-
-

3D Printing Prototypes
-
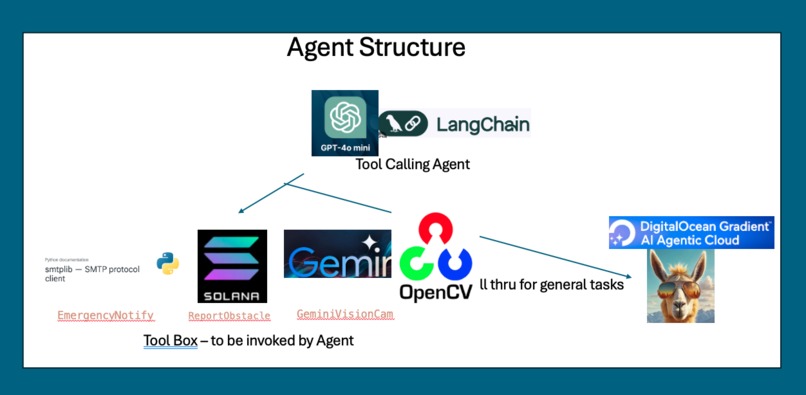
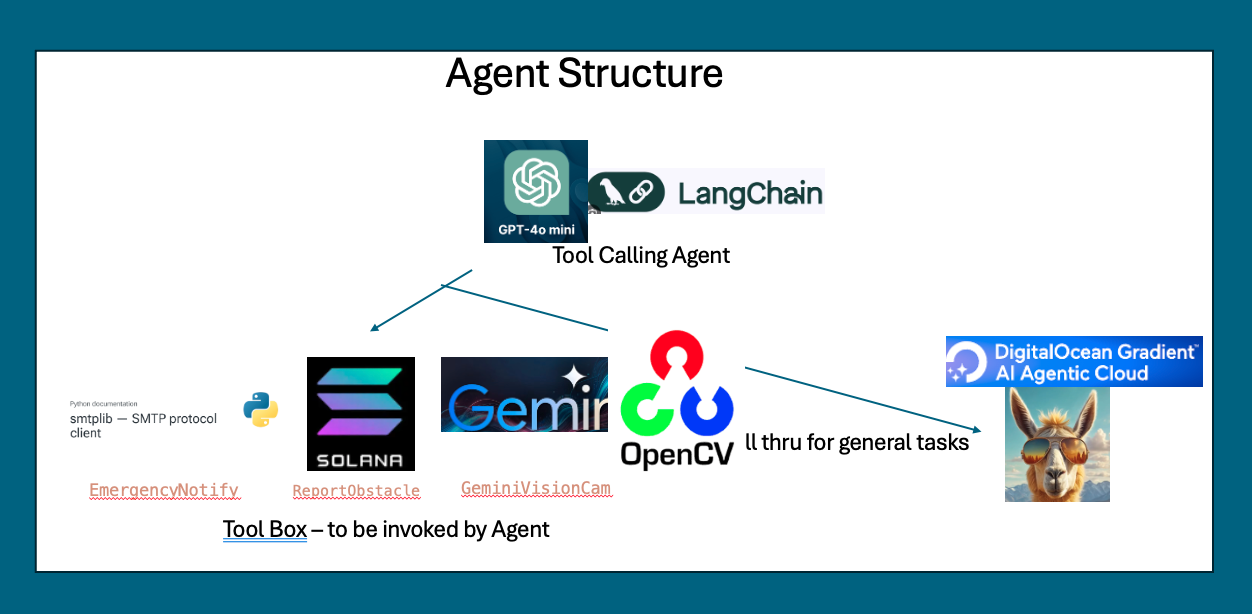
