SmarTAI: The Story of an AI Teaching Assistant Born from TA Experience
The Inspiration: Shared Struggles in the Trenches
We are a team of four graduate students from the same undergraduate alma mater, who once served as teaching assistants (TAs) in computer science. During those late nights spent grading stacks of homework assignments, we confronted a universal pain point: meaningful feedback is crucial for student growth, yet manual grading is painfully slow, inconsistent, and unsustainable.
As TAs, we witnessed firsthand how students struggled with complex problem sets in advanced mathematics, algorithm proofs, and programming projects. A single assignment could involve:
- Multi-step derivations requiring logical verification
- Symbolic computations prone to subtle errors
- Code implementations demanding rigorous testing
- Conceptual questions needing domain-specific knowledge
The traditional approach presented three fundamental challenges:
- Time Burden: Grading 100+ submissions for a single problem could consume 10+ hours
- Inconsistency: Different TAs would apply scoring criteria differently, leading to fairness concerns
- Feedback Gap: By the time students received scores, the learning moment had often passed
We realized this wasn't just a logistical problem—it was an educational equity issue. Students deserved timely, personalized feedback regardless of class size or TA availability.
What it does
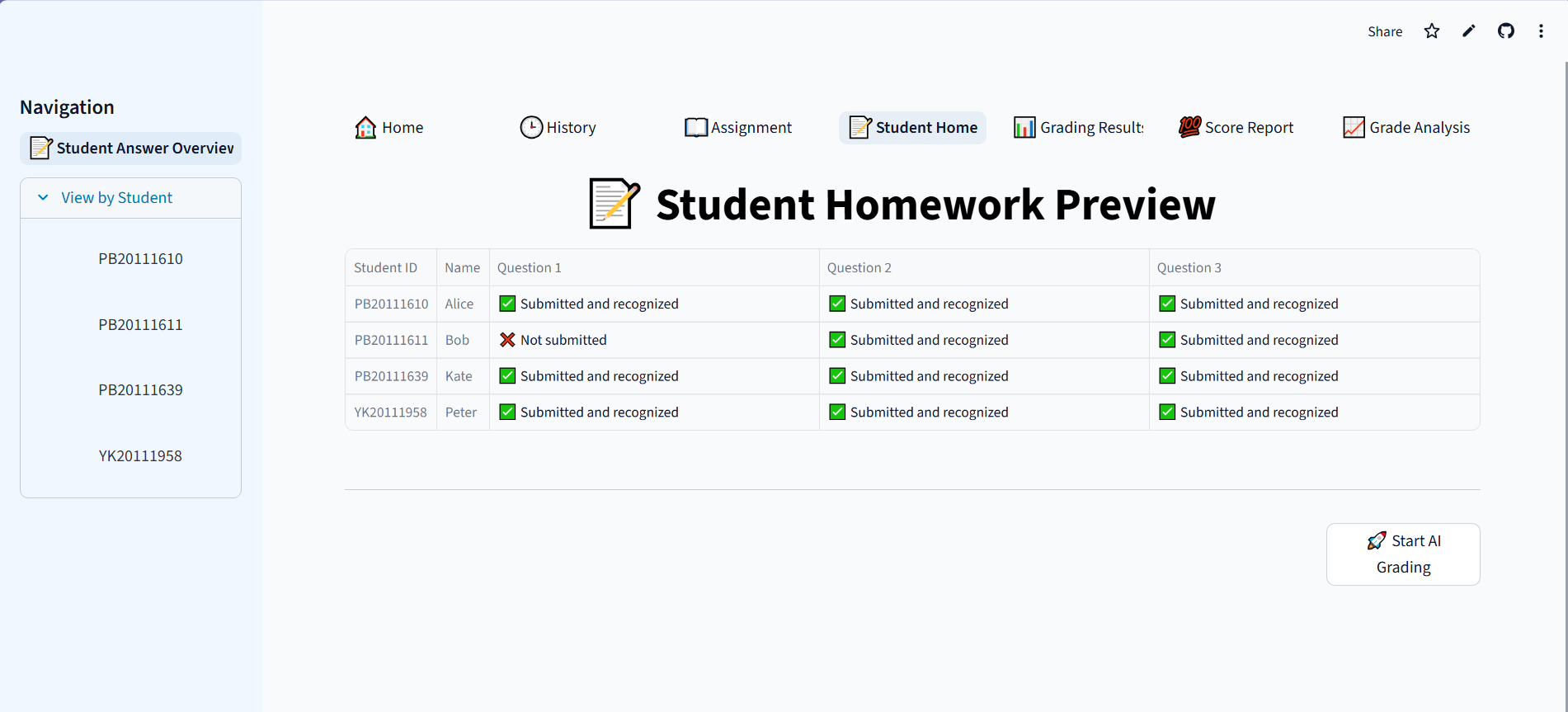
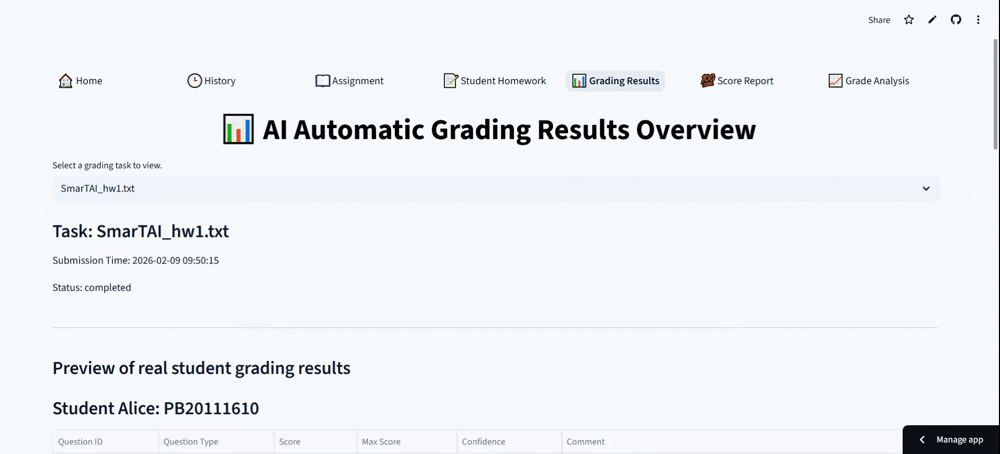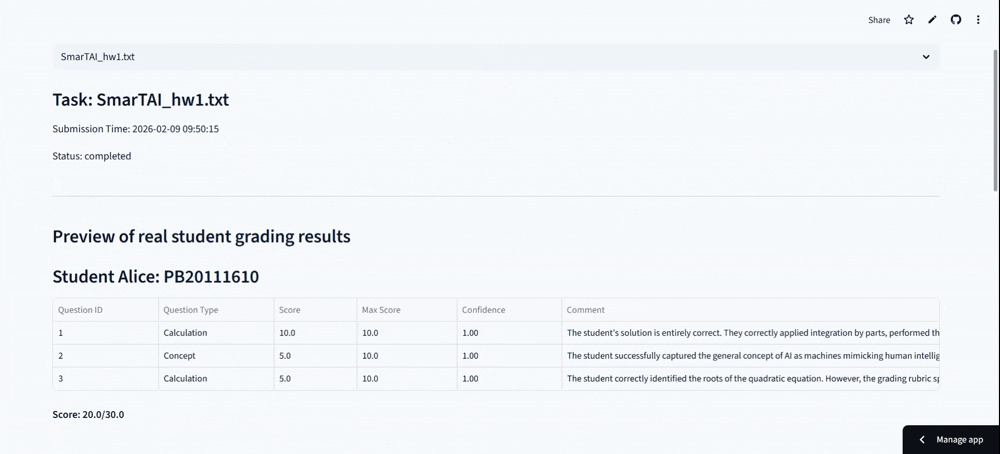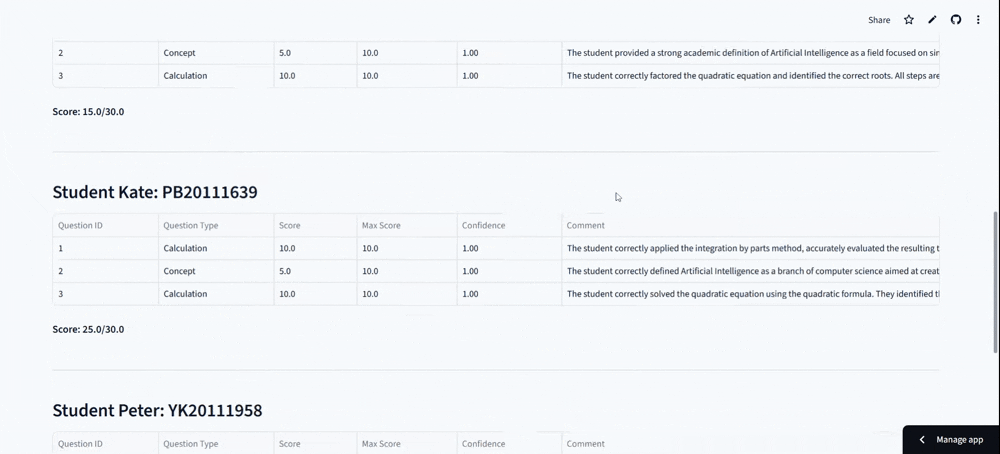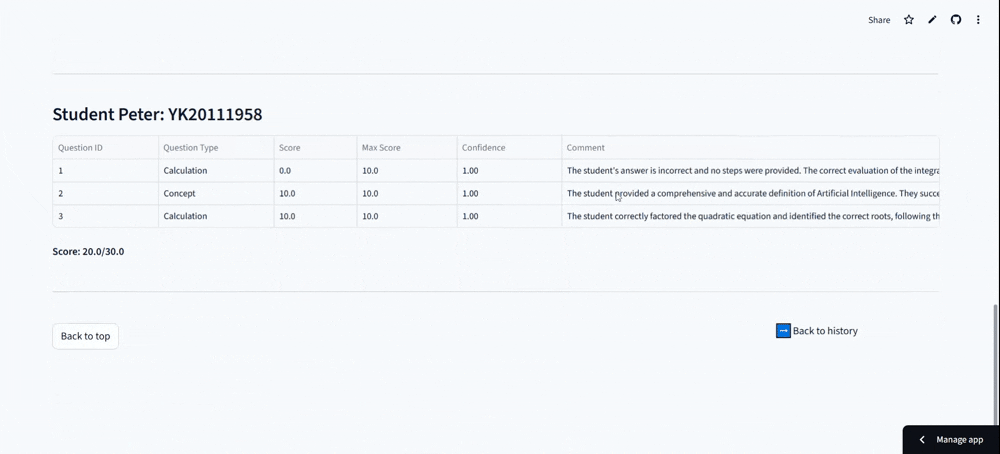
SmarTAI is an intelligent assessment platform designed specifically to handle the high complexity of STEM education. Unlike standard tools that only check final answers, SmarTAI serves as an end-to-end "teaching partner" that automates the entire grading loop—from assignment upload to detailed analysis.
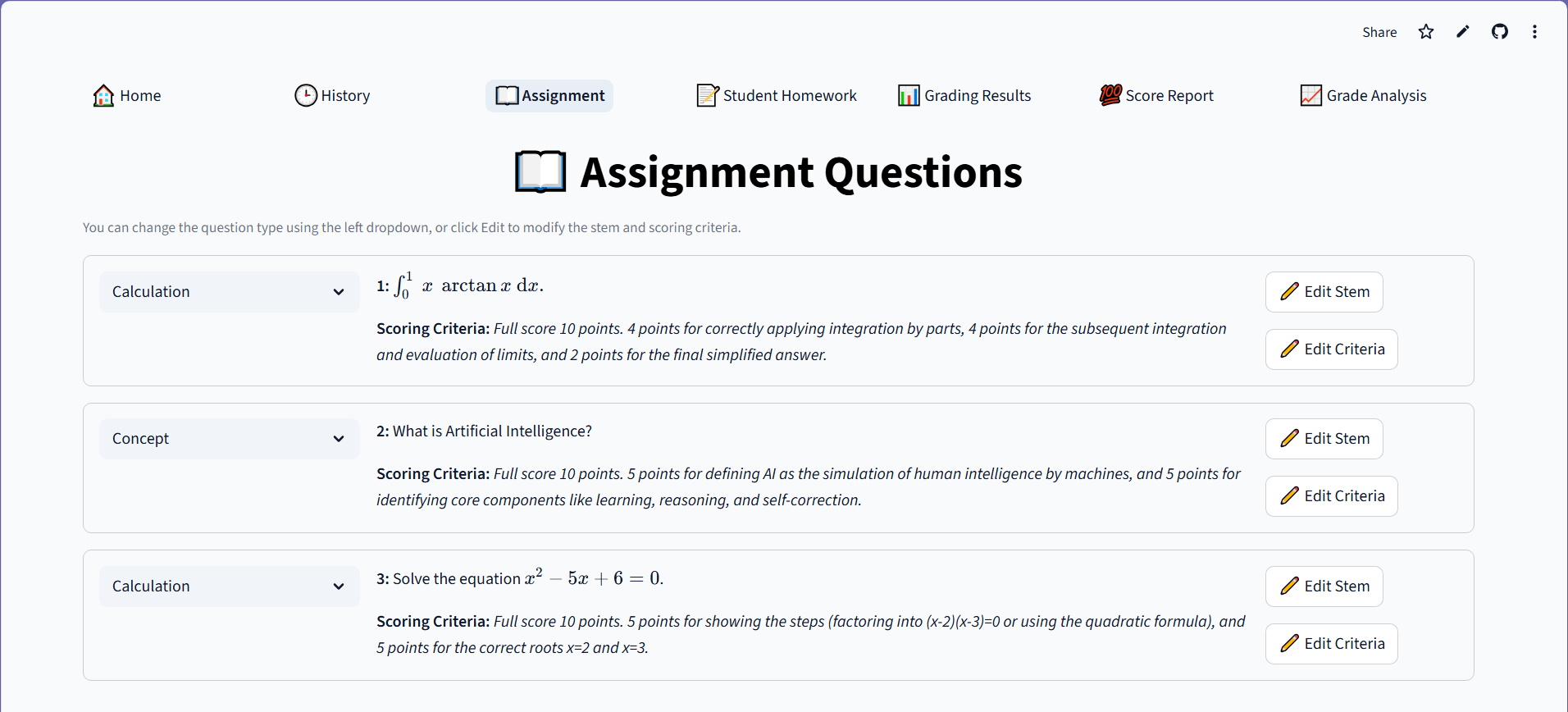
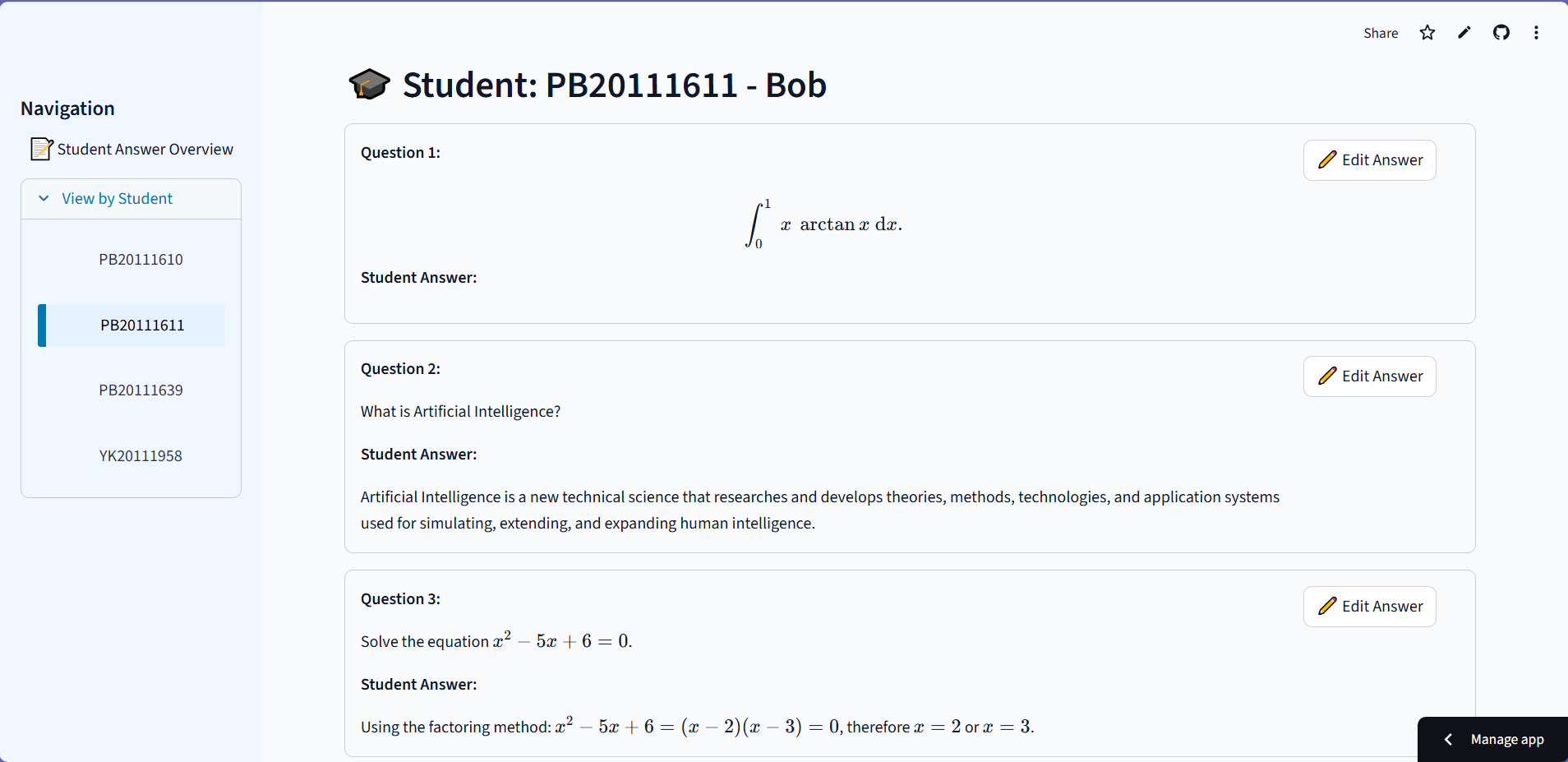
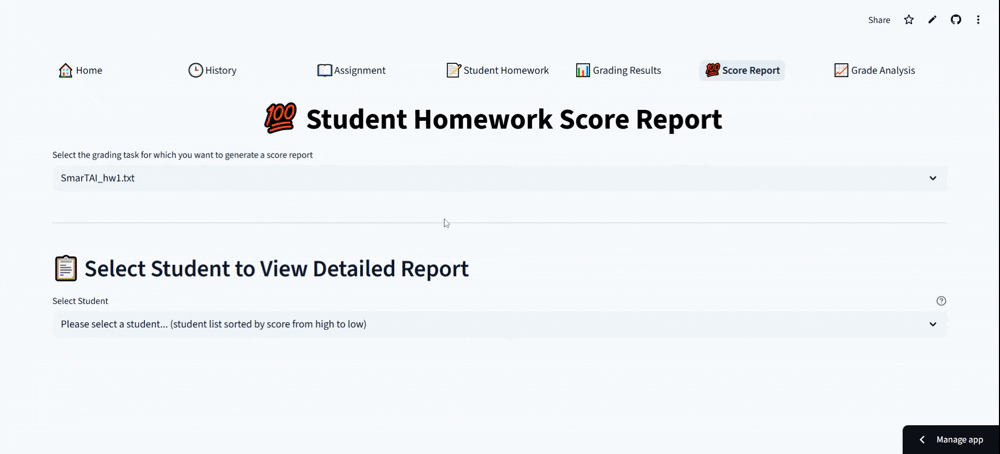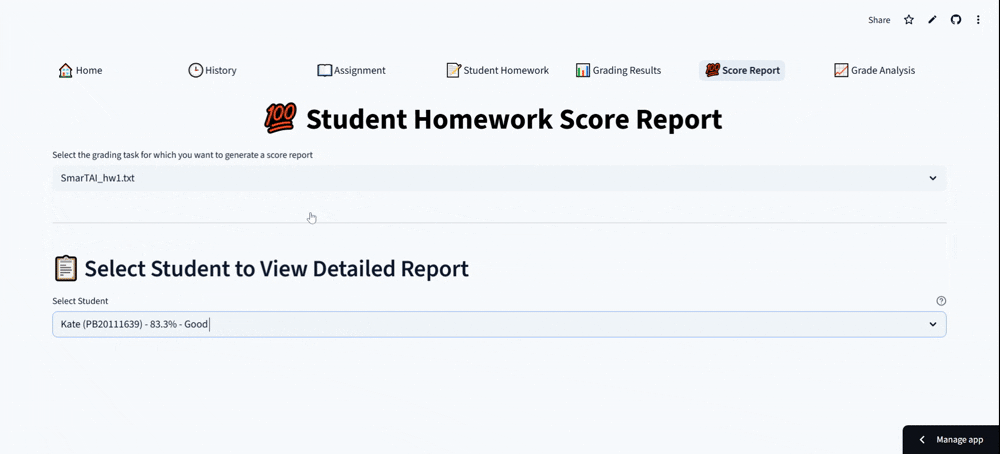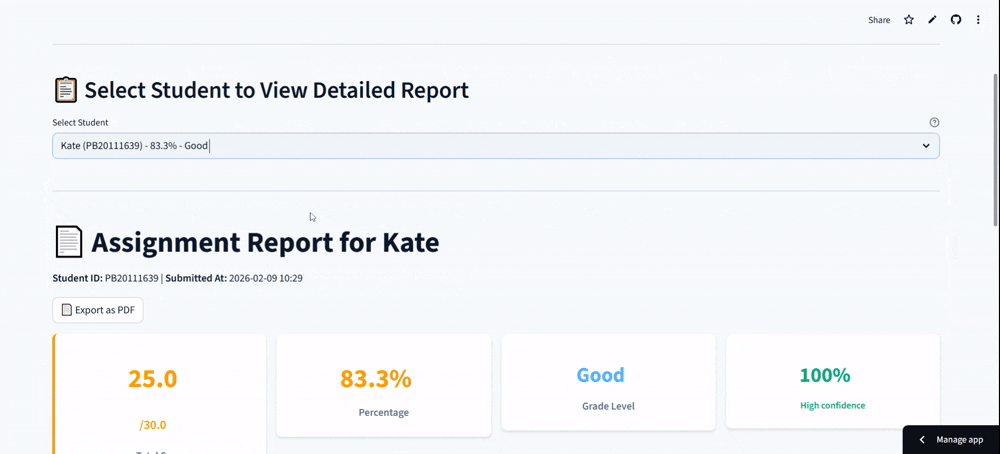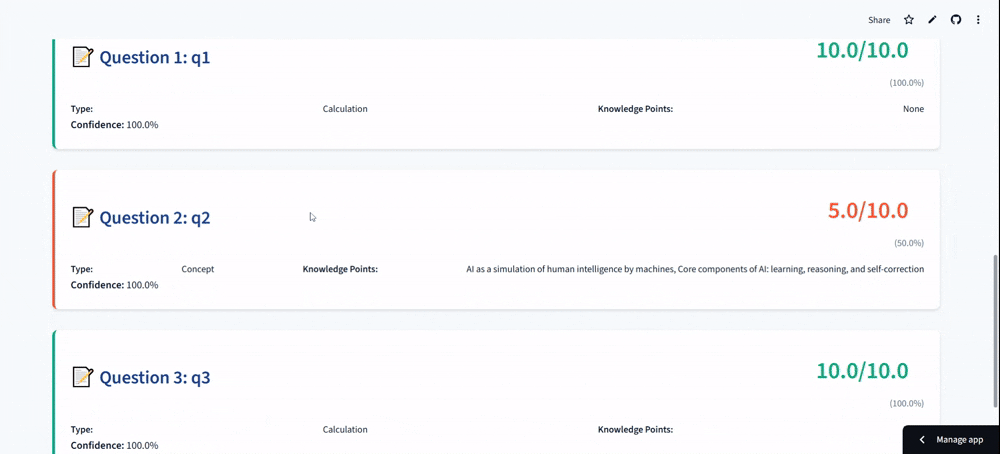
