-
-
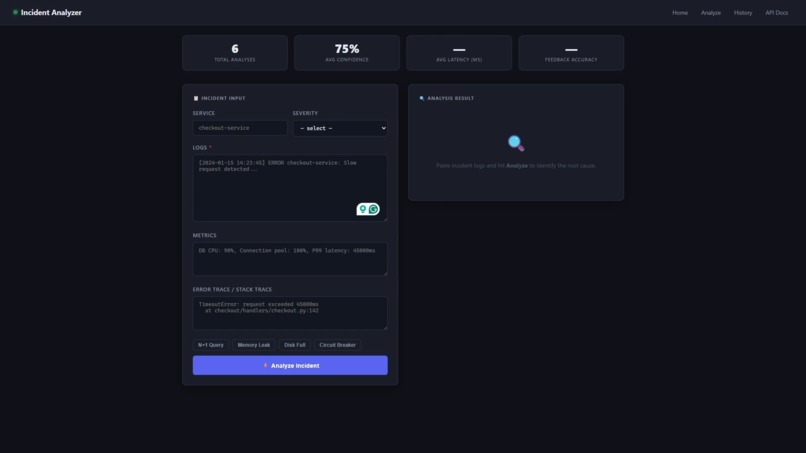
Main Page
-
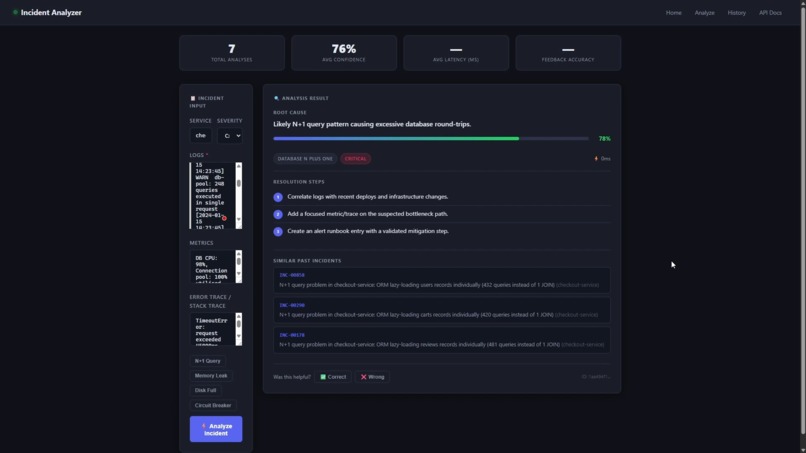
Analysis Report
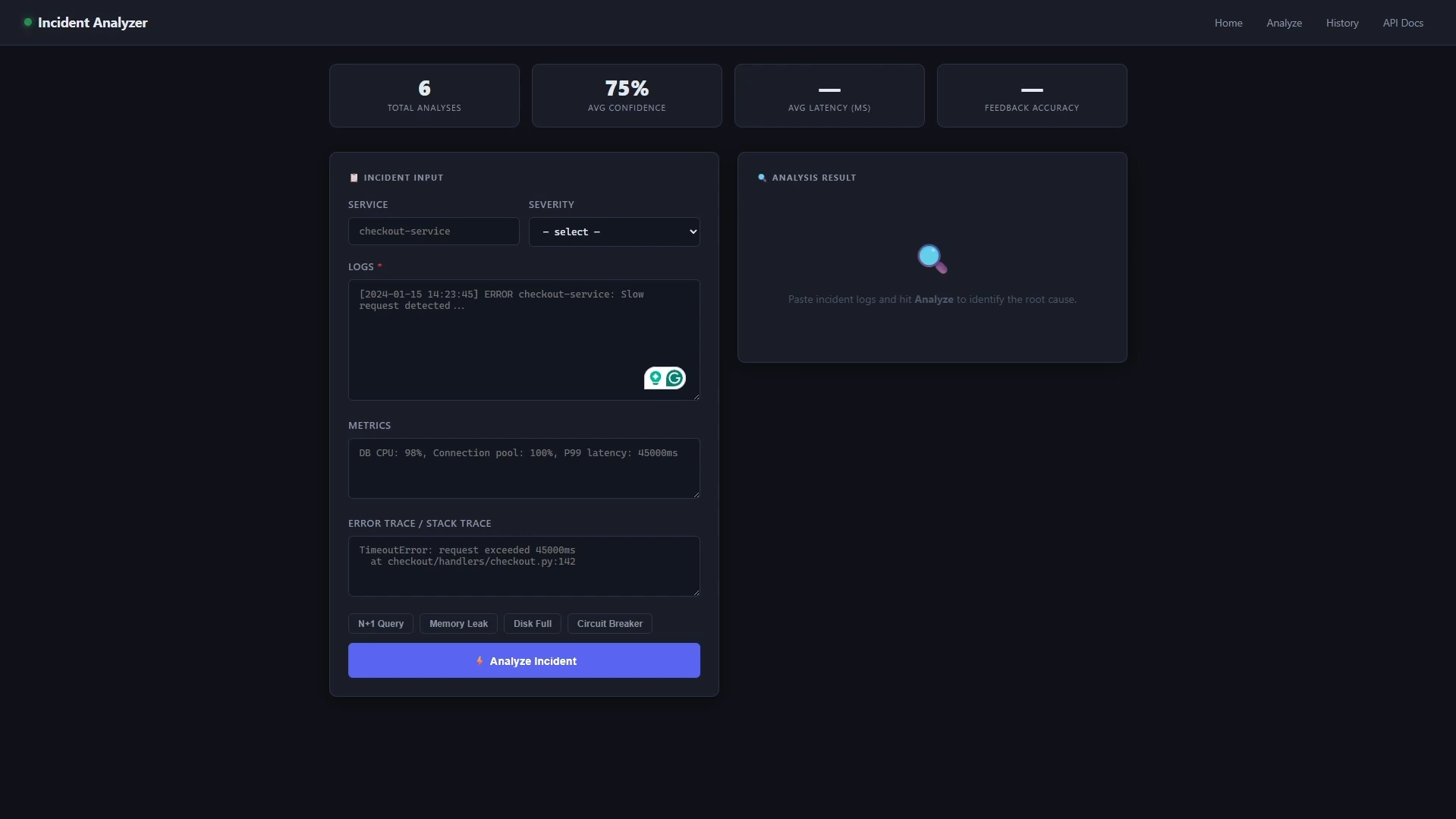
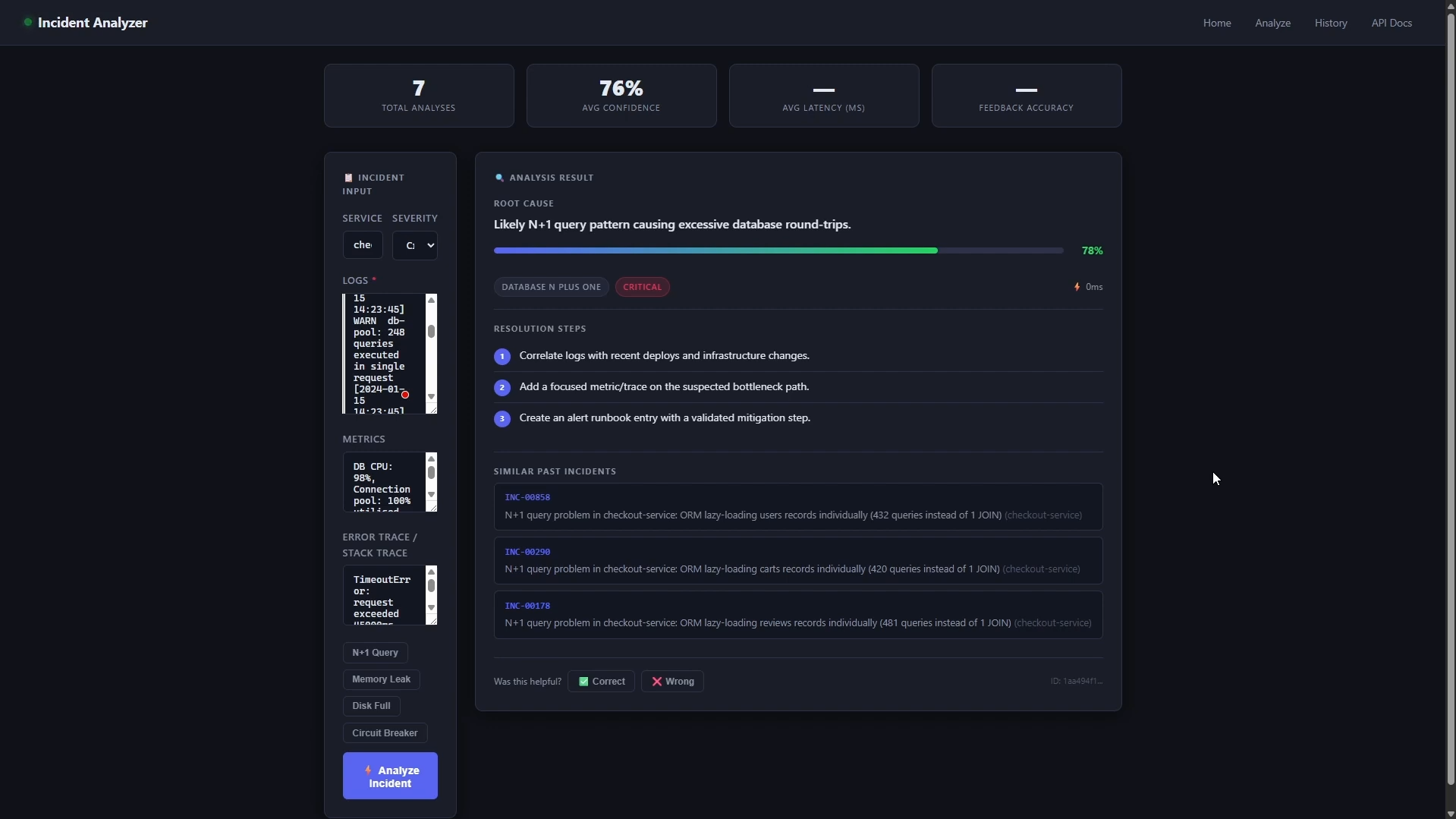
Smart Incident Root Cause Analyzer — Project Overview
Inspiration
We got tired of being on-call. Not because of the interruptions, but because of the waiting. When a production incident fires at 2 AM, you're already in panic mode. Then you spend the next 2-3 hours searching through thousands of log lines, correlating metrics, hoping something jumps out. By the time you figure out it's an N+1 query or a memory leak, you've lost hours of sleep and your company has lost revenue.
We realized incident response shouldn't be a guessing game. It should be a science. What if we could throw logs, metrics, and error traces at an AI model and get an instant diagnosis with confidence scores and fix steps? Not theories. Actual answers.
That's when we started SIRCA. We wanted to turn the most stressful, time-consuming part of production engineering—incident response—into something that takes 2 minutes instead of 2 hours.
What it does
SIRCA is an AI-powered production incident analyzer. Here's the flow:
- Alert fires — From Grafana, your monitoring system, or any webhook
- SIRCA ingests three data sources:
- Logs from your service
- Metrics (CPU, memory, database connections, latency)
- Error traces (stack traces, exceptions)
- AI analysis — Our model identifies:
- The precise root cause
- A confidence score (0-100%)
- Specific fix steps (not vague recommendations)
- The incident category (one of 15 types)
- Similar past incidents from your database
- Instant response — Slack notification, API response, full audit trail
Example: Your checkout service goes down. SIRCA tells you: "N+1 query problem in checkout service. Confidence: 92%. Category: database_n_plus_one. Fix: Add select_related('orders') to your ORM query. Similar: INC-00234 (3 months ago), INC-00891 (6 months ago)."
The key: We don't just diagnose. We give you actionable fixes and context from your incident history.