Agent Structure
-
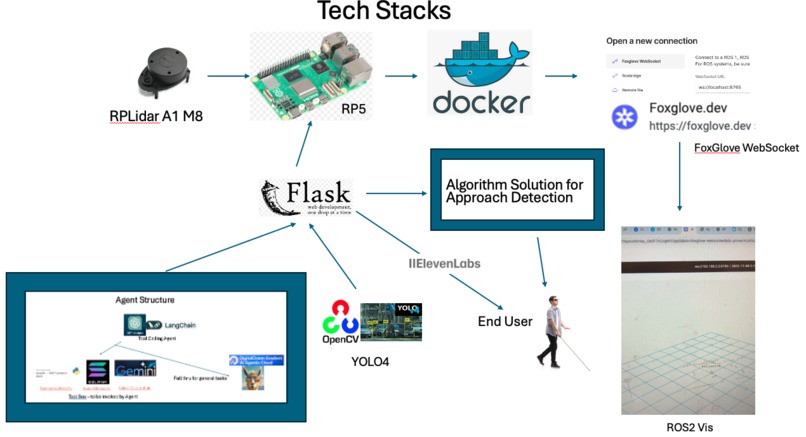
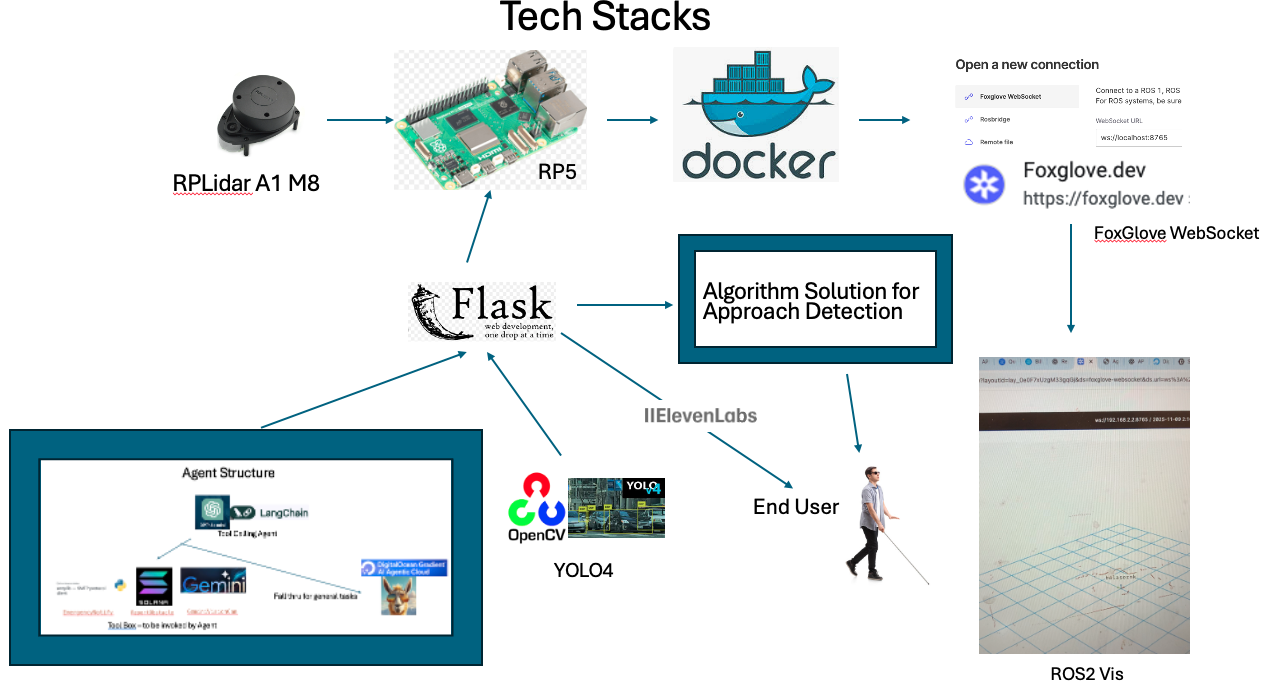
Tech Stacks
-

