-
-
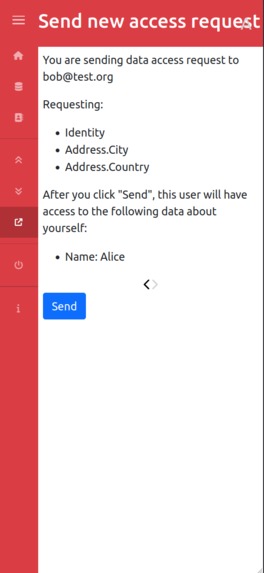
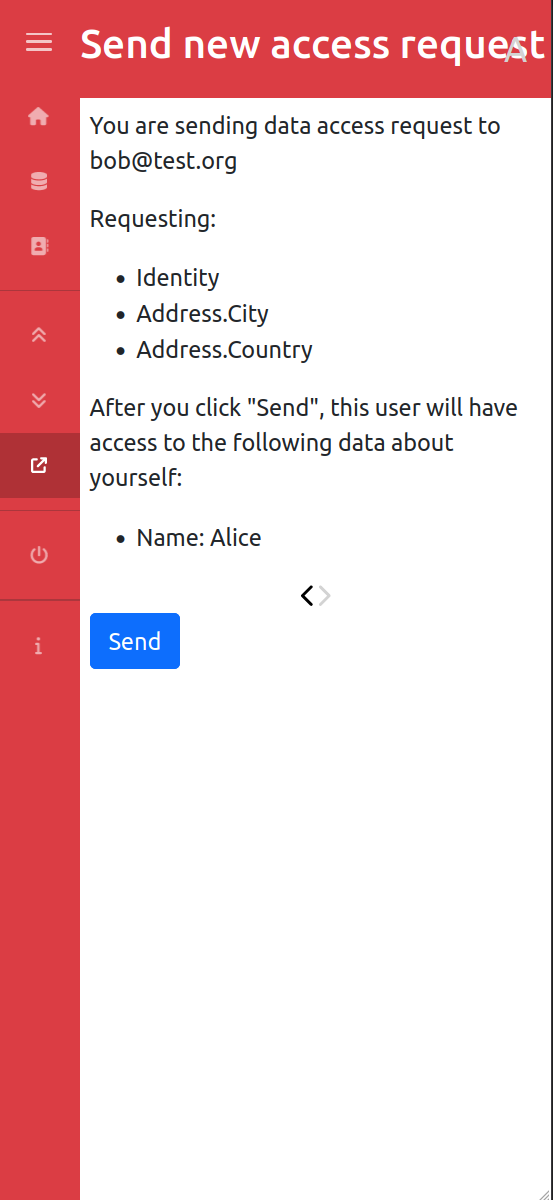
Sending Acces Request
-
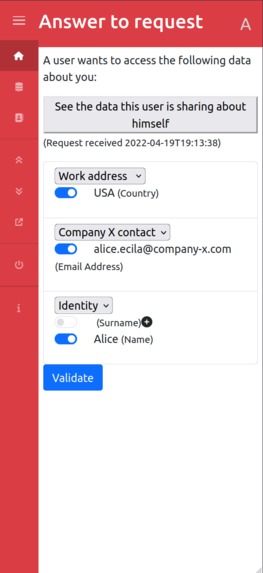
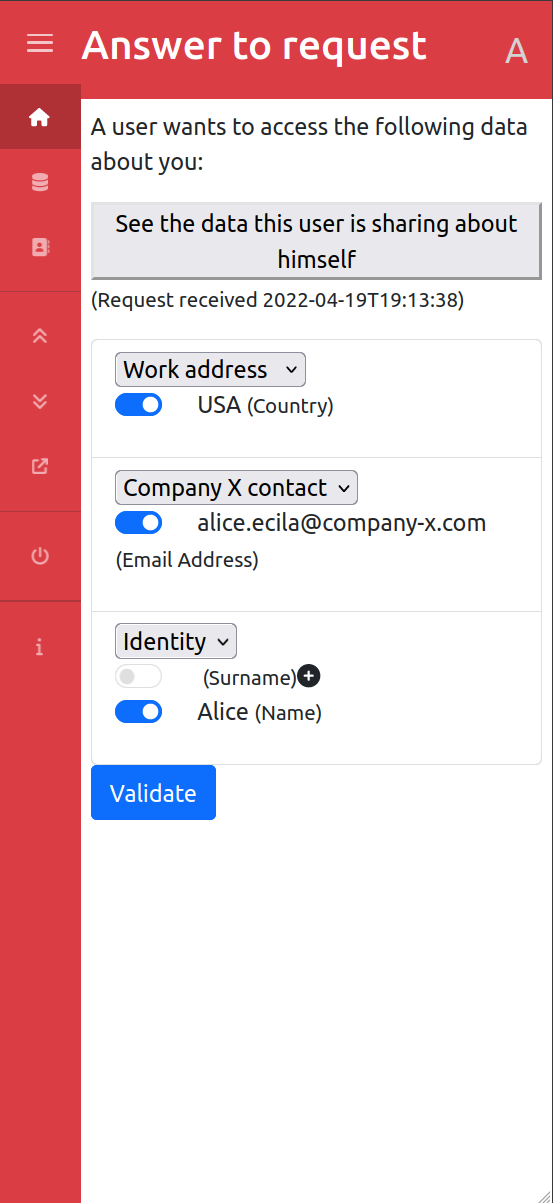
Answer to an Access Request
-
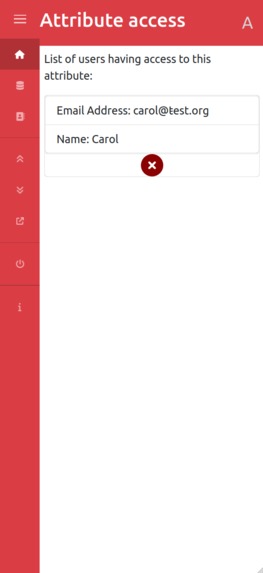
Data tracker
-
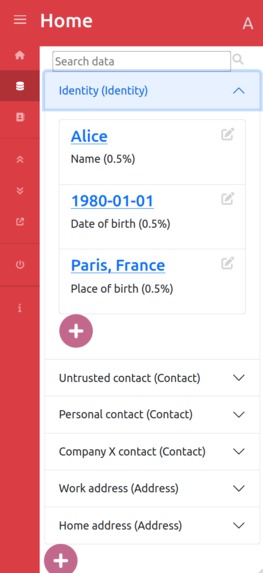
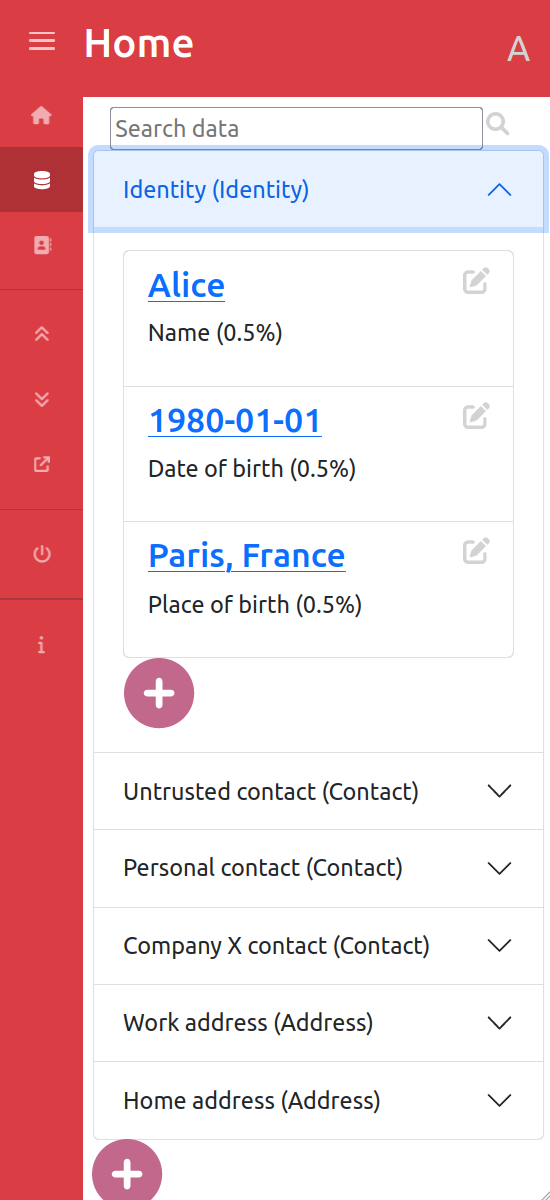
User personal data management
Inspiration
In the first years of digitization, pictures were shared by sending copies via emails or external storage. If was impossible to control who had access to them. Then, social networks were created, and sharing data was made much easier. Users were able to manage permissions, but also post