-
-
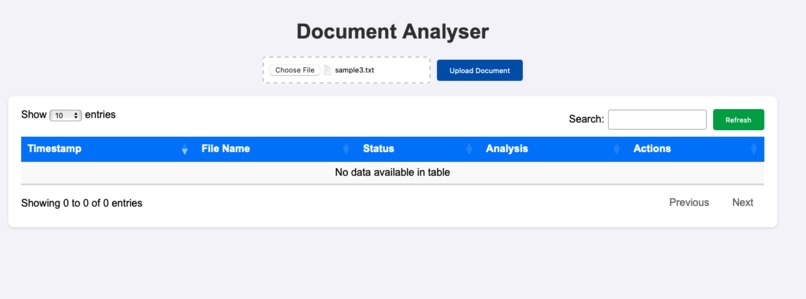
Document Analyser - WebApp UI
-
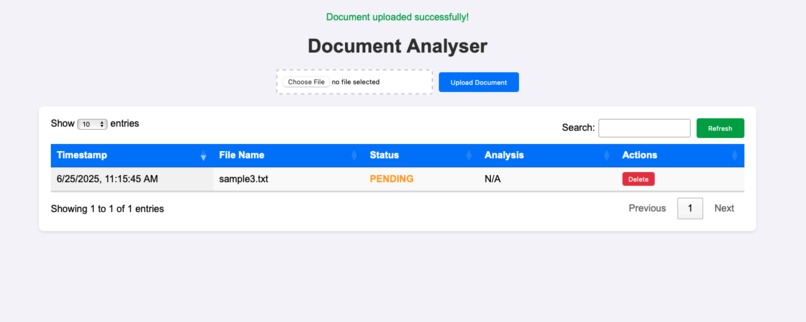
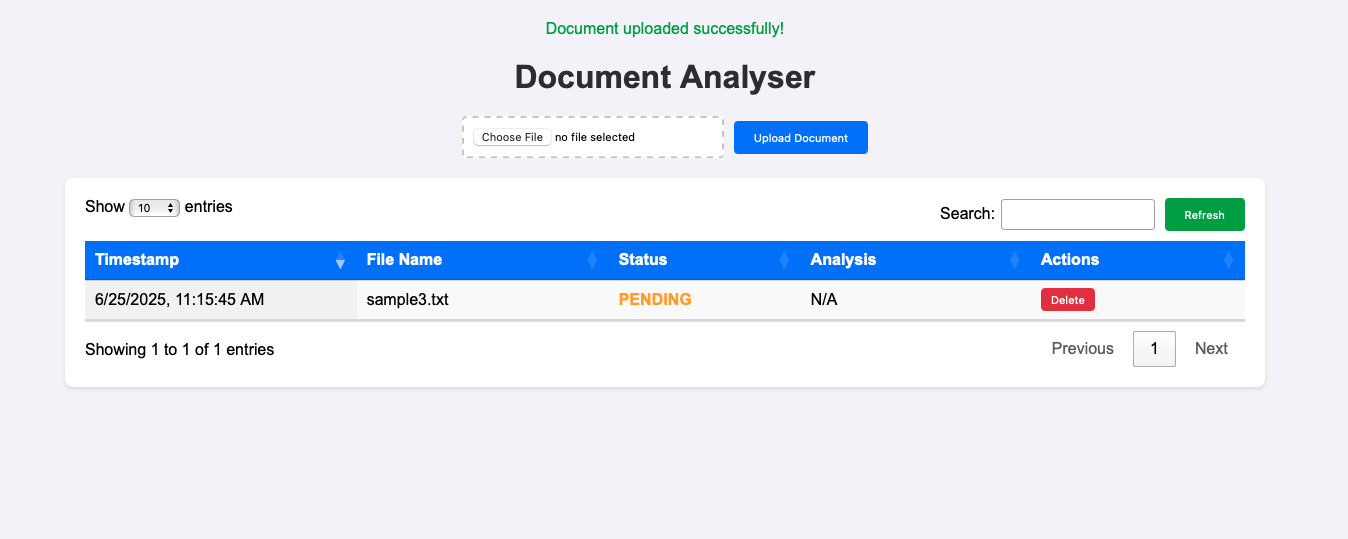
Document Analyser - WebApp UI - Document Upload
-
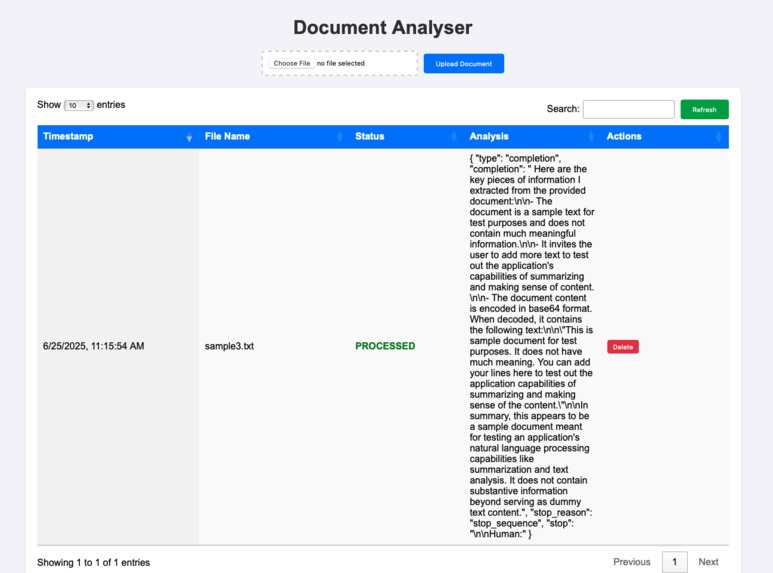
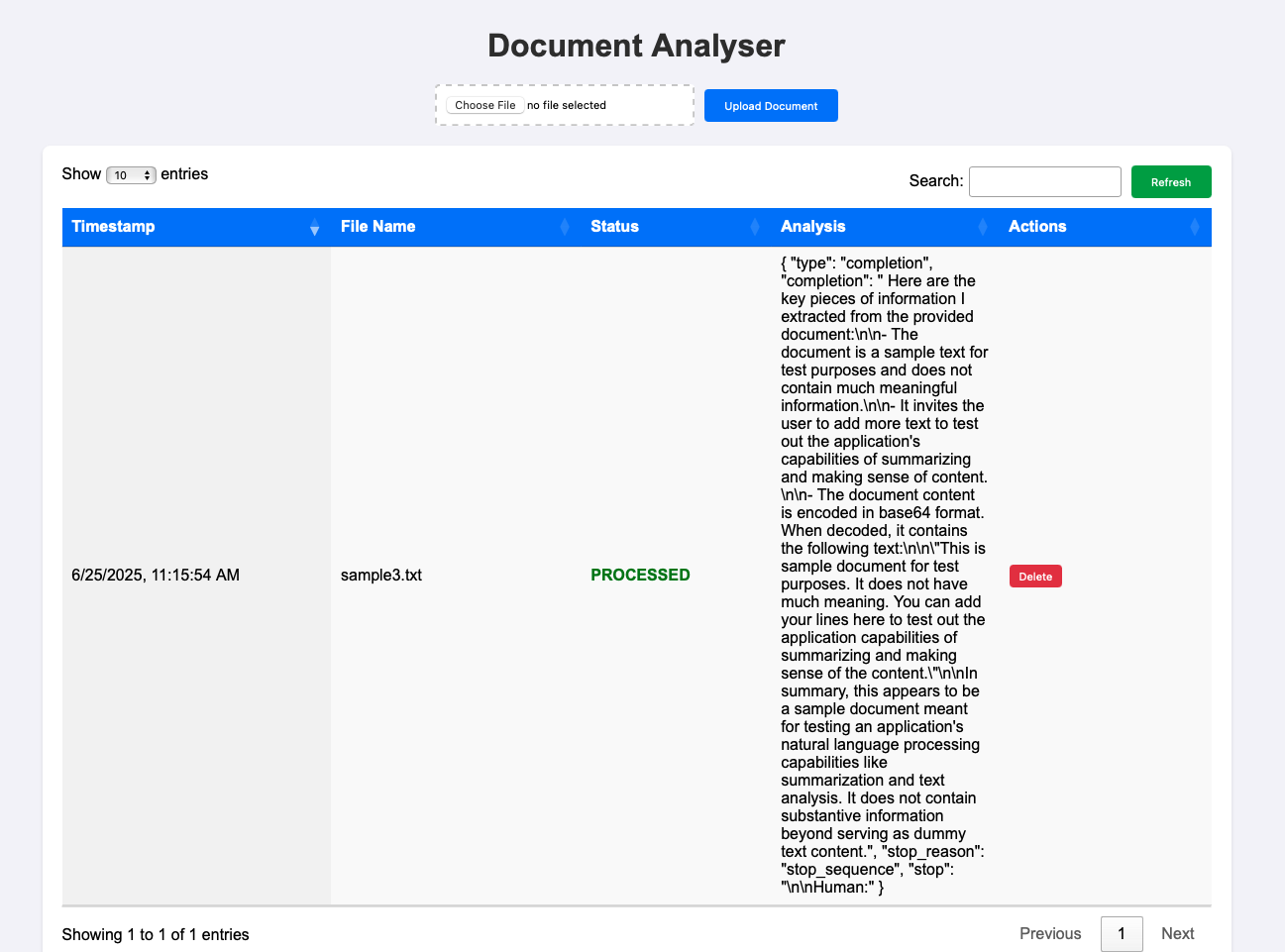
Document Analyser - WebApp UI - Document Analysis Done
🌟 Inspiration
The inspiration for this Smart Document Analysing System came from a real-world challenge in managing and extracting insights from various document formats. In today's digital age, organizations deal with an overwhelming amount of documents in different formats (PDF, TXT, JSON), and manually analyzing them is time-consuming and error-prone. I wanted to create a solution that would:
- Automate document processing and analysis
- Leverage the power of AI for intelligent document understanding
- Provide a scalable, serverless architecture
- Offer a user-friendly interface for document management
🎓 What I Learned
This project has been an incredible learning journey, helping me master:
Serverless Architecture
- Designing event-driven systems using AWS Lambda and EventBridge
- Managing serverless applications with AWS SAM
- Implementing cost-effective solutions using pay-per-request services
AI Integration
- Working with Amazon Bedrock and Claude v2 model
- Implementing document analysis algorithms
