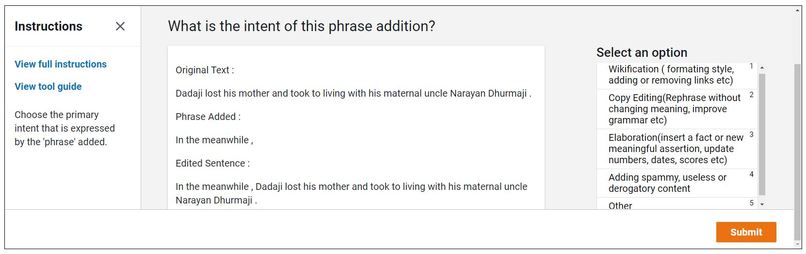
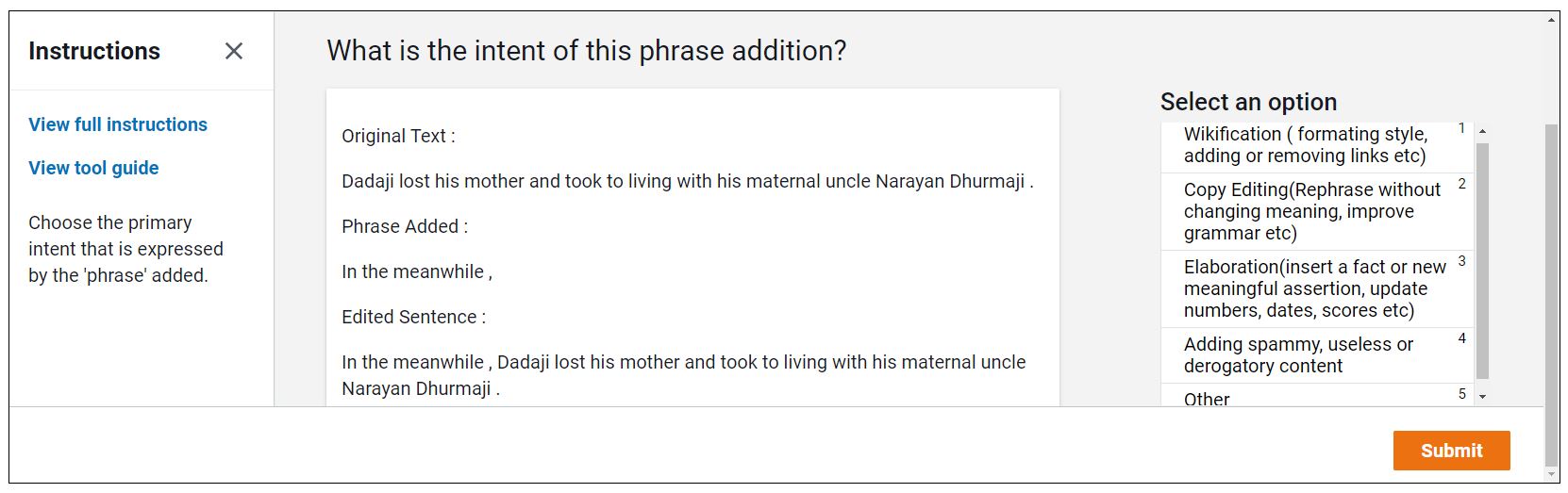
Designing Amazon Mturk Request
-

Identified categories from research paper
-
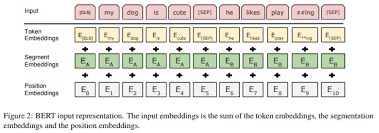
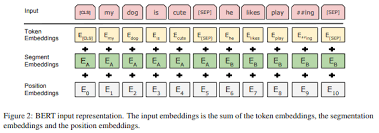
Used BERT embedding to predict categories of intent


Inspiration
The WikiAtomicEdits seemed to be a new dataset which we were not aware of but seemed to have a lot of interesting research questions. We aimed learning new architectures and natural language processing methods to analyze this dataset. This evolved into having one research based goal and one application oriented goal. Our research question being - Q. Can we identify the categories of edits made? What was their intention?
Our real-world use case being - Q. Could we use this to build a useful product or make any text based features in technology?
What we did ?
Identified research paper on Wikipedia edit intention Yang, D., Halfaker, A., Kraut, R., & Hovy, E. (2017, September). Identifying semantic edit intentions from revisions in wikipedia. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing (pp. 2000-2010).
Collected labelled data on Amazon Mturk using the intention categories found in the paper.
Trained a model using the dataset given in the paper. Tested it on the labelled data we collected.
Analysed various impacts of edits such as correlation in cosine similarity, patterns in the phrases added for each intent category.
Built a dataset for predicting location on inserting a given phrase.
Predictive model to find the correct position to insert the phrase.
How I built it
Modeling , Programming - Mostly using python , keras, pytorch. For visualization - used jupyter notebook, matplotlib, seaborn, plotly Amazon mturk - to collect data
Challenges I ran into
- Training time for the datasets
- Visualizing the analyses
- Building efficient models
Accomplishments that I'm proud of
- Contributed new dataset in the form of intent category labels.
- Working model to predict the category
- Built model to predict position of insertion of a keyword
What I learned
- Different NLP models
- Coming up with use-cases for a new dataset
- How to use Google sentence embeddings
What's next for SmartEdits
- Being able to come up with better models.
- Understanding the strengths and weaknesses of the dataset.
- Building a better prediction model for insert location.
- Use the current labels to identify the intent labels for the remaining dataset.
Built With
- amazon-mechanical-turk
- google-colab
- jupyter
- keras
- matplotlib
- plotly
- python
- pytorch
Log in or sign up for Devpost to join the conversation.