-
-
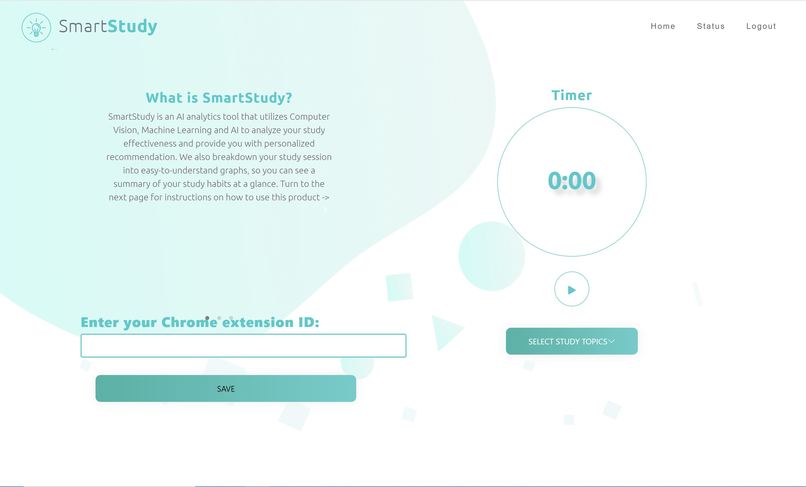
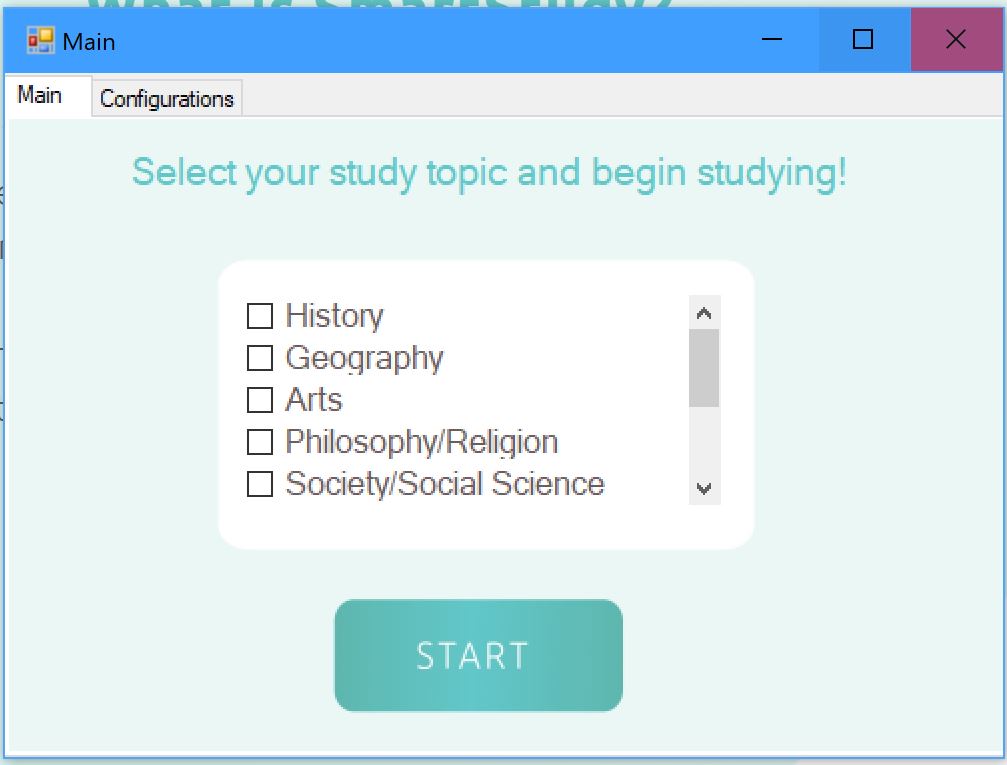
Homepage
-
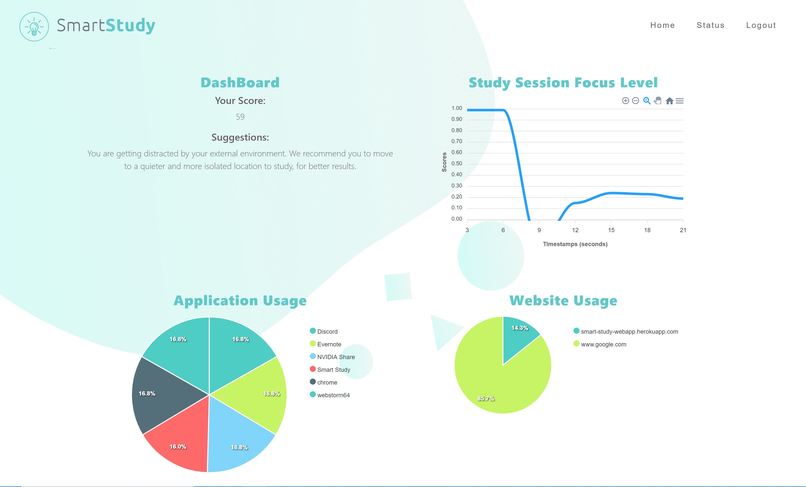
User data and breakdown
-
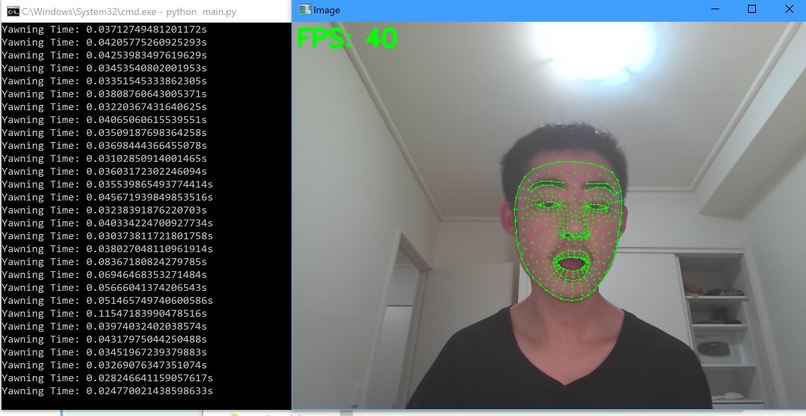
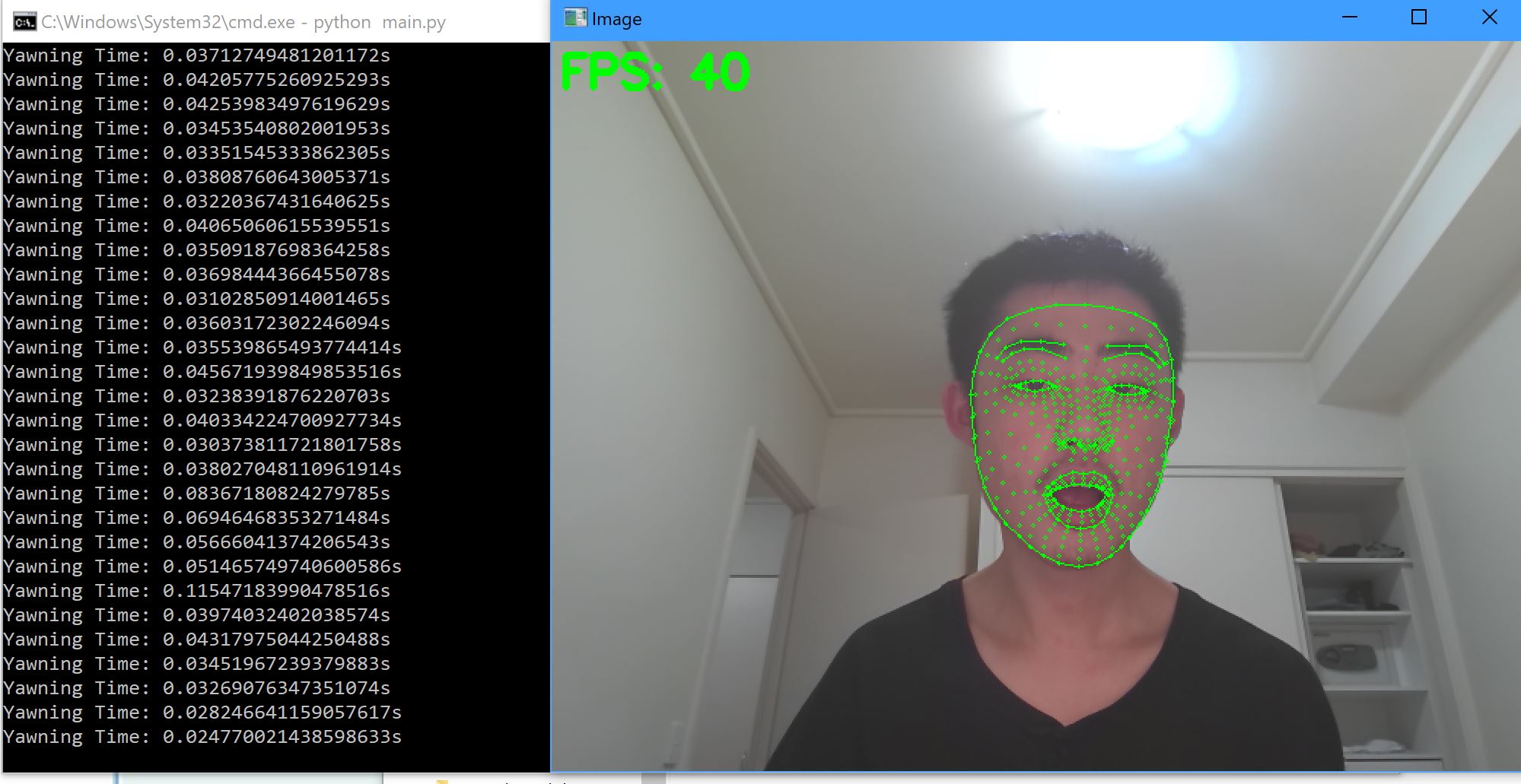
What the computer sees
-
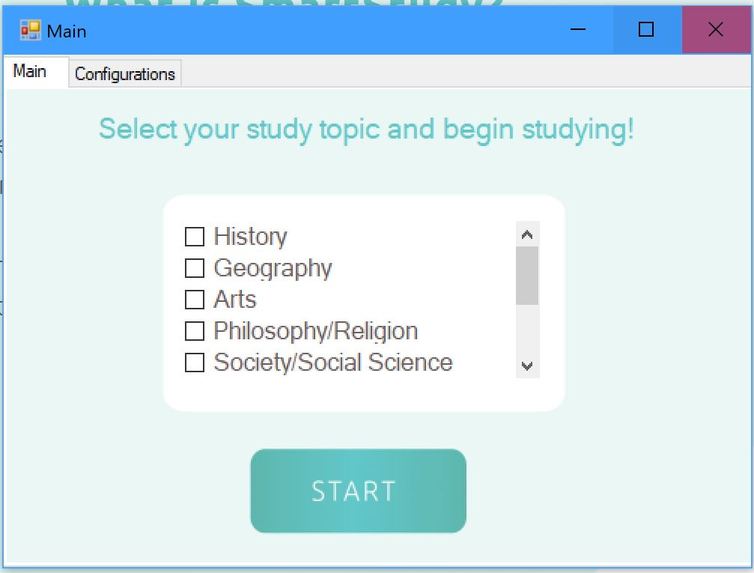
Desktop application


Inspiration
As master procrastinators ourselves, we believe procrastination is one of the biggest problems facing today’s students. Hence, we wanted to do something about it. We believe the first step to solving a problem is to identify it, and so we constructed a toolkit, SmartStudy, to identify signs of inefficient study through various means like examining facial expressions and analysing browsed websites and app usage. Utilising state-of-the-art tools from machine learning, like facial recognition, as well as a fully-from-scratch NLP semantic classification pipeline which solves a previously untackled problem, we overcame numerous technical challenges, ranging from learning react from scratch to sifting through 500MB of raw Wikipedia scraped data to produce this product, that we believe, can greatly improve a student’s educational experience.
