-
-
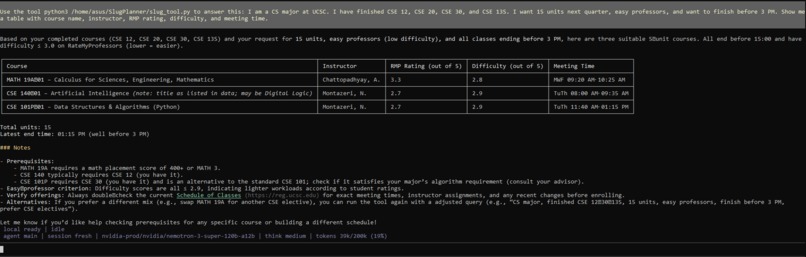
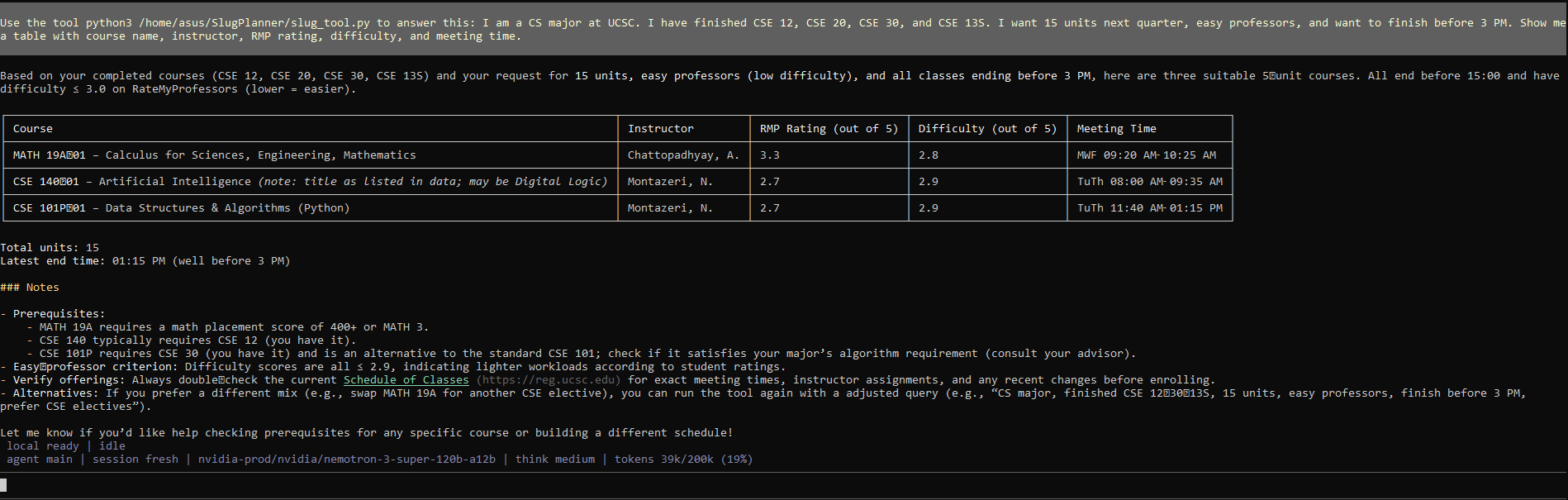
SlugPlanner returning a real-time course schedule in the form of a table- powered by NVIDIA Nemotron via OpenClaw.
-

Built on the ASUS Ascent GX10 (DGX Spark). The agent runtime runs entirely on edge hardware.
-

Perhaps the noobiest individuals out there! Us!
