-
Smart Guard
Inspiration
We noticed prompt injection can compromise agent systems, so we set out to make them safer.
What it does
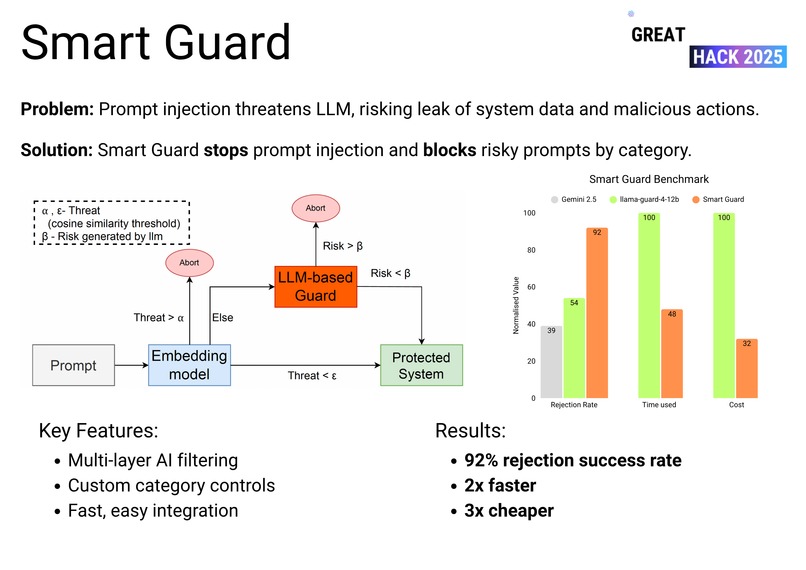
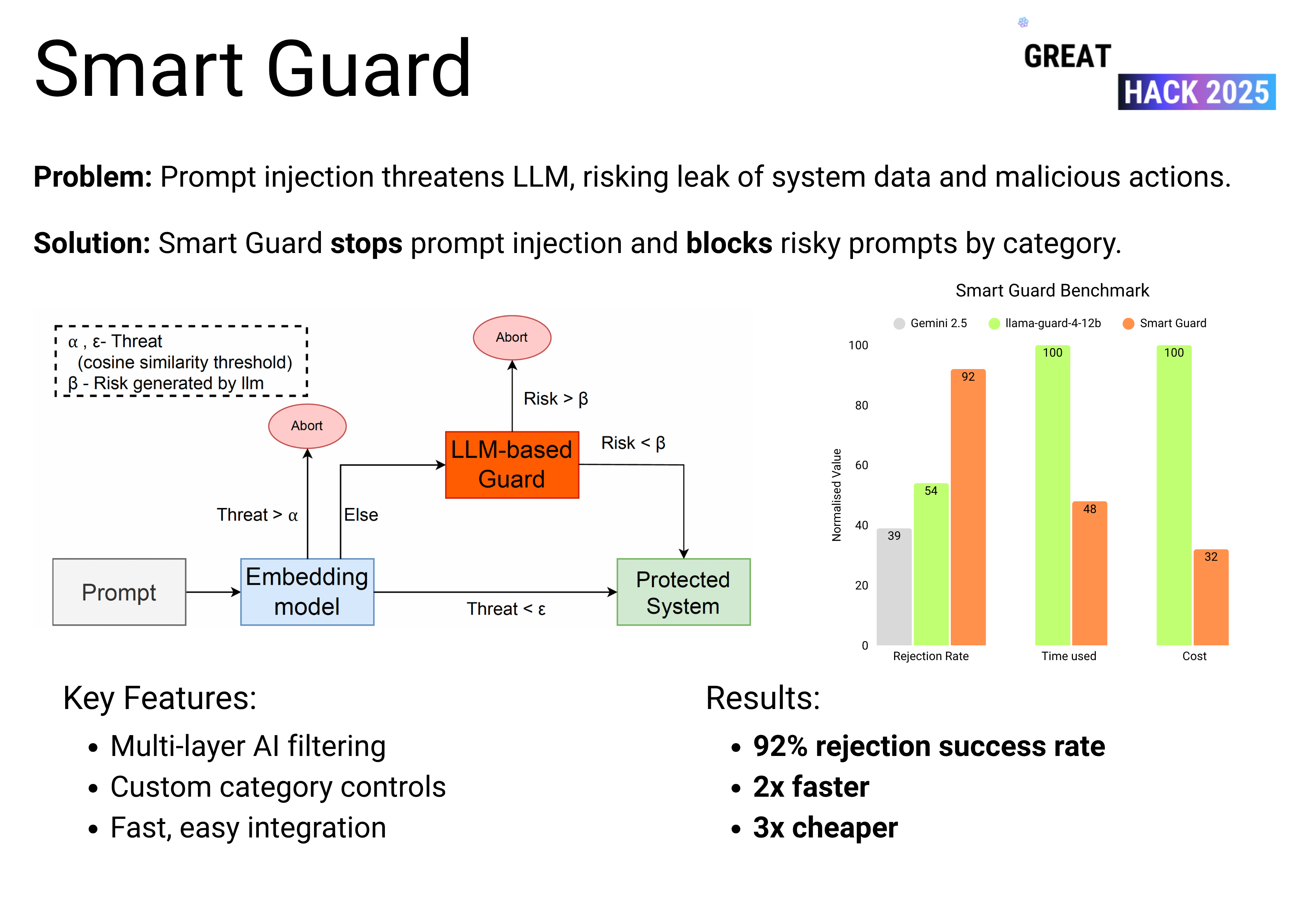
Smart Guard checks user input sent to AI, stopping harmful prompts before they cause problems.
How we built it
We use an embedding model with a classic LLM guard to catch risky prompts, balancing detection speed with accuracy.
Challenges we ran into
Finding the right trade-off between catching more attacks and keeping the system fast.
Accomplishments
Smart Guard blocks 92% of jailbreak attempts and costs three times less than other solutions.
What we learned
Combining different detection methods makes systems safer without slowing them down.
What's next
We will extend support, improve detection for new threats, and help more users secure their AI agents.





Log in or sign up for Devpost to join the conversation.