comments and interact with others. What is now possible with pictures is today still impossible for our own identity data, such as our name, date of birth or credit card number.
What it does
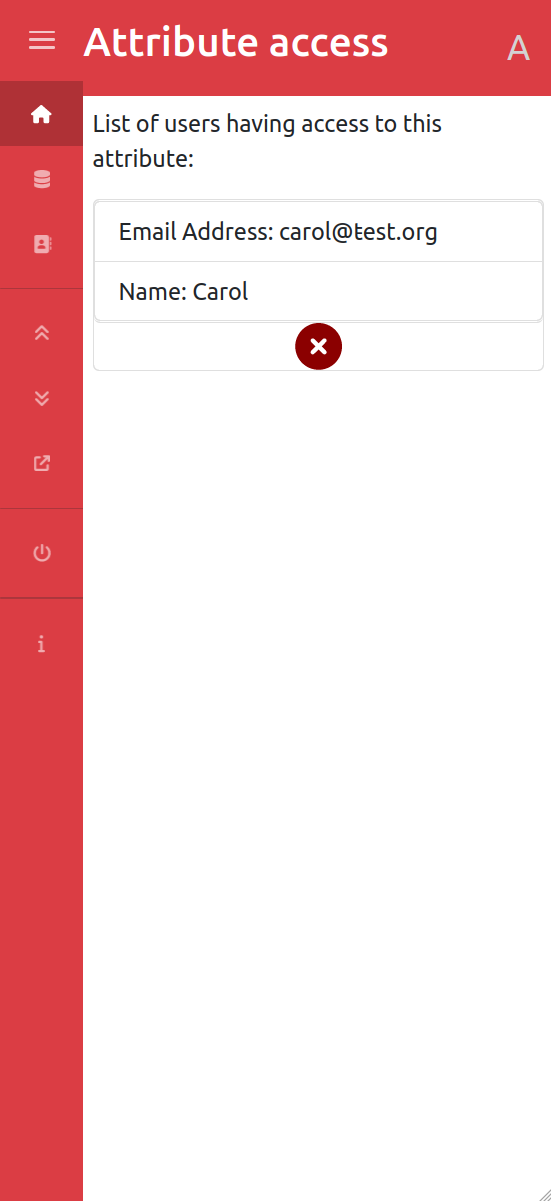
Our solution first lets users manage their personal data (identity, address) but also the data about their owned assets (car, phone…) and who has access to that data. It becomes easy to share data, track where your data is, and revoke access at any time, making data protection law such as GDPR easier to apply for both individuals and organizations. The user doesn't have to go through yet another enrollment process, they just have to share pieces of information to the providers of services which can also be revoked at any time. For instance, when an insurance company wants to know some information about new customers, they just have to pick the attributes they want to have access to from an organized list and send the “data access request” to the user. The user then decides which attributes to share based on the request. If they have several cars, and want a new insurance only for one of them, they will only share the data about that car to the insurance company. Similarly, if the insurance company asks information about their employment, and the user considers this is not relevant, they can choose not to share this information.