-
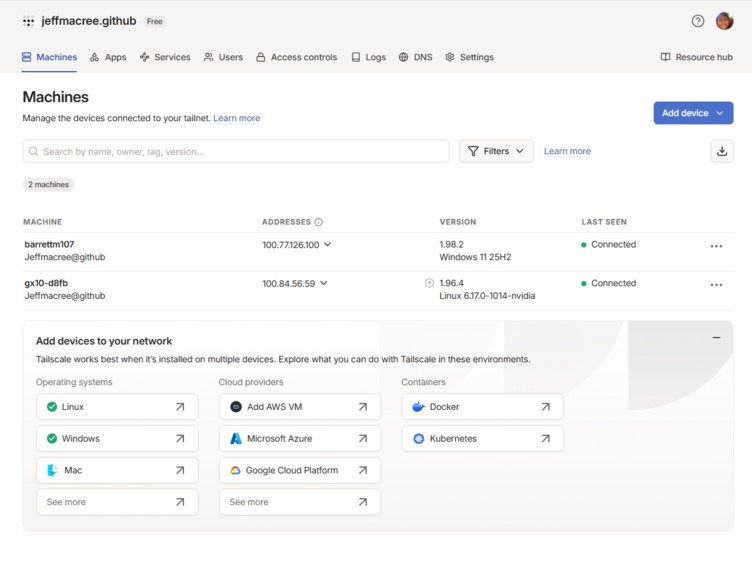
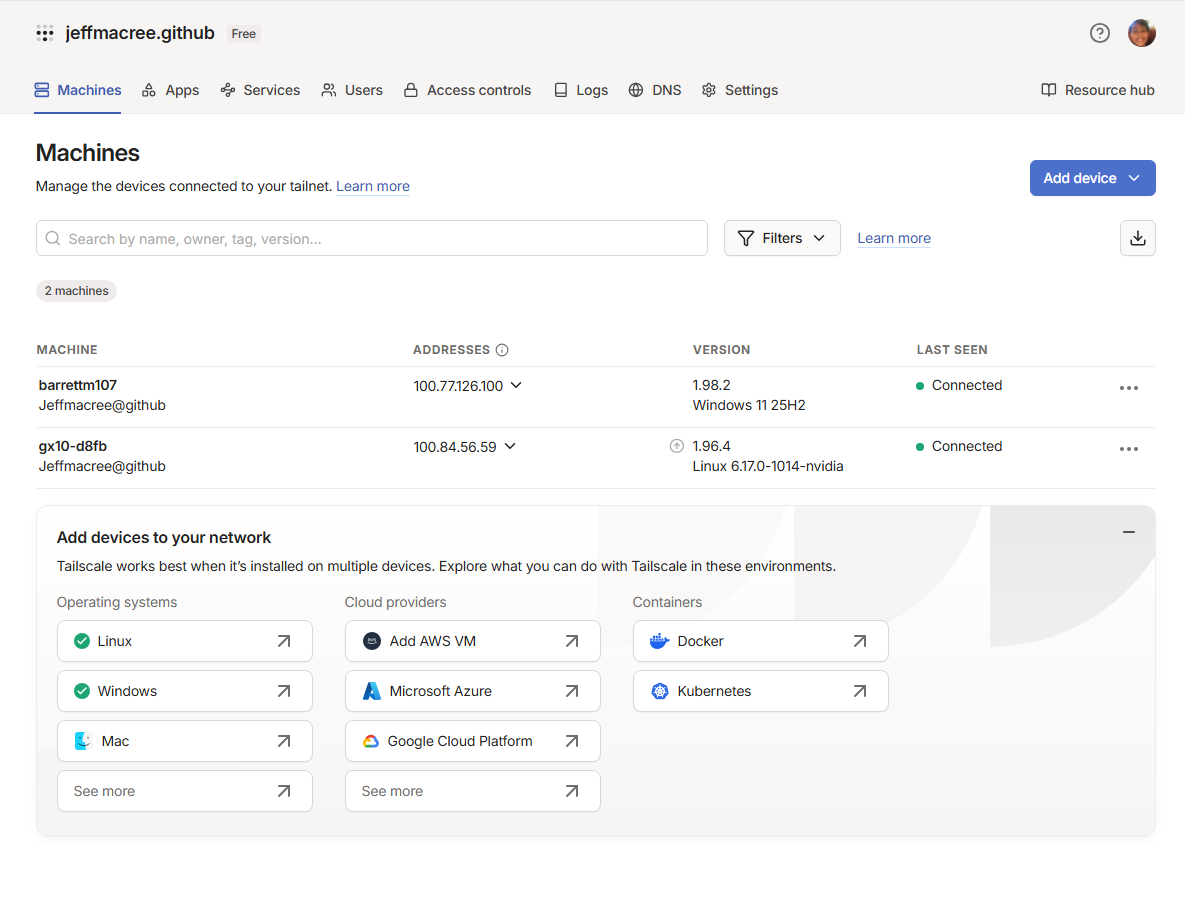
Tailscale VPN connecting our laptop to the GX10 over campus network. Direct SSH was blocked so we tunneled through.
