
Inspiration
Podcasts have exploded in popularity, but discovering the right episodes remains a frustrating experience. With thousands of hours of content uploaded daily across YouTube and Spotify, finding episodes that match your specific interests feels like searching for a needle in a haystack. Most recommendation systems rely on surface-level metadata like titles and tags, missing the actual substance of what's discussed.
I wanted to build something smarter — an AI system that doesn't just look at titles, but actually reads the transcript of each episode to understand what was truly discussed. The idea was simple: what if you could tell an AI "I'm interested in distributed systems and AI agents" and it would analyze an entire podcast channel, read the transcripts, and tell you exactly which episodes to watch and why?
What it does
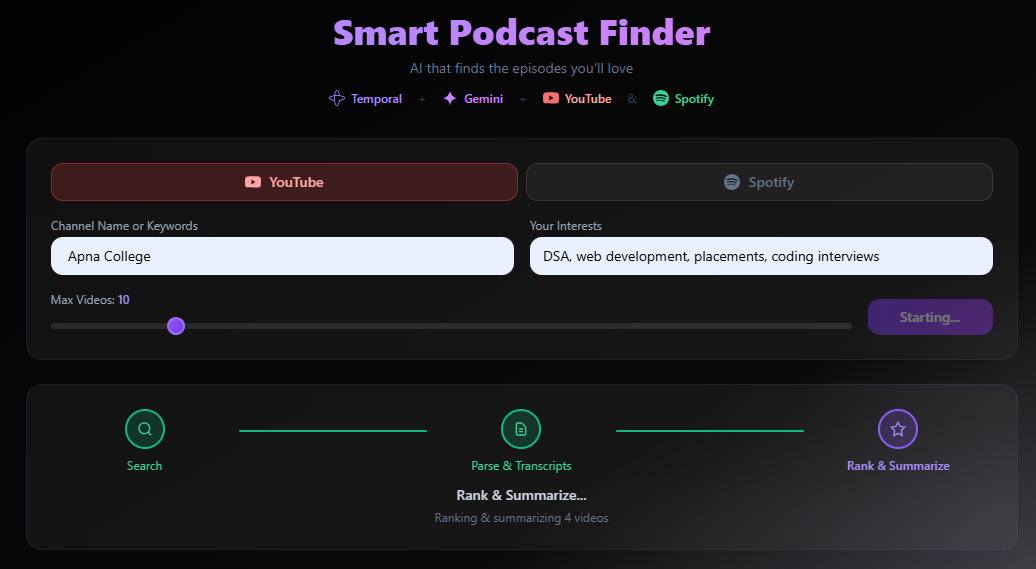
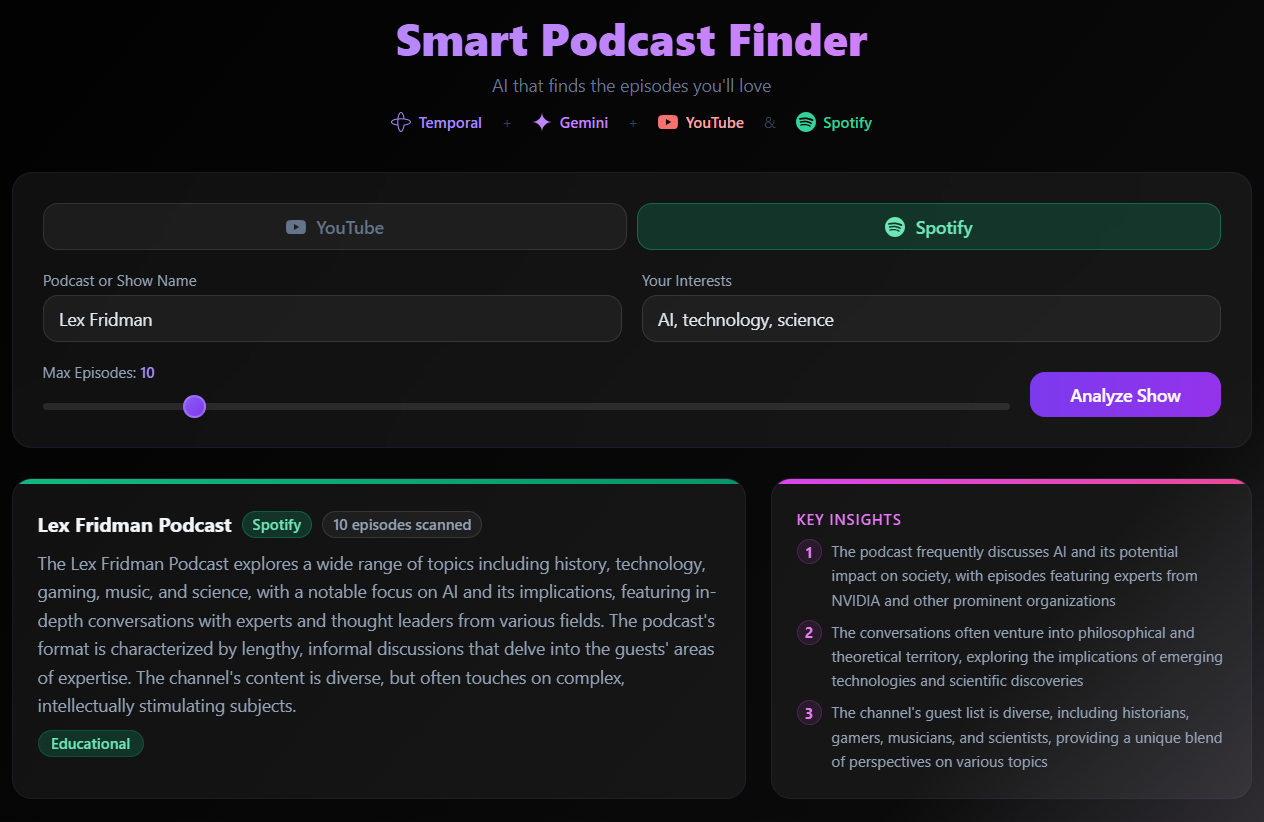
Smart Podcast Finder is an AI-powered podcast discovery platform that analyzes YouTube channels and Spotify shows to deliver personalized episode recommendations based on your interests.
Here's what happens when you use it:
- You enter a channel name and your interests — for example, "Lex Fridman" and "artificial intelligence, consciousness"
- The AI searches and fetches podcast-length videos (10+ minutes) from that channel