ROS2 Visualization Pipeline
-

-





🦯 Agentic Smart Cane — Your AI Partner in Vision and Navigation 👁️🤖
🚀 Inspiration
Over 285 million people around the world live with visual impairments, facing daily challenges in navigation and independence. We wanted to build more than just a smart cane — we wanted a companion that perceives, reasons, and communicates like a true human guide.
That vision became Agentic Smart Cane — a multimodal AI system that sees, thinks, and speaks to help the blind navigate safely and confidently.
🧠 What We Built
The Agentic Smart Cane combines ROS 2 LiDAR mapping, vision-based scene understanding, and an agentic reasoning brain built on OpenAI and Gemini. Users can speak naturally to the cane, receive voice feedback, and even earn blockchain-based mobility rewards.
It’s not just assistive — it’s intelligent.
Our Tech Stack Diagram

Agent structure Diagram

The Whole Big Picture of Software->Embedded->Hardware

RPLidar A1M8 -> Raspberry Pi5 -> Docker -> FoxGlove Websocket -> Ros2 Visualization Pipeline
⚙️ Key Features
🎙 Voice Interaction (ElevenLabs STT/TTS)
Natural speech understanding lets users ask questions (“Where am I?”) or request help. The system responds in lifelike voice with clear instructions.
👁 Environment Awareness (LiDAR + Gemini Vision)
The cane interprets surroundings using LiDAR and camera input: “There’s a person two meters ahead.” “You’re approaching stairs.” “A car is passing on your right.”
🧩 Agentic Reasoning Brain (OpenAI 4o-mini)
At its core, our agentic architecture uses OpenAI GPT-4o-mini for reasoning — deciding how to act, what tools to invoke, and how to respond. Gemini 2.0 Vision handles scene analysis; results are then interpreted by the reasoning layer.
🪄 Fallback Reasoner (DigitalOcean Gradient AI + LLaMA-3.8-Instruct)
When OpenAI’s 4o-mini is unavailable, the agent routes general reasoning tasks to LLaMA-3.8-Instruct, hosted via DigitalOcean Gradient AI. This ensured full offline continuity and open-infrastructure flexibility.
🗺 Real-Time Spatial Mapping (ROS 2 + LiDAR)
The Raspberry Pi 5 runs ROS 2 (Jazzy) with RPLIDAR A1, streaming scans to Foxglove Studio for live 3D visualization and debugging.
🪙 Reward System (Solana Devnet)
Users earn 0.7 SOL tokens on Solana Devnet for verified walking sessions. Wallet authentication and transaction signing are handled via Phantom Wallet.
☁️ Deployment (Vultr Docker Instance)
We deployed the web dashboard and agent backend to a Vultr Docker container, allowing remote monitoring and visualization without taxing the Pi’s resources.
🧩 Tech Stack Overview
Hardware
- Raspberry Pi 5
- RPLIDAR A1 LiDAR sensor
- USB camera, microphone, speaker
- Fusion360
- Bambu Lab A1
Software
- ROS 2 (Jazzy) — sensor fusion and LiDAR data stream
- Foxglove Bridge — real-time 3D LiDAR visualization
- OpenAI 4o-mini — primary reasoning agent
- Gemini 2.0 Vision — scene recognition and spatial description
- DigitalOcean Gradient AI (LLaMA 3.8-Instruct) — fallback reasoning engine
- ElevenLabs — speech recognition and text-to-speech
- Solana Devnet + Phantom Wallet — tokenized reward tracking
- Vultr Docker — web hosting and remote control panel
🛠 How It Works
LiDAR Sensor on Raspberry Pi continuously scans surroundings via ROS 2.
Foxglove Bridge streams real-time point-cloud data for 3D visualization.
Camera Feed is analyzed by Gemini 2.0 Vision, detecting objects and context.
Reasoning Brain (OpenAI 4o-mini) interprets this information, decides next actions, and may call tools.
If OpenAI is unavailable, LLaMA 3.8-Instruct (via DigitalOcean Gradient AI) takes over reasoning.
Voice Interface (ElevenLabs STT/TTS) lets the user speak naturally and receive guidance.
Reward System (Solana Devnet) logs mobility sessions and issues 0.7 SOL rewards through Phantom Wallet.
Vultr Docker Backend hosts the agent’s web interface for monitoring and updates.
🌐 Integration with MLH Tracks
🪙 Solana
Implemented user authentication and reward distribution via Phantom Wallet.
Each completed reporting obstacle triggers an on-chain reward of 0.7 SOL (Devnet). This is limited by fraud prevention of not being able to report it for 10 minutes and reporting within 50m, etc.
🧠 Gemini
- Used Gemini 2.0 Vision to describe the scene and detect nearby obstacles in real time.
⚙️ DigitalOcean Gradient AI
- Hosted LLaMA 3.8-Instruct model as a fallback reasoning handler invoked by the main agent when OpenAI 4o-mini is busy or offline.
🗣 ElevenLabs
- Provided speech-to-text and text-to-speech pipelines for hands-free interaction.
🐳 Vultr
- Deployed a Dockerized our landing application website that has a introductory video
Deployed public IP URL provided by Vultr -> http://45.63.6.246/


💡 Impact
The Agentic Smart Cane restores confidence, safety, and independence to visually impaired users. It’s not just a navigation tool — it’s a cognitive companion that perceives, reasons, and communicates.
“It gives sight through sound — and confidence through intelligence.”
💪 Challenges We Overcame
Running real-time LiDAR → ROS 2 → Foxglove pipeline on limited Pi 5 hardware.
Synchronizing LiDAR scans with Gemini Vision frames for multimodal fusion.
Designing an agent framework that dynamically switches between OpenAI 4o-mini and Gradient AI LLaMA-3.8.
Implementing reliable Phantom Wallet authentication and reward transactions on Solana Devnet.
Managing low-latency voice I/O on constrained edge hardware.
🔭 What’s Next
Add indoor SLAM for memory-based path learning.
Design a custom PCB to miniaturize the electronics.
Extend reward logic with cross-chain mobility credits.
Introduce edge inference for complete offline autonomy.
Built With
- autodesk-fusion-360
- base58
- digitalocean
- flask
- gemini
- gradient-ai
- html
- javascript
- llama-3.8-instruct
- open-ai
- python
- ros2
- solana
- solana-devnet
- yolov4


Log in or sign up for Devpost to join the conversation.