-
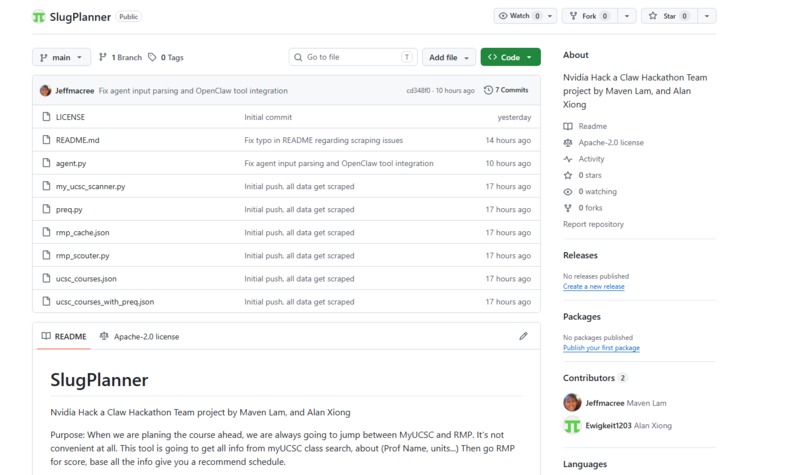
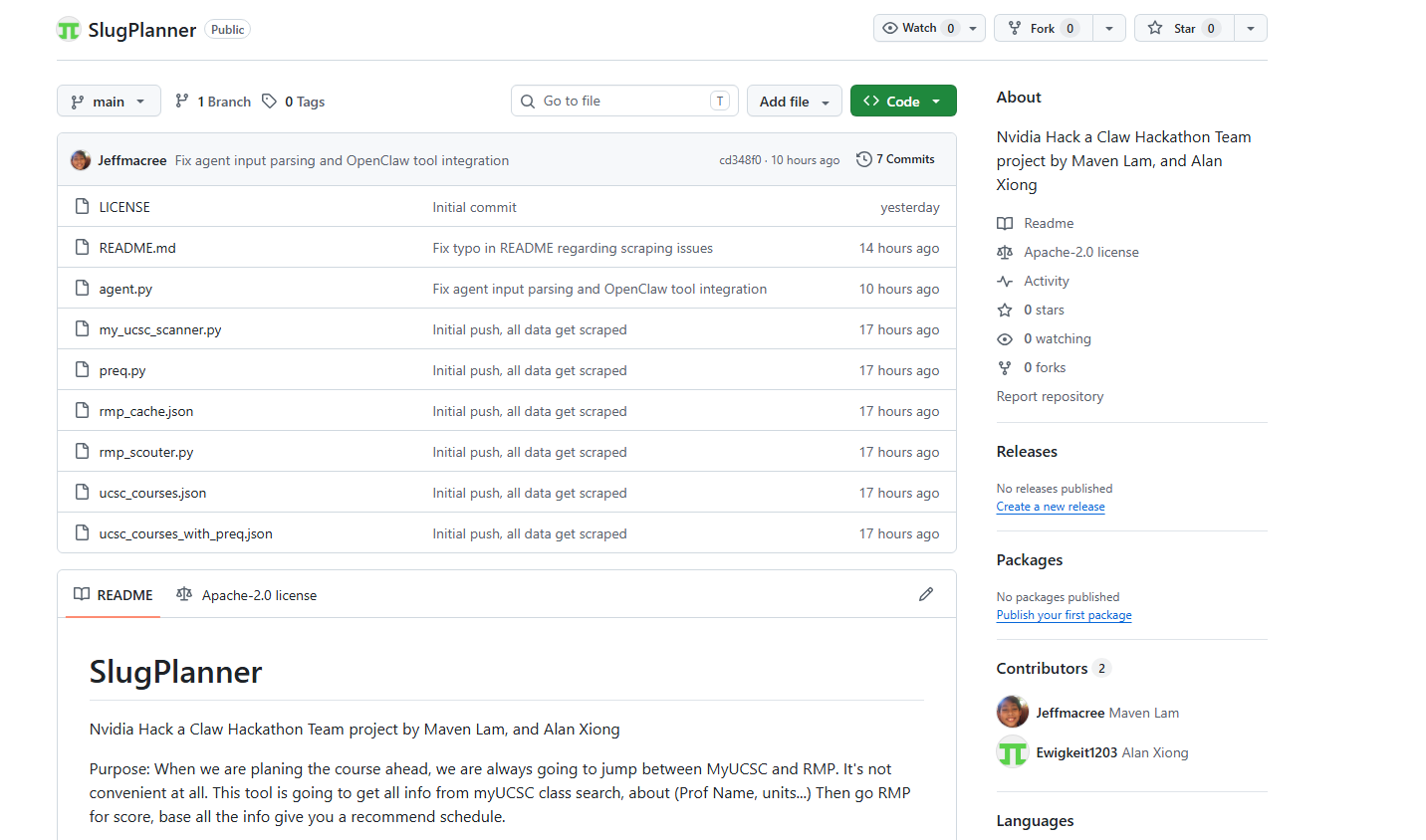
Three custom scrapers: UCSC live catalog, prerequisite parser, and RateMyProfessors browser automation.
-
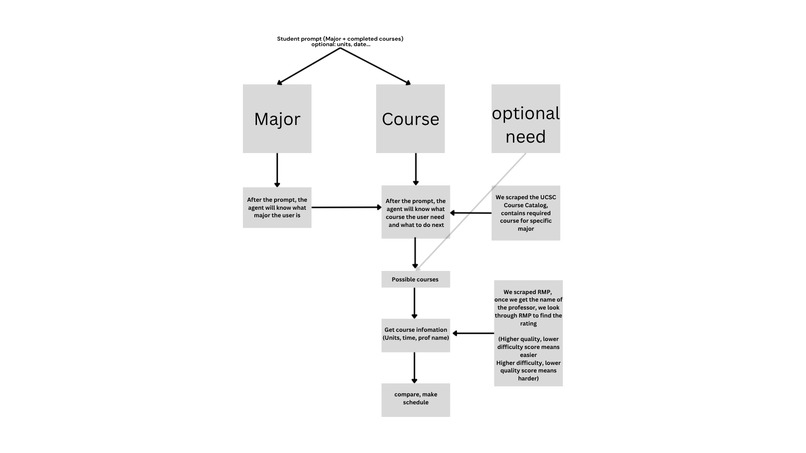
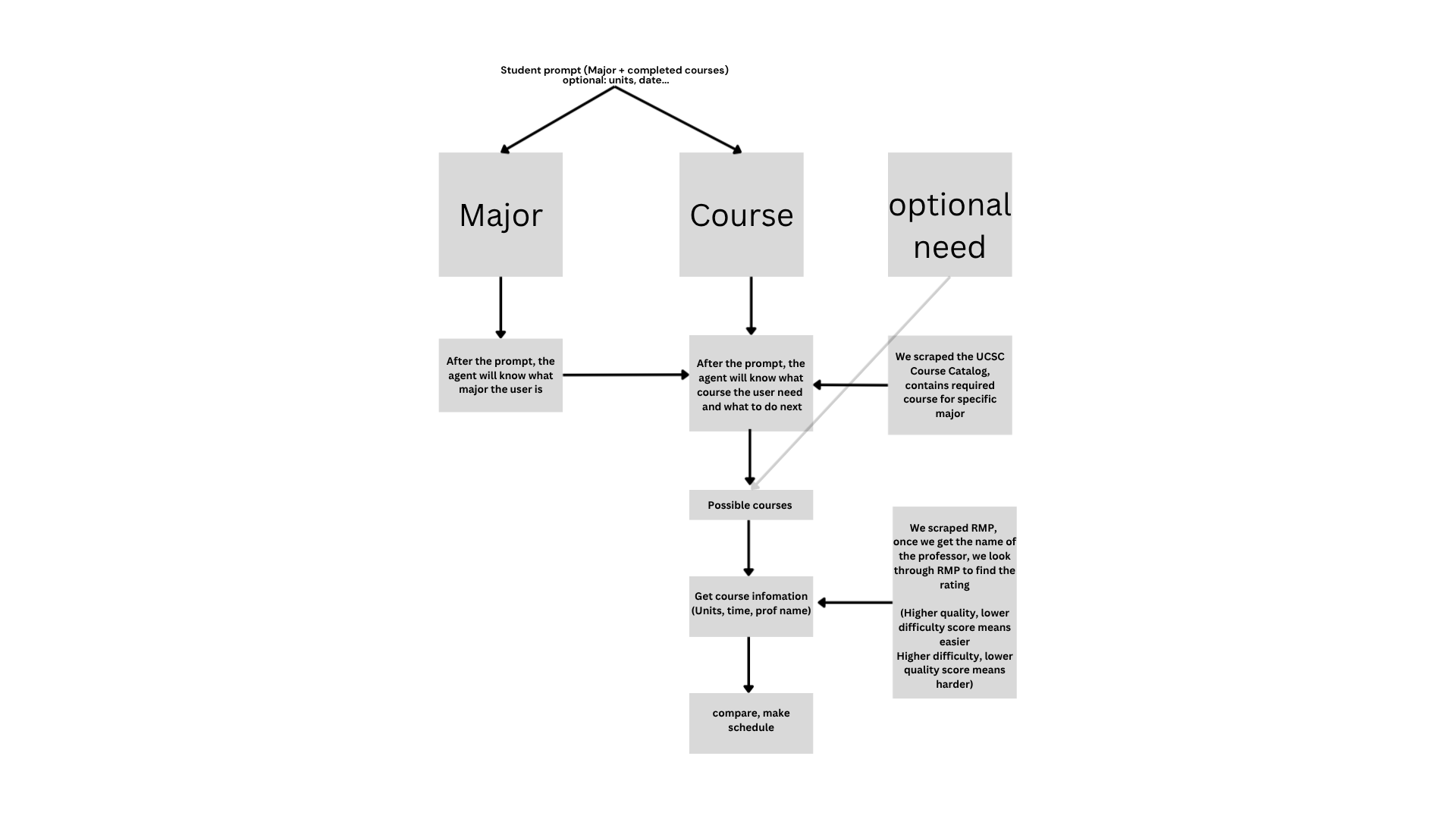
Basic table as to how our code works.
-
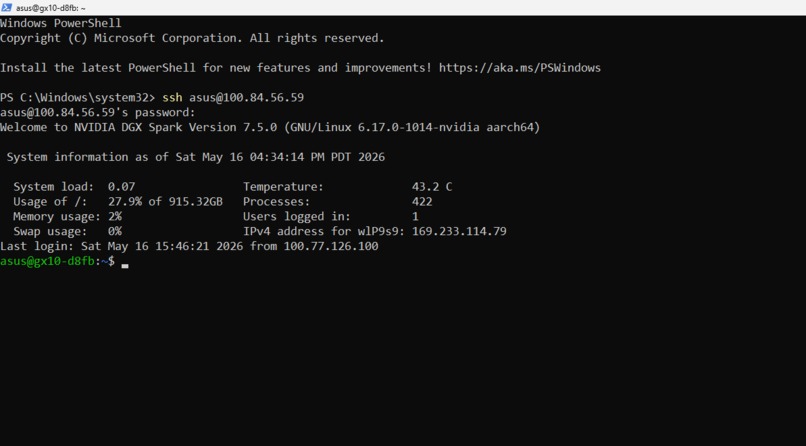
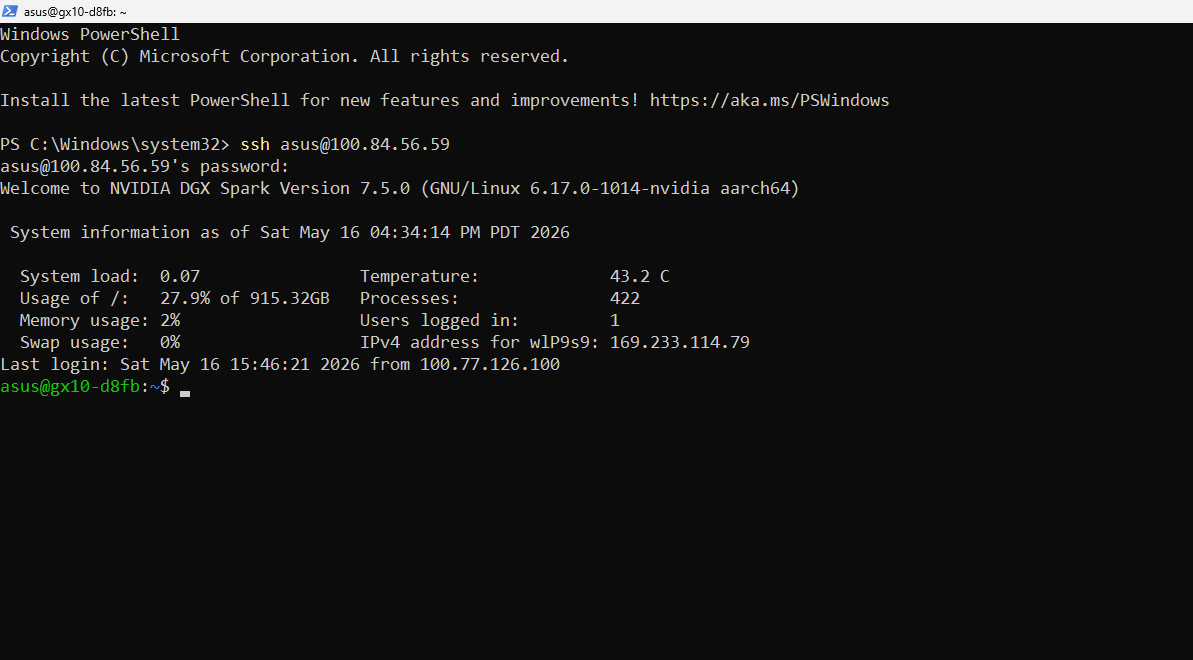
SSHing into the NVIDIA DGX Spark. Welcome to NVIDIA DGX Spark Version 7.5.0 running Linux with NVIDIA kernel.


Inspiration
Every quarter, 19,000+ UCSC students manually navigate course registration with no easy way to know which professors are