-
-
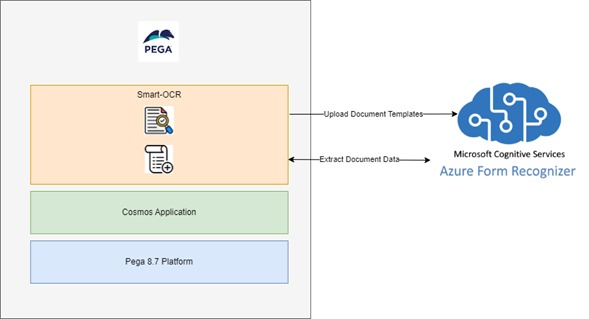
Figure 1: Pega Layer cake Architecture
-

Figure 2: Solution Architecture


Inspiration
“According to market research firm IDC, companies lose 20 to 30 percent in revenue every year due to inefficiencies. Document Validation is one of the critical problems that could lead to inefficiency”
Almost all businesses require collection of data from customers and most of the time these are collected via physical forms or other types of documents. The entry of this collected data into business systems is a monotonous task and requires very limited human expertise. To summarize the main challenges:
- Time intensive – Lower productivity and takes a lot of time to verify and enter data manually
- Data accuracy issues – Inaccuracy is one of the most difficult aspects of data entry
- Monotony – Effort is spent on repetitive and boring tasks when it could be spent on decision making tasks which require human expertise
Therefore, businesses can increase productivity and reduce costs by utilizing automated data extraction technologies such as OCR (Optical Character Recognition) within the data collection processes.
Our team has been able to provide an innovative, scalable, and extendable solution for such business scenarios by integrating capabilities of OCR within the Pega automation workflow.
For example, when users receive an electronic image of a brochure, PEGA application can use OCR to convert it into a fully editable format. But normally it takes time to make the process connecting with Azure and need to do more rework in PEGA to mapping and extracting data from the frozen text.
What it does
Thinking from the developer end, our main purpose is to build a user-friendly component to process a Smart-OCR process that developers can work easily in Pega and Azure with high accuracy and time effectiveness. Our main purpose is to make a more productive environment when developers are working in PEGA with Azure to process the OCR mechanism.
Implemented Smart-OCR application features:
- Providing the integration between PEGA application and Azure Form Recognizer
- Facilitating the Document training in Azure Form Recognizer by uploading the documents
- Providing a facility to map fields in Documents to Application
- Reusable design to use in any implementation.
How we built it
Smart-OCR application is built on top of PEGA 8.7 platform and using Microsoft Azure Form Recognizer services. Azure Form Recognizer resource is an automated data processing system that uses AI and OCR to quickly extract text and structure from documents.
Image 1 - Pega Layer cake Architecture of Smart-OCR application
Image 2 - High-level solution architecture of Smart-OCR application
Smart-OCR application provides below functionalities:
- Capability to train documents with a sample labeling tool in Azure.
- Extract any similar document data with trained models using Azure Form Recognizer services.
- Reusable activity which can be used to access extraction functionality from any other Pega application.
Solution Implementation
Two cases were implemented in Smart-OCR application
- “Train Document” case type – Using this case users can train sample document templates.
- “Client Onboarding” case type – This is a sample case type of applying Smart-OCR application’s data extraction functionality in real case scenarios.
Pre-requisites
- Create Form recognizer resource in Azure portal
- Create Storage account in Azure portal
- Create Container inside Storage account (One training document case needs one container/which means one document)
- Required at least five filled-in forms of the same type for training
Challenges we ran into
- First time users need to spend more time to investigate the integration process of Azure and PEGA application.
- Mapping is somewhat complex from the response from the Azure into PEGA application.
- If different templates available, then developers need more effort in going between PEGA application backend and Azure for training the document.
Accomplishments that we're proud of
Overall our accomplishments can be summarized as below:
- Save development time for integration between Azure / PEGA.
- Save time in property mapping for new documents.
- Save development time and research time.
- Prevent most of the human errors while integrating the OCR with PEGA
- In real-time business scenarios, human errors will be eliminated as we are automating data extraction from documents.
What we learned
We were able to get better understanding about Azure and how to work with the Optical Character Recognition (OCR) service provided by them. Furthermore, we identified how it can be integrated with a PEGA application to enhance its capabilities through the powerful automated workflow features of PEGA
What's next for Smart OCR
Smart-OCR can be integrated to any Pega application as a built-on application and able to access Smart-OCR functionalities.
In future releases, we are focusing on the below enhancements.
- Training documents within the Smart-OCR application itself without using an external Sample labeling tool.
- Create Azure storage account, container, and form recognizer resource from Smart-OCR application.
- Remove the current limitation of ten attribute labeling and provide unlimited attribute extraction.











Log in or sign up for Devpost to join the conversation.