How we built it
We are taking full advantage of graph technology to be able to track each data attribute individually. This way of representing data allows us to attach more properties to each attribute, and not only its value. We can for instance define a trust score, that tells other users whether the phone number they see actually is a real phone number and really belongs to the a given user.
Technically speaking, we rely on the TigerGraph cloud platform, which will let us manage such project at scale. The volume of data that can be stored being huge. On top of this graph, we have built an API in Python, using FastAPI, and a simple web user interface using ReactJS to demonstrate the functionalities, which you can see in the video. (Note that we have not put a lot of efforts in the design yet)
For the scope of the demonstration, we have created a small, static, “data model”, containing entities and attributes users can store data about. This includes: Identity (with Name, Surname and Data of birth attributes), Contact Information (Email Address, Phone number), Address (Country, City, ….), Car(Licence plate, color) and Pet (Name, Type, Date of birth…). Users can then declare none, one or several of these entities and are then able to send data requests to other users, whether the other user is already registered into the application or not.
The model is infinitely extensible, we can easily support banking information, healthcare data or information about user's purchases on different e-commerce websites.
Challenges we ran into
The main challenge we faced was creating the data exchange request. We wanted to make sure the request sender could be identified, without violating our own principles of privacy and data control. That means the data requester must share some information about themselves when sending the request, so that the user receiving the request knows who is sending it and can decide whether they accept the request or not. But the sender also needs to know they have sent some data, and still be able to stop sharing at any time. An access request is hence bidirectional: while a data access is requested from user A to user B, another request is granted by user B to user A on some data about user B.
Accomplishments that we're proud of
We are proud to have managed to build this application in such a short amount of time (one month). We are happy to have been able to make our initial high level concept into a reality in way that we feel elegantly solves a complex problem. We propose an innovative solution to a common problem (data sharing and user's agreement) which will provide benefit from both sides. On one side, users will have a better control of their personal data. And on the other side, users will be able to better manage their contacts, organizations will finally overcome some challenges related to KYC (Know Your Customer). The concept of trust score, which we discuss further down in the innovation section, will provide all parties higher confidence when exchanging data digitally.
What we learned
We've learned a lot of TigerGraph itself, this project being the first one we built using this technology. We had to create the project from the ground up, from a very high level general concept to working PoC, developing front end, back end and a working permissions model.
What's next for the Personal IAM application?
We have many ideas on how to develop this application further to make it even more intuitive for users with the idea to help them control and manage access to their data. Some possible enhancements are listed below.
- We will integrate this application with our dynamic and versioned ontology engine, such that the data model is fully managed by an admin panel, and can evolve in time much more quickly, as we add support for more data type (e.g.: bikes, houses or glasses). This ontology engine also fully supports relationships between things, such that users can easily manage information about their kids for instance.
- We want to define some “templates” for access requests, since very often, the same group of attributes are required. That will enable users to define their “Personas” and share data even more easily. For instance, you can have your “family persona”, which is shared with your family, including your home address. And a “work for company X persona”, including your professional email and phone number.
- We also plan to improve even more data privacy, letting users store their data on their own devices, without us to knowing the particular data value. We have included a first implementation in the presented solution, but it requires more work to be secure and usable. That includes end-to-end encryption principles as well as leveraging trust scores.
- We want to take full advantage of Graph Data Science to provide meaningful recommendations to users about which data about themselves is missing, or which piece of information is required by some company but never used… The sky is the limit.
- In a more longer term we would like to convince provider's of services to make use of our solution as an alternative to the current static and repetitive enrollment process.
Built With
- fastapi
- python
- react
- tigergraph



Log in or sign up for Devpost to join the conversation.