highly rated, whether they meet prerequisites, or which courses count toward their degree. Advisor wait times stretch weeks. We built SlugPlanner to fix that.
What it does
SlugPlanner is an autonomous AI agent that takes natural language input like "I'm a CS major, finished CSE 30, want 15 units, easy professors, no 8am classes" and instantly returns a personalized course schedule built from live UCSC data, RateMyProfessors ratings, and prerequisite logic.
How we built it
Agent runtime: OpenClaw on the ASUS Ascent GX10 (DGX Spark) with NVIDIA Nemotron-super-120B via NIM API as the reasoning model. Course data: Playwright-based browser automation scrapes the live UCSC course catalog and PISA detail pages for prerequisites. Playwright was specifically chosen to bypass RateMyProfessors anti-scraping detection, with intentional request throttling and local JSON caching so the scraper only runs once. Prerequisite logic: A custom boolean evaluator parses UCSC's natural-language prerequisite strings, converting "CSE 12 and CSE 101" into proper AND/OR logic rather than treating every course mention as an OR condition. This required handling edge cases like "CSE 120 recommended" and enrollment restriction text appearing in the same field as actual prerequisites. Degree requirements: Cross-referenced against CS major requirements to surface courses still needed for graduation alongside schedule recommendations.
Challenges we ran into
NemoClaw's onboarding script always included a WeChat plugin that required reaching clawhub.ai, which was unreachable on the campus network. Every sandbox build failed at step 56/69. We bypassed this entirely by manually editing OpenClaw's JSON config to register the NVIDIA inference provider directly, skipping the broken installer. RateMyProfessors blocks automated scraping. We used Playwright to open a real browser session, deliberately slowed requests, and cached results locