-
-
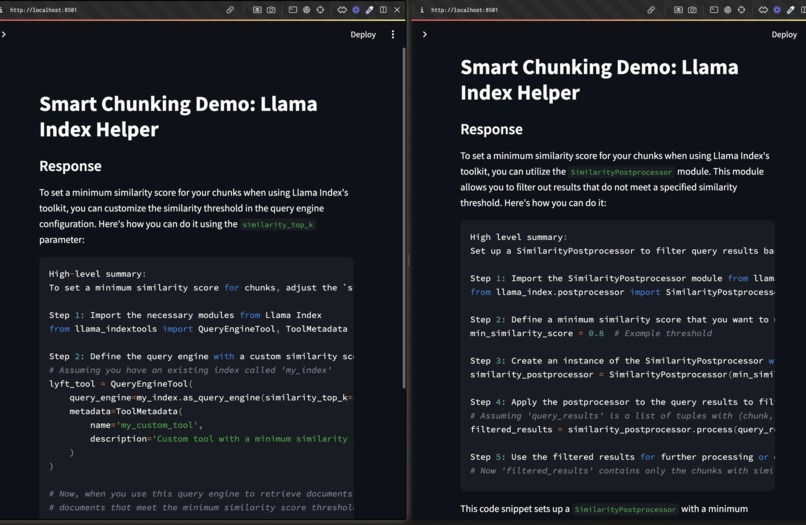
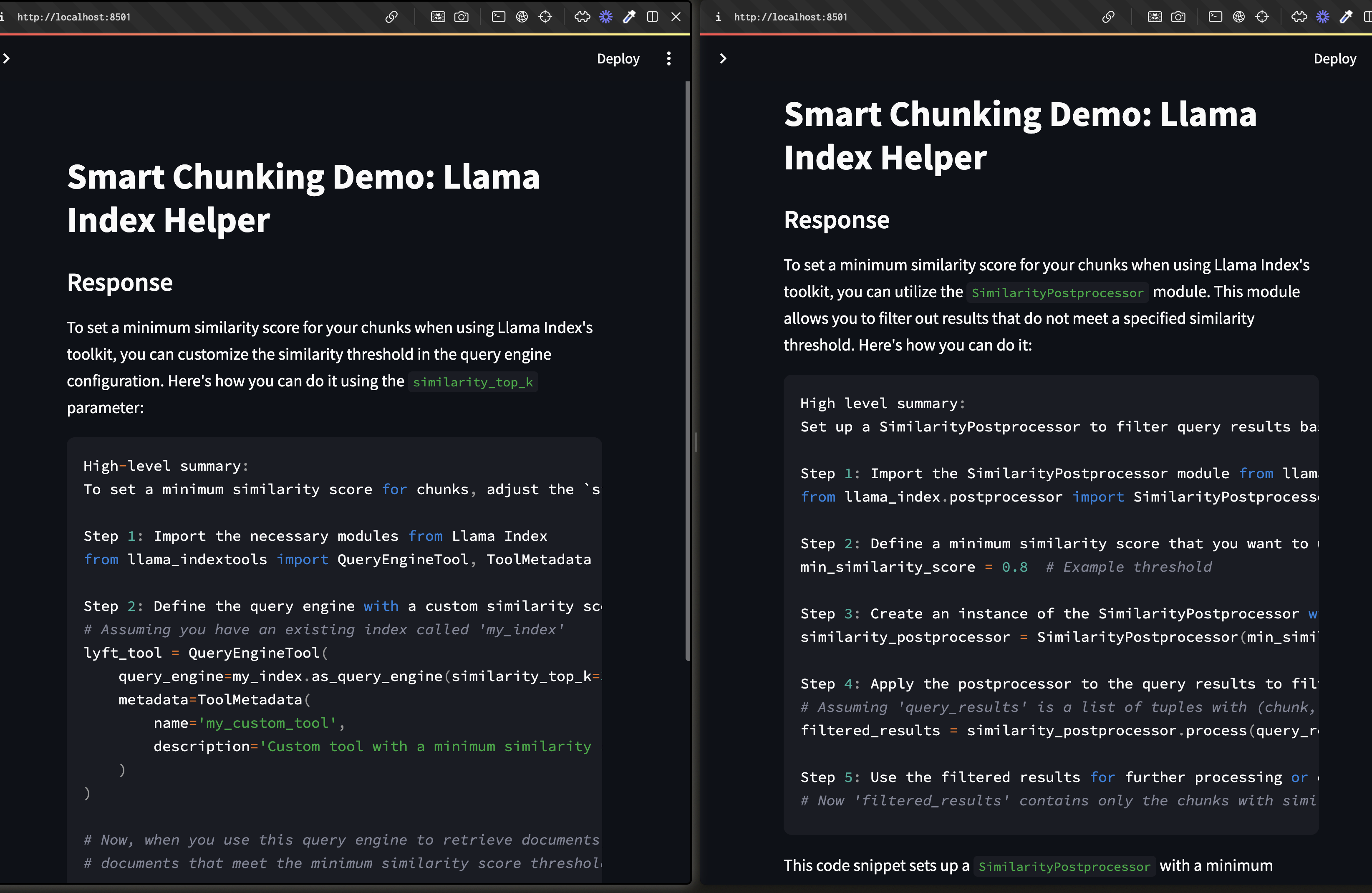
Smart chunking (right) outperforming standard chunking (left) for "how do I set similarity scores?" Source - Yi Ding
Inspiration
I've been trying to figure out how to get the highest quality outputs out of LLMs for a few months now. This came up in my research as fairly low-hanging fruit.
What it does
It makes RAG applications perform better. Using this algorithm, you end up with an output that is more specific and factually correct. Because the model is given complete ideas instead of random snippets, it doesn't have to try to infer as much from context and can provide better answers.
How I built it
With Python in a day ^^
Challenges I ran into
Using this approach, the database takes a relatively long time to build. I haven't done anything to reduce the build time of the database yet, and I suspect that this will prove technically difficult (absolutely possible, but now we're talking about using smaller specific models and that's out of my area of expertise).
Accomplishments that we're proud of
I showed an A/B test to three Llama Index engineers and they said that the application using my "smart chunks" provided more accurate answers, more intelligent approaches, and fewer hallucinations.
What I learned
All sorts of good stuff ^^
What's next for Como Se Llama?
Testing it across more use cases. This works really well with code examples, but you see the same performance gains with creative data (like books or newspapers), financial data (Qs and Ks) and other forms of data? I think so, but that's theoretical right now.
Built With
- astra
- langchain
- openai
- python

Log in or sign up for Devpost to join the conversation.