What it does
SmartStudy is an AI analytics tool that can analyze your study effectiveness, and give personalized recommendation to help you improve your study habits. We take in your facial expression, website usage and app usage during your study session, and break the raw information down into easy-to-understand graphs you can easily view on our web-application. Our application is extremely intuitive to use, requiring minimal user configurations, and all the clients are synchronized together.
How we built it
SmartStudy can be separated into three components: Web component, desktop component and ML component.
The web component is built using React for the frontend, and Flask for the backend. We uses the OAuth 2.0 authentication workflow and OpenID Connect for user identification, in order to ensure the safety and integrity of our product. We also utilize various libraries, such as ApexCharts, in order to create interactive graphs and enhance the user experience. We also made a simple chrome extension, so that we can monitor web usage on Chrome browsers (unfortunately we did not have enough time to make a Firefox extension too).
The desktop component was built using C# and Python. The facial tracking aspect was created leveraging Open-CV and mediapipe, which tracks 461 points on your face (note that we do not store your facial information), to detect your facial expression. Using C#, we were able to build a user-friendly program that the user can use, and is well-integrated with the web component.
The machine learning component was built using Python. Utilizing the powerful NLTK library, a famous library for natural langauge processing, we were able to construct an algorithm that can classify a website's text. Our model is a logistic regression BOW (bag of words) model that also include several unique approaches such as "sliding window" and "sentence voting". Our model was trained on the wikipedia corpus, and was able to achieve 81% accuracy during benchmarks. You can find the full technical report on this part in a link below.
Challenges we ran into
ML is probably the most challenging and difficult component we had to tackle. As we had to ensure our algorithm is lightweight, which rules out various pre-trained models and heavy neural network, but also accurate. For these reasons, we decided to "homebrew" our own NLP algorithm. We had try out various approaches, benchmark them and eventually decided to use logistics regression as it performed the best. Sliding window and sentence voting was also something unique we implemented, taking inspiration from convolutions, a popular technique used for image classification in neural networks.
For our web components, we decided to use the OAuth 2.0 workflow, and integrating that with the front-end was definitely a challenge. After that, the challenge mostly came down to the best way to display the information on our web application, and we had to learn various libraries in order to create interactive charts. As the backend was the backbone of our entire project, it needs to be able to synchronize multiple components and "sew" everything together, so just simply getting each individual component to work together in harmony was another challenge in its own right.
Implementing the facial tracking was challenging, not so much in terms of the technology (as we do have some prior experience in CV), but adjusting the parameters of expression detection and finding ways to utilize those 461 datapoints to calculate what someone is currently doing. Mediapipe really opened a lot of possibilities, as it is able to work under poor conditions and is extremely accurate.
Accomplishments that we're proud of
As our project was quite ambitious, and with a limited timeframe, each person in our team was tasked with a huge workload, and we had to sacrifice certain things (e,g our sleep) in order to achieve what we achieved, so each and every single one in our team is very proud of that.
In addition, since each member in our team was working on completely separate components, it was quite difficult for us to integrate our components together. But in the end, through efficient communication, we managed to achieve a quality standard that we are comfortable with.
What we learned
Each member of our team learnt a lot of technologies in each of our respective fields. Every single one of us had to learn new frameworks and/or libraries on the go, which was definitely beneficial for us as we now have more experience in different libraries.
Apart from technical knowledge, we also learnt to be better collaborators and better communicators, or just in general better team members, which is a crucial skill both in school and in the workforce.
What's next for Smart Study
We believe that there is certainly a market for products like SmartStudy, and that many students would probably love to improve upon their study efficiency and reduce procrastination. After this hackathon, we would add more components (e.g a Firefox extension) that we did not have time to add in this hackathon, polish up a few rough edges, and hopefully deploy this project into the real world.


Log in or sign up for Devpost to join the conversation.