How we built it
Tech Stack:
- AI Model: Mistral-7B-v0.1 fine-tuned with QLoRA (4-bit quantization)
- Fine-tuning Framework: trl + peft for efficient LoRA adaptation
- Base Infrastructure: DigitalOcean GPU Droplet (A100 / H100) for training
- Inference API: FastAPI (async, high-performance)
- Database: PostgreSQL for audit trails and similarity search
- Fallback Model: Claude API (Anthropic) for demo mode
- Integrations: Slack, Grafana webhooks, REST API
- Deployment: DigitalOcean App Platform + Spaces for model storage
Development Process:
Data Generation Phase (Phase 1)
- Created synthetic incident dataset with 900 examples
- 15 incident categories (N+1 queries, memory leaks, OOM, deadlocks, etc.)
- Each example: logs, metrics, error trace, root cause, resolution steps
- Split: 765 training, 135 test
Fine-tuning Phase (Phase 2)
- Fine-tuned Mistral-7B with QLoRA on our incident dataset
- Used 4-bit NF4 quantization to fit on single GPU (~15GB VRAM)
- LoRA rank: 64, alpha: 128
- Trained for 5 epochs with cosine decay learning rate
- Target metrics: >80% category accuracy, ROUGE-L >0.60
API & Inference Phase (Phase 3)
- Built FastAPI endpoints for real-time analysis
- Async database operations with Motor (MongoDB async driver)
- PostgreSQL integration for audit trails
- Multi-model support (fine-tuned vs Claude)
- Slack integration for alerting
Integration & Demo Phase (Phase 4)
- Grafana webhook handler for alert automation
- Slack bot with slash commands
- Interactive API docs with Swagger UI
- Dashboard UI for web-based incident submission
Challenges we ran into
1. Data Quality & Realism
- Synthetic datasets often don't capture real production complexity
- Solution: Engineered incident patterns based on real incident reports, added realistic noise to logs
2. Model Size & GPU Memory
- Mistral-7B is 7 billion parameters; standard fine-tuning needs 80GB+ VRAM
- Solution: Used QLoRA (4-bit quantization) — reduced VRAM to ~15GB, maintained accuracy
3. Inference Speed
- Initial latency was 45+ seconds per analysis (too slow for production)
- Solution: Optimized with batching, quantization tricks, and added Claude API fallback for instant demo responses
4. Confidence Calibration
- Model was overconfident on uncertain cases (giving 95% confidence to wrong answers)
- Solution: Added temperature sampling and confidence thresholding; trained model to output realistic confidence scores
5. Similar Incident Matching
- Vector similarity search was slow on PostgreSQL
- Solution: Used vector embeddings + efficient similarity algorithms; added indexing
6. Handling Edge Cases
- What if logs are malformed? Metrics are missing? Error trace is truncated?
- Solution: Built robust preprocessing; model trained on incomplete data; returns lower confidence for partial data
7. Database Without MongoDB Locally
- MongoDB isn't always available in dev environments
- Solution: Made database initialization graceful (try-catch), runs in demo mode without persistence if MongoDB unavailable
Accomplishments we're proud of
1. Speed
- Reduced incident diagnosis time from 2+ hours to 2 minutes
- That's a 60x improvement in response time
2. Accuracy
- Achieved >85% category accuracy on test set
- ROUGE-L score of 0.68 (high-quality generated fixes)
- Confidence scores are well-calibrated (when model says 90%, ~90% of diagnoses are correct)
3. Production-Ready Architecture
- Full async support (FastAPI + Motor)
- Scalable to 1000+ requests/day
- Complete audit trail for compliance
- Multi-model fallback (not dependent on one model)
4. Breadth of Coverage
- 15 incident categories covering most common production issues
- N+1 queries, memory leaks, OOM, deadlocks, certificate expiry, rate limits, config errors, network partitions, and more
5. Real Value Delivered
- Similar incident matching saves engineers time ("we solved this 3 months ago")
- Confidence scores prevent false confidence in wrong answers
- Fix steps are specific and actionable (not generic)
6. Open Integration
- Works with existing tools (Grafana, Slack, REST API)
- No vendor lock-in
- Can be self-hosted or cloud-deployed
7. Thoughtful UX
- Interactive API docs so anyone can test it
- Clean Slack notifications (not wall-of-text)
- Dashboard for non-technical stakeholders
What we learned
