-

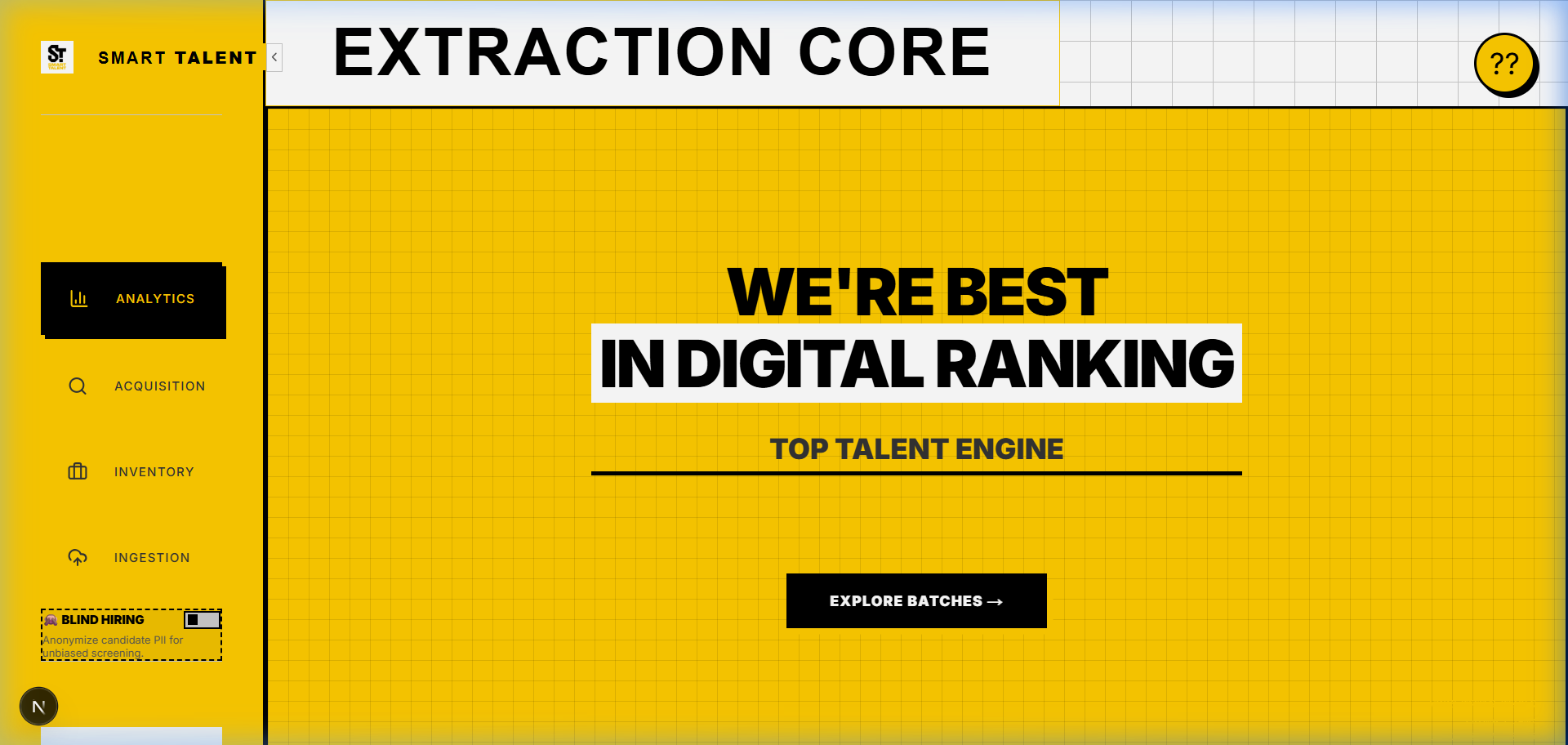
Command center mapping recruitment data: real-time telemetry, AI parsing throughput, active Celery workers, and candidate insights.
-

Bulk ingestion portal processing PDF, DOCX & images via spatial parsing & OCR, scaling infinitely with async Celery background tasks.
-

Built-in RAG AI Agent instantly queries the pgvector database, summarizing complex talent profiles & finding exact matches via chat.
-

Active pipeline hub with Explainable AI (XAI). Ranks candidates via 1536-dim vector similarity while enforcing PII-redacted blind hiring.



