-
-
AGLC4 - smart citation for Australian lawyers
Project Story
What Inspired This Project
As someone who has witnessed the painstaking process of legal research and citation formatting, I was inspired to create a solution that could eliminate one of the most tedious aspects of legal writing. Legal professionals spend countless hours ensuring their citations conform to the Australian Guide to Legal Citation, 4th Edition (AGLC4) standards – time that could be better spent on substantive legal analysis.
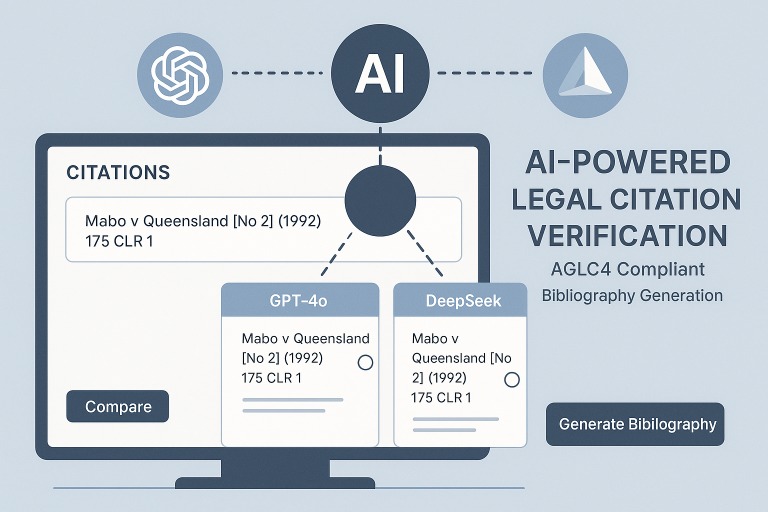
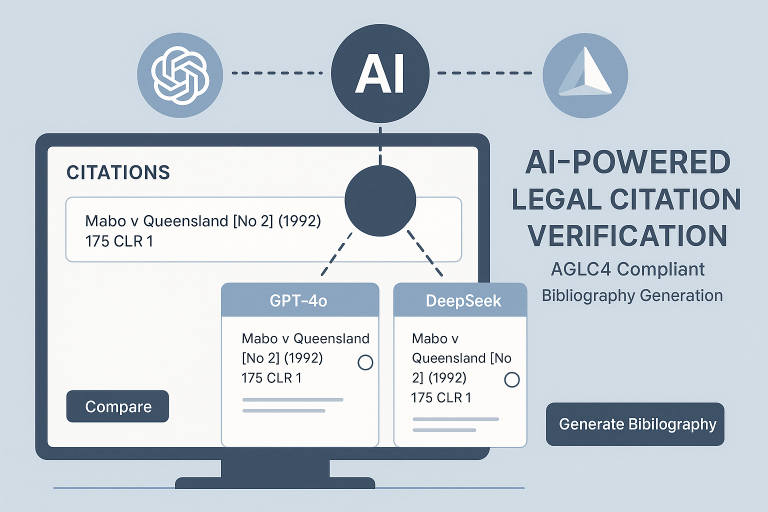
The inspiration struck when I realized that modern AI technology could not only automate this process but also provide dual verification to ensure accuracy. The idea of combining OpenAI's GPT-4o-mini with DeepSeek's models to create a cross-verification system seemed like the perfect way to build trust in an AI-powered legal tool.
What I Learned
This project became a masterclass in several key areas:
AI Integration & Prompt Engineering: I discovered that getting consistent, accurate legal citation formatting from AI models requires incredibly detailed system prompts. Legal citations have nuanced rules that vary by jurisdiction, court level, and citation type. I learned to craft prompts that could handle edge cases like pinpoint references, neutral citations, and the subtle differences between footnote and bibliography formatting.
Dual AI Verification: Implementing a system that processes citations through two different AI models taught me about the importance of redundancy in AI applications. Each model has its strengths – OpenAI excels at understanding context while DeepSeek often catches formatting details that OpenAI might miss.
Rich Text Processing: Working with HTML content from Word documents and PDFs taught me about the complexities of preserving formatting while cleaning unwanted markup. Legal documents often contain italicized case names and legislation titles that must be preserved through the processing pipeline.
State Management at Scale: Managing the complex state of multiple citations in various processing stages (pending, processing, completed, error) while maintaining user selections for bibliography generation required careful architecture planning.
How I Built This Project
Technology Stack Selection: I chose React with TypeScript for type safety, Tailwind CSS for rapid UI development, and Vite for fast development iteration. The decision to use React Quill for rich text editing was crucial for preserving formatting from legal documents.
Architecture Decisions:
- Context-based State Management: Used React Context with useReducer for predictable state updates across the complex citation processing workflow
- Service Layer Pattern: Separated AI API calls and file processing into dedicated service classes for maintainability
- Component Composition: Built modular components that could be easily hidden or shown based on feature requirements
AI Service Implementation: The core challenge was creating a robust AI service that could:
- Handle rate limiting and retry logic with exponential backoff
- Parse various response formats from different AI models
- Provide fallback mechanisms when one service fails
- Generate comprehensive bibliographies from selected citations
User Experience Focus: Designed the interface to clearly show the comparison between AI outputs, allowing users to make informed decisions about which version to use for their bibliography.
Challenges I Faced
AI Response Consistency: The biggest challenge was ensuring both AI models returned properly formatted JSON responses. AI models sometimes wrap responses in code blocks, include extra text, or format JSON inconsistently. I had to build robust parsing logic that could extract valid data from various response formats.
Citation Complexity: Legal citations are incredibly complex with jurisdiction-specific rules, multiple citation formats (reported vs unreported cases, neutral citations), and subtle punctuation requirements. Creating system prompts that could handle this complexity while maintaining consistency was challenging.
Rich Text Processing: Handling HTML content from Word documents required careful sanitization to remove Word-specific markup while preserving essential formatting like italics for case names and legislation titles.
Error Handling & User Feedback: Building a system that gracefully handles API failures, rate limits, and parsing errors while providing meaningful feedback to users required extensive error handling and user experience considerations.
Performance Optimization: Processing multiple citations through two AI services could be slow. I implemented parallel processing where possible and added comprehensive progress indicators to keep users informed.
State Synchronization: Managing the complex state where users can select different AI versions for each citation, delete citations, and generate bibliographies required careful state management to prevent inconsistencies.
Technical Achievements
- Dual AI Verification System: Successfully integrated two different AI APIs with cross-verification capabilities
- Rich Text Preservation: Built a system that maintains legal formatting (italics, punctuation) through the entire processing pipeline
- Robust Error Handling: Implemented comprehensive retry logic and graceful degradation for API failures
- Production-Ready UI: Created a professional interface suitable for legal professionals with clear visual feedback and intuitive controls
- Scalable Architecture: Built with modular components and services that can be easily extended or modified
This project taught me that building AI-powered tools for professional use requires not just technical implementation, but deep understanding of the domain, careful attention to edge cases, and robust error handling to build user trust.

Log in or sign up for Devpost to join the conversation.