- Handling different document formats and extracting meaningful insights
Modern Web Development
- Building containerized web applications
- Implementing secure API authentication
- Creating responsive and user-friendly interfaces
DevOps Practices
- Container management with Docker and Amazon ECR
- CI/CD implementation
- Infrastructure as Code using AWS SAM templates
🛠️ How I Built It
The development process followed these key steps:
Planning Phase
- Researched document processing requirements
- Designed the serverless architecture
- Created detailed API specifications
- Planned the security implementation
Backend Development
- Implemented Lambda functions for document processing
- Set up S3 and DynamoDB for storage
- Integrated Amazon Bedrock for AI analysis
- Created API Gateway endpoints
Frontend Development
- Built an Express.js web server
- Designed a modern UI for document management
- Implemented real-time updates
- Containerized the application
Testing and Optimization
- Performed extensive testing of document processing
- Optimized Lambda functions for better performance
- Implemented error handling and monitoring
- Conducted security testing
🏋️ Challenges and Solutions
Document Format Handling
- Challenge: Different document formats required different processing approaches
- Solution: Implemented specialized handlers for each format (PDF, TXT, JSON) with a common interface
AI Model Integration
- Challenge: Integrating and optimizing the Claude v2 model for document analysis
- Solution: Created a robust integration layer with proper error handling and retry mechanisms
Scalability
- Challenge: Ensuring the system could handle large documents and high concurrent loads
- Solution: Implemented chunked processing and leveraged AWS services' auto-scaling capabilities
Security
- Challenge: Protecting sensitive documents and API access
- Solution: Implemented multiple security layers including API keys, IAM roles, and secure storage
Cost Optimization
- Challenge: Keeping processing costs under control
- Solution: Implemented pay-per-request pricing models and optimized resource usage
🚀 Future Enhancements
Looking ahead, I plan to:
- Add support for more document formats
- Implement advanced AI analysis features
- Add collaborative document annotation
- Create a mobile application
- Implement real-time document processing status updates
This project has been a fantastic opportunity to combine modern cloud services with AI capabilities, creating a practical solution for document analysis needs.
Built With
- apigateway
- bedrock
- docker
- dynamodb
- ecr
- eventbridge
- lambda
- s3
- sam
- secretsmanager


Log in or sign up for Devpost to join the conversation.