The system automatically parses homework into distinct sub-tasks—conceptual, calculation, proof, or programming—and routes them to specialized AI agents. For example, it doesn't just read code; it uses a Code Interpreter to execute student programs against test cases to verify robustness. For math problems, it employs a Numerical Engine to validate calculation steps and symbolic derivation, ensuring precision where pure LLMs often fail. Crucially, it incorporates a "Human-in-the-Loop" mechanism: if the AI's confidence score is low, it flags the specific question for human review, ensuring that efficiency never comes at the cost of accuracy.
What We Learned: The AI Opportunity
During our graduate studies across different institutions, we gained exposure to cutting-edge AI technologies while maintaining our connection to undergraduate education. We observed a critical gap:
While AI tools existed for simple assessments (multiple choice, basic math), none could handle the complex, open-ended problems characteristic of university-level STEM education.
This presented both a challenge and an opportunity. We hypothesized that by combining:
- Large Language Models (LLMs) for semantic understanding
- Specialized tools for numerical computation and code execution
- Pedagogical knowledge embedded in course materials
- Human oversight for quality control
We could create a system that didn't just automate grading, but actually enhanced the educational experience for both students and instructors.
How We Built SmarTAI: A Modular, Human-Centric Approach
Phase 1: Understanding the Problem Space
We began by systematically analyzing 300+ real homework submissions across courses in algorithms, numerical analysis, and systems programming. We identified patterns:
- Problem types followed consistent structures but required different evaluation strategies
- Common errors clustered around specific conceptual misunderstandings
- High-quality feedback needed to reference both correctness criteria and learning objectives