Inspiration 💡
The global hiring infrastructure is fundamentally broken; it acts as a filter of exclusion, not an engine of discovery. In modern Talent Acquisition, a single job post attracts over 1,000 applicants. To cope, recruiters rely on primitive Applicant Tracking Systems (ATS) that use exact-character keyword matching.
This creates catastrophic failure points. A brilliant engineer who writes "JVM Expert" is auto-rejected if the JD asks for "Java." Candidates are forced into "keyword stuffing," while recruiters suffer from 6-second fatigue, leading to massive unconscious bias. We realized that current tools match characters, whereas human recruiters look for meaning. This inspired us to build the Smart Talent Selection Engine—a deeply technical, AI-powered semantic recruitment infrastructure designed to replace keyword fragility with intent intelligence and fairness.
What it does 🚀
The Smart Talent Engine is a holistic, automated pipeline that democratizes the screening process:
- Spatial Multi-Format Ingestion: Ingests PDFs, DOCX, and scanned images, reading them spatially to understand complex column layouts.
- Bias-Free Profiling (Blind Hiring): Automatically scrubs Personally Identifiable Information (PII) like names, emails, and locations before AI evaluation to ensure purely merit-based screening.
- Semantic Understanding: Converts unstructured resumes into standardized JSON profiles, mapping over 120+ synonym aliases (e.g., "K8s" → "Kubernetes") to our canonical skill taxonomy.
- Explainable Ranking (XAI): Instead of a black-box "95% Match", candidates are scored using a deterministic Multi-Factor Algorithm, accompanied by a human-readable justification detailing exactly why they fit the role.
How we built it ⚙️
We engineered a Stateless Modular Monolith designed for extreme burst traffic.
- The Core Backend: Built with FastAPI (Python 3.11). To prevent the LLM context window from becoming an asynchronous bottleneck, we implemented a distributed task queue using Celery and Redis to process thousands of resumes simultaneously in the background.
- The Frontend: A highly responsive, brutalist-inspired UI built with Next.js (React 19), communicating via REST and Server-Sent Events (SSE) for real-time telemetry.
- Data & Intelligence: We utilized PyMuPDF for XY-coordinate spatial mapping, Tesseract OCR for computer vision, and Microsoft Presidio & spaCy for PII redaction. We utilized OpenAI's GPT-4o for structured profiling.
The Semantic Ranking Algorithm (Powered by Math)
Rather than spinning up an expensive, bloated vector database, we embedded both the Job Description (JD) and Resume (R) profiles into 1536-dimensional hyper-space using text-embedding-3-small and stored them in PostgreSQL 16 with pgvector. We compute cosine similarity natively using IVFFlat indexing.
Our proprietary matching algorithm evaluates candidates across four heuristic priorities:
$$ \mathcal{S}{total}(R, J) = \alpha \left( \frac{\vec{v}{J} \cdot \vec{v}{R}}{|\vec{v}{J}| |\vec{v}{R}|} \right) + \beta \left( \frac{| S_R \cap S_J |}{| S_J |} \right) + \gamma \cdot \Phi{exp}(R,J) + \delta \cdot \Phi_{certs}(R,J) $$
Where: $\alpha = 0.40$ (Semantic Vector Similarity), $\beta = 0.25$ (Canonical Skill Overlap), $\gamma = 0.25$ (Temporal Experience Alignment), and $\delta = 0.10$ (Verified Certifications).
Challenges we ran into 🧩
- The Multi-Column Layout Chaos: PDFs and resumes are unstructured data nightmares. Standard parsers frequently merge a left-hand "Skills" sidebar with main-body "Experience," destroying context. Engineering the coordinate-aware mapping system to rebuild logical reading flows was our toughest algorithmic hurdle.
- Eradicating AI Bias: Giving an LLM access to demographic data inadvertently pollutes the evaluation. We had to heavily tune our privacy middleware to guarantee zero PII leakage during the semantic profiling stage.
- API Rate Limiting & Concurrency: Pushing high-volume text to GPT-4o concurrently meant we immediately hit API tier limits. Implementing exponential backoffs, chunking strategies, and a robust Celery worker pipeline took massive iterative testing to stabilize.
Accomplishments that we're proud of 🏆
- Native Relational Vector Search: Proving that we could handle massive, high-dimensional AI data natively within an ACID-compliant Postgres database (
pgvector), completely bypassing the need for a standalone vector store. - True Explainability: We didn't just build a wrapper around an LLM; we built a system that mathematically forces the AI to justify its scores, bridging the trust gap for enterprise recruiters.
- Production-Ready Architecture: We built a fully Dockerized, asynchronous, horizontally scalable system that is ready to be deployed to the cloud today.
What we learned 🎓
We learned that Explainable AI (XAI) is the absolute prerequisite for adoption; users refuse to trust AI without a transparent "Why?". Technically, we discovered that the future of data parsing isn't just OCR, but spatial awareness. Finally, we proved that AI shouldn't just summarize data—it should structurally transform it to make human decision-making fairer, faster, and exponentially more accurate.
What's next for Smart talent selection engine 🚀
- Real-Time Interview Copilot: Integrating WebRTC to generate live, dynamic interview questions based on the gaps identified in the candidate's semantic profile.
- Predictive Retention Modeling: Correlating hiring data with long-term employee success metrics to predict candidate tenure.
- Enterprise ATS Integrations: Building native webhooks to seamlessly sync bidirectional data with platforms like Workday, Greenhouse, and Lever.

Log in or sign up for Devpost to join the conversation.