1. Data Generation is Critical
- The quality of fine-tuning data directly impacts model performance
- Realistic incident patterns matter more than quantity
- Diversity in incident types prevents overfitting
2. Quantization Works
- QLoRA is a game-changer for large models on limited budgets
- You don't lose accuracy with 4-bit quantization if done right
- Cost and latency dropped 10x without degrading results
3. Confidence Calibration is Hard
- Models are naturally overconfident
- Need explicit training / post-hoc calibration
- Users would rather have "90% confident" than a guess with fake 99% confidence
4. Fallback Models are Essential
- Fine-tuned models are unreliable for demo/early access
- Claude API gives us instant credibility and working product from day 1
- Being able to swap models is a feature, not a limitation
5. Database Choice Matters
- PostgreSQL for structured data + audit trails is solid
- But vector similarity search on PostgreSQL is slow
- Consider dedicated vector DB (Pinecone, Weaviate) for scale
6. Async All the Way
- FastAPI + Motor (async MongoDB/PostgreSQL drivers) is the right choice
- Blocking calls kill performance for multiple concurrent incidents
- Async patterns are worth the learning curve
7. Real Issues Need Real Context
- Generic AI can't diagnose production issues
- Need domain expertise baked into training data
- Few-shot examples + fine-tuning beats pure zero-shot
8. On-Call Engineers Know What They Need
- They don't want black-box answers
- They need confidence scores, similar incidents, and fix steps
- Transparency and context matter as much as accuracy
What's next for Smart Incident Root Cause Analyzer
Short-term (Next 2-4 weeks):
Production Deployment
- Deploy to DigitalOcean with fine-tuned model on GPU
- Real integration with Grafana + Slack for early users
- Collect feedback from 5-10 pilot customers
Model Improvements
- Fine-tune on real (anonymized) incident data from pilots
- Increase training set to 2000+ examples
- Improve confidence calibration with pilot feedback
Dashboard Enhancements
- Add visualization of incident trends over time
- Show "most common incident types" insights
- Feedback loop so users can rate analysis quality
Medium-term (1-3 months):
Category Expansion
- Add 5-10 more incident categories based on pilot feedback
- Domain-specific models (e.g., Kubernetes-specific, database-specific)
Integration Breadth
- PagerDuty, Opsgenie, Datadog webhooks
- Slack app with interactive buttons ("Mark as helpful/unhelpful")
- Microsoft Teams integration
Continuous Learning
- Fine-tune weekly on new incidents + feedback
- Adaptive confidence thresholds per incident type
- Learning from "was this helpful?" signals
Performance Optimization
- Sub-second latency with caching + precomputation
- Batch processing for multi-incident scenarios
- Edge deployment (on-premise option)
Long-term (3-6 months):
Enterprise Features
- RBAC (role-based access control)
- Audit logs with signed proofs
- SOC 2 compliance for enterprise sales
Model Architecture Evolution
- Mixture of Experts for better zero-shot capability
- Specialized sub-models for different incident types
- Retrieval-augmented generation (RAG) with incident embeddings
Predictive Analytics
- Predict incidents before they happen (anomaly detection)
- Suggest preventive fixes ("You're approaching N+1 territory")
Self-Hosted & Open-Source
- Consider open-sourcing the training pipeline
- Containerized deployment for self-hosting
- Community contributions for new incident categories
Expand Revenue Model
- SaaS (hosted) + On-premise licensing
- Custom fine-tuning services for enterprises
- Training courses for incident response
Closing Thoughts
SIRCA isn't just a tool. It's a shift in how teams respond to production incidents. Instead of firefighting in the dark, engineers get instant, actionable insights. Recovery time goes down. Sleep improves. SLAs look good.
We built this because we believe production engineering should be less about guessing and more about knowing. And with AI fine-tuned on real incident patterns, we're getting there.
We're just getting started.
Built With
- claude-api
- digitalocean
- docker
- fastapi
- grafana
- mistral-7b-(qlora)
- postgresql
- python
- slack

Log in or sign up for Devpost to join the conversation.