Phase 2: Architectural Design
Our system architecture emerged from these insights:
$$\text{SmarTAI} = \underbrace{\text{LLM Orchestration}}{\text{Reasoning}} + \underbrace{\text{Domain Tools}}{\text{Precision}} + \underbrace{\text{Knowledge Base}}{\text{Context}} + \underbrace{\text{Human Loop}}{\text{Oversight}}$$
Core Components:
- Multi-Expert LLM Ensemble: Different specialized models handle different question types
- Tool-Augmented Evaluation:
- Numerical engine for calculations: $f(x) = \int_a^b g(t)\,dt$
- Code interpreter for programming assignments
- Proof step verifier for logical derivations
- RAG-Enhanced Knowledge Base: Course materials, rubrics, and past examples inform scoring
- Confidence-Guided Human Review: Low-confidence evaluations trigger TA intervention
Phase 3: Implementation Journey
We chose LangChain and LangGraph for orchestrating our complex evaluation pipelines. The backend evolved through several iterations:
Initial: Single LLM + rule-based scoring
↓ (Accuracy issues with complex problems)
V2: Specialized models per question type
↓ (Inconsistent scoring across similar problems)
V3: Multi-Model consensus + external knowledge
↓ (Slow performance, high cost)
Current: Hybrid approach with early routing +
selective tool use + confidence-based batching
Each iteration was tested against ground-truth TA evaluations to measure both accuracy and educational value.
Challenges We Faced: Beyond Technical Hurdles
Challenge 1: The "Explanation Gap"
Early versions could identify errors but couldn't generate pedagogically useful explanations. A student who wrote $\lim_{x\to 0} \frac{\sin x}{x} = 0$ needed more than "incorrect"—they needed to understand why this was wrong and how to approach similar limits.
Solution: We developed a two-stage explanation system:
- Error detection using pattern matching and knowledge retrieval
- Explanation generation tailored to common misconceptions
Challenge 2: Fairness vs. Flexibility
Engineering problems often have multiple valid solutions. How do we reward creativity while maintaining consistent standards?
Solution: We implemented rubric-based scoring with solution space mapping. Instead of comparing to a single "correct answer," the system:
- Identifies the solution strategy used
- Applies the appropriate sub-rubric
- Checks for logical consistency within that approach
Challenge 3: Scalability with Quality
As we expanded from 50 to 500+ concurrent submissions, latency increased dramatically while accuracy decreased.
Solution: Our current architecture uses:
- Hierarchical evaluation: Quick correctness check → detailed feedback only when needed
- Caching of common patterns: Similar errors across students trigger pre-computed explanations
- Parallel processing pipelines: Different question types evaluated simultaneously
Accomplishments that we're proud of
We are particularly proud of engineering a Multi-Expert Collaboration System that goes beyond simple prompting. Instead of relying on a single generalist model, we built an architecture where specialized agents—dedicated to proofs, coding, or calculations—work in tandem. This ensures that a complex calculus problem is handled differently from a Python programming task, mirroring the specialized knowledge of a human teaching team.
Technically, we conquered the instability of LLMs in STEM by integrating deterministic tools directly into our LangGraph workflow. We coupled the AI with a Numerical Engine and Code Interpreter. This means SmarTAI doesn't just "guess" the result of an integral or a script; it actually calculates and executes it to verify correctness, solving the hallucination problem common in math problems.
In our pilot testing with real student data, this architecture achieved a 12x increase in grading efficiency, processing complex problem sets in under 5 minutes that previously took TAs over an hour. We successfully balanced this automation with a "Human-in-the-Loop" safety net, ensuring that low-confidence results are automatically flagged for human review rather than failing silently.
The Impact: More Than Just Time Savings
After deploying pilot versions in three university courses, we observed:
- TA time reduction: 70-85% decrease in grading hours
- Feedback timeliness: Students received detailed feedback within minutes instead of days
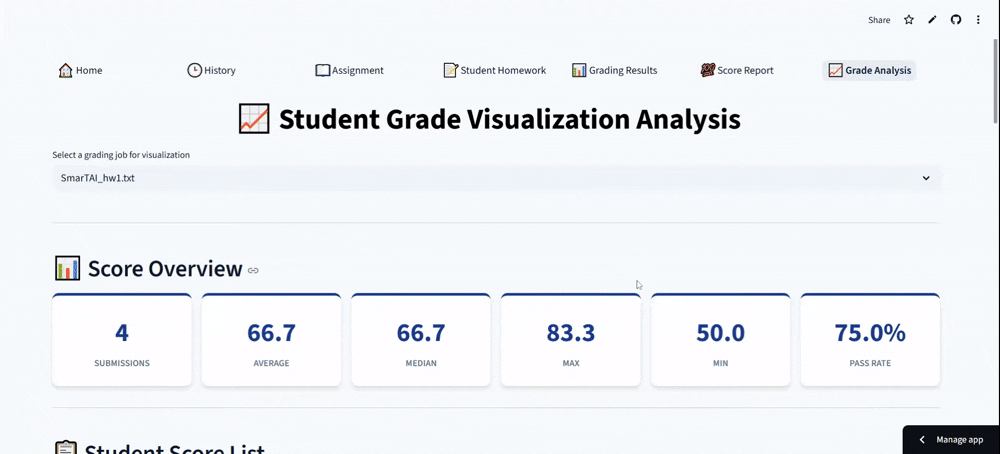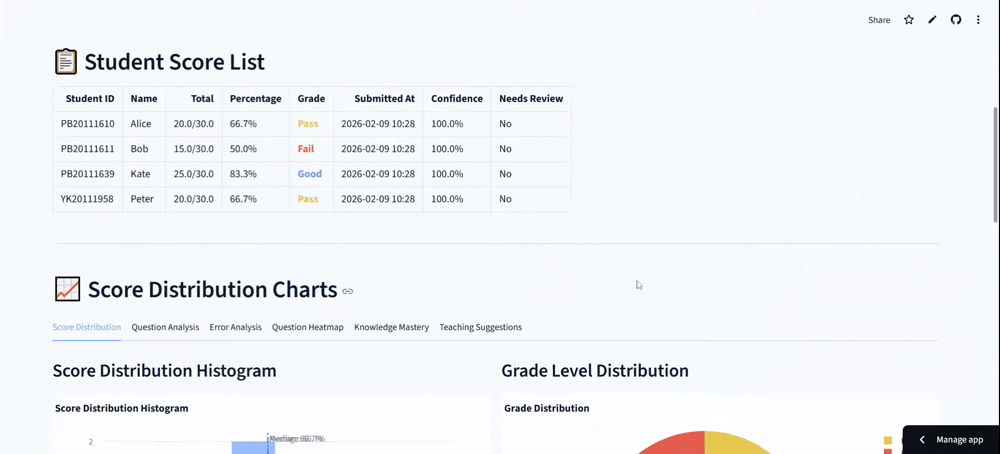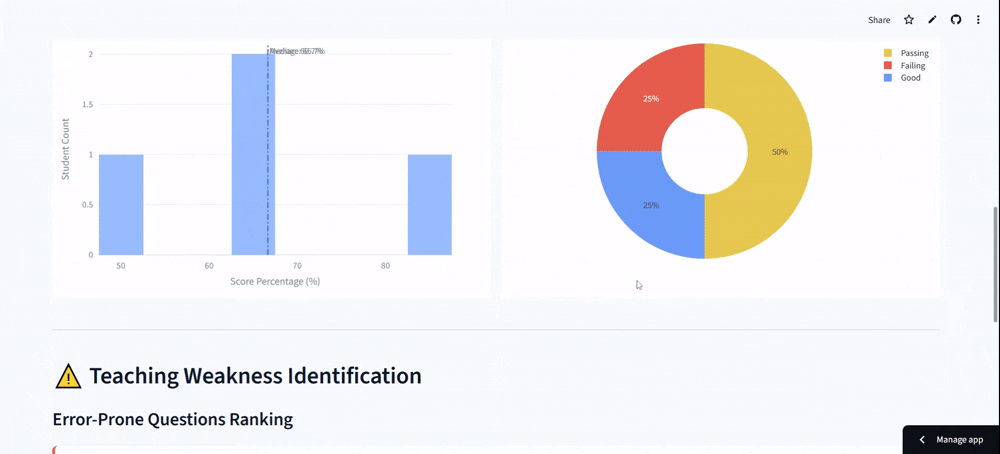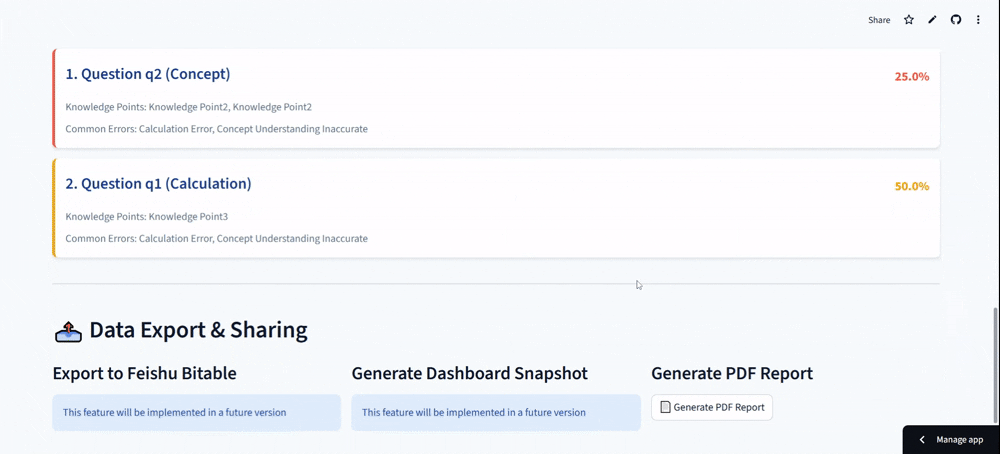
- Consistency improvement: Scoring variance decreased from 15% to under 3%
- Learning outcomes: Early data suggests improved performance on subsequent assessments
Perhaps most importantly, TAs reported shifting from mechanical grading to meaningful student interactions—exactly the outcome we had hoped for.
What's next for SmarTAI
Our immediate roadmap focuses on flexibility and deeper integration. We are working on multi-modal support, specifically integrating OCR to accurately parse handwritten formulas and scanned PDFs, a critical feature for digitizing traditional exams.
We also plan to open up our model ecosystem, allowing users to "Bring Your Own Key" (BYOK) and select different LLMs for different tasks to balance cost and performance. Finally, we aim to integrate with collaborative platforms, transforming our current snapshot analysis into a longitudinal tracking system that visualizes student growth curves over an entire semester.
Looking Forward: The Future of AI in Education
SmarTAI represents our vision for augmented education—not replacing human instructors, but amplifying their impact. As we continue developing, we're exploring:
- Personalized learning pathways based on error patterns
- Cross-course knowledge transfer to identify foundational gaps
- Multi-modal input support for diagrams, handwritten work, and oral explanations
The journey from frustrated TAs to AI education innovators has taught us that technology serves education best when it understands the human context first. Our shared experience in the classroom wasn't just the inspiration for SmarTAI—it remains the compass guiding every technical decision we make.
Built With
- fastapi
- gemini3
- langchain
- python
- render
- streamlit


Log in or sign up for Devpost to join the conversation.