- Real transcripts are pulled from YouTube to understand what was actually said in each episode
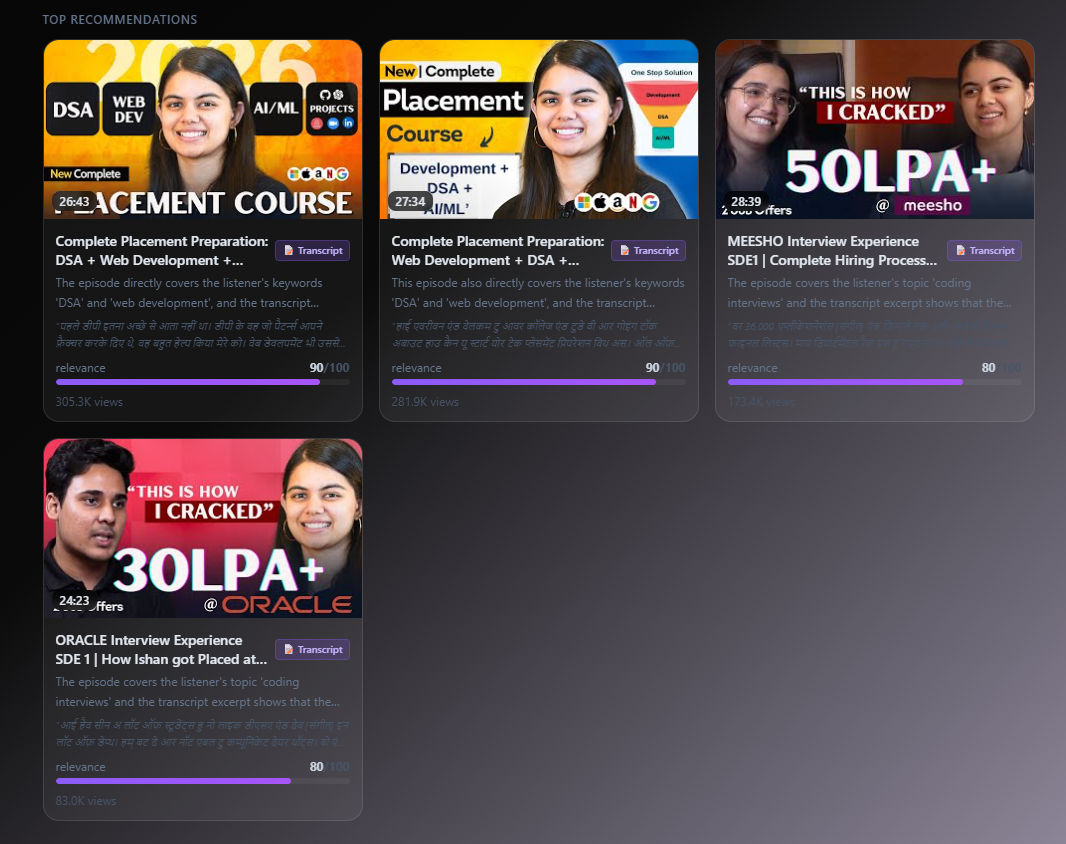
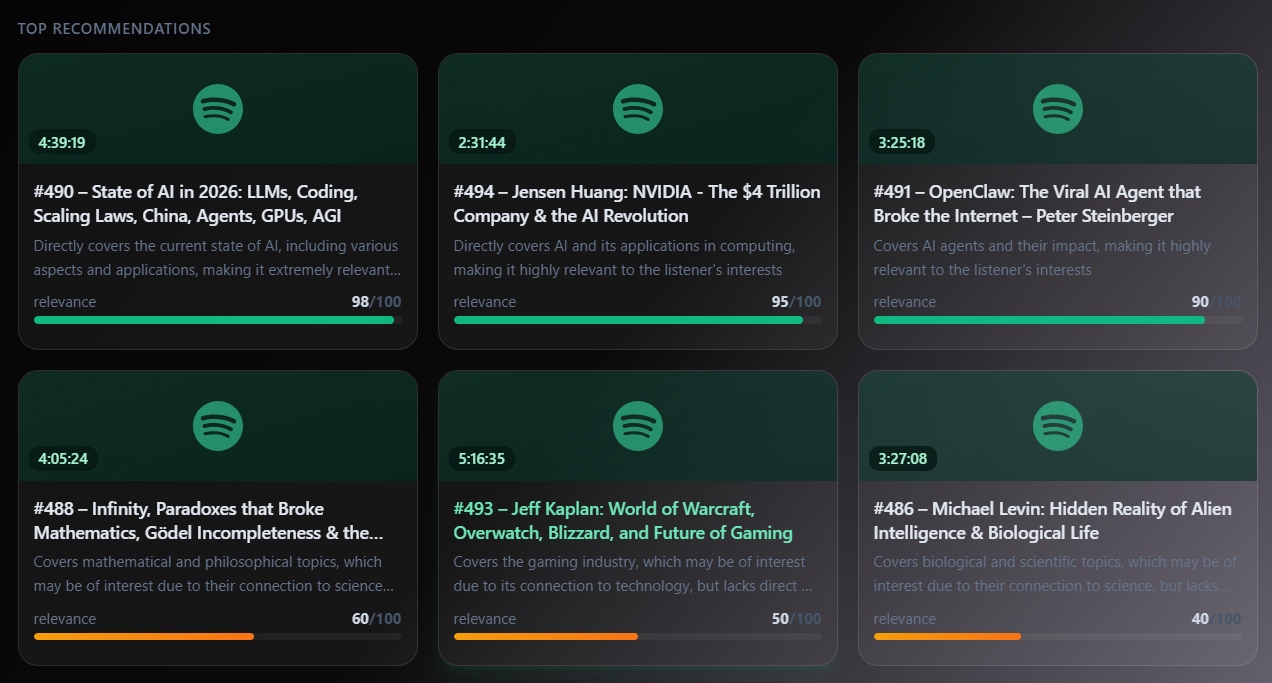
- Every episode is scored 0-100 based on how relevant it is to your interests, using transcript data, tags, chapters, and metadata
- A channel summary is generated with key insights and content tone analysis
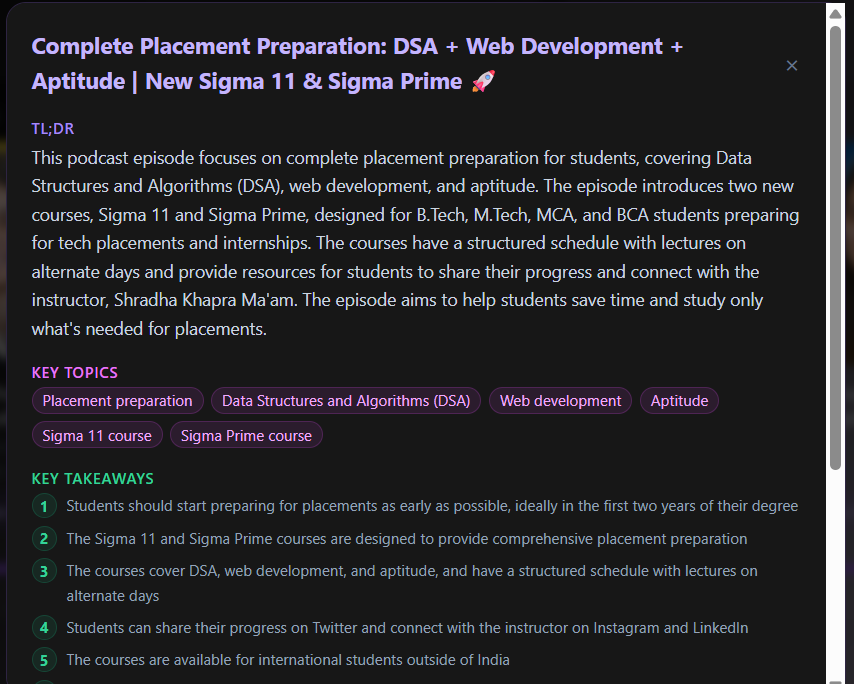
- Episode Deep Dive — click any episode to get a detailed AI breakdown including TL;DR, key takeaways, notable quotes, episode timeline, and tools mentioned
The entire pipeline is durable — if any step fails (API timeout, rate limit), it automatically retries without losing progress.
How we built it
The architecture combines four key technologies:
- Temporal for workflow orchestration — each step (search, parse, transcript fetch, rank, summarize) runs as a durable activity with automatic retries and full observability. The pipeline runs stages in parallel where possible for speed.
- AWS Bedrock with Llama 3.3 70B as the LLM backbone — handles interest parsing, video ranking with structured scoring, channel summarization, and episode deep dive analysis. We chose Bedrock for its reliability and no rate-limit constraints.
- FastAPI for the REST API layer — clean endpoints with Swagger documentation, real-time status polling, and Pydantic validation throughout.
- YouTube Transcript API for fetching real spoken content from videos — this is the secret sauce that makes recommendations significantly more accurate than metadata-only approaches.
The frontend is a single-page app built with Tailwind CSS and vanilla JavaScript, featuring real-time pipeline progress tracking, skeleton loading states, and an interactive deep dive modal.
The app is deployed on an AWS EC2 instance with an IAM role for Bedrock access, making the entire stack cloud-native.
Challenges we ran into
Temporal sandbox deadlocks — When we switched from Gemini to AWS Bedrock, the boto3 library's heavy imports triggered Temporal's 2-second deadlock detector inside the workflow sandbox. We solved this by relaxing the sandbox restrictions with passthrough modules.
Gemini API quota exhaustion — Our initial implementation used Google Gemini, but the free tier quota ran out quickly during testing. This pushed us to migrate to AWS Bedrock with Llama 3.3 70B, which turned out to be more reliable with no hard rate limits.
Transcript availability — Not all YouTube videos have transcripts, and some are in unexpected languages. We built a multi-layer fallback: try specific languages first, then any available language, and finally fall back to video metadata (title, description, tags) so the AI always has something to analyze.
LLM JSON parsing — Getting consistent JSON output from Llama required careful prompt engineering and a robust JSON extraction function that handles markdown code blocks and partial responses.
Accomplishments that we're proud of
Transcript-powered recommendations — Going beyond titles and tags to analyze what was actually said in each episode. This produces noticeably more accurate and relevant recommendations.
Episode Deep Dive feature — A single click generates a comprehensive AI analysis of any episode including TL;DR, key takeaways, notable quotes, episode timeline, and tools mentioned. This alone makes the app genuinely useful.
Durable execution — The entire pipeline is fault-tolerant. Network errors, API timeouts, and rate limits are handled automatically with retries. No data is ever lost mid-analysis.
Multi-provider support — Works with both YouTube and Spotify, and supports both AWS Bedrock and Google Gemini as LLM backends — configurable with a single environment variable.
Production deployment — The app is live on AWS EC2 with proper IAM roles, security groups, and a clean deployment workflow.
What we learned
Temporal is powerful for AI pipelines — Orchestrating multi-step LLM workflows with automatic retries and observability is a game-changer. Being able to see each activity's execution in the Temporal dashboard made debugging incredibly easy.
Transcripts are underutilized — Most podcast recommendation systems ignore the actual spoken content. Adding transcript analysis dramatically improved the quality of recommendations and made features like Episode Deep Dive possible.
LLM provider flexibility matters — Starting with Gemini and hitting quota limits taught us the importance of building provider-agnostic LLM integrations. Switching to Bedrock was straightforward because we abstracted the LLM layer early.
Prompt engineering for structured output — Getting reliable JSON from LLMs requires explicit format instructions, examples, and robust parsing on the application side.
What's next for Smart Podcast Finder
- Search history and favorites — Save past analyses so users can revisit recommendations without re-running the pipeline
- Multi-channel dashboard — Track multiple channels and get a unified feed of personalized recommendations
- Trending topics visualization — Word clouds and charts showing topic trends across channels over time
- Notification system — Get alerts when a channel posts new content matching your interests
- Caching layer — Add Redis/DynamoDB caching so repeated searches return instantly
- User authentication — Personal profiles with saved preferences and recommendation history
Built With
- api
- aws-bedrock
- aws-ec2
- boto3
- fastapi
- httpx
- javascript
- llama-3.3
- pydantic
- python
- spotify
- tailwind-css
- temporal
- transcript
- uvicorn
- youtube
- youtube-data-api

Log in or sign up for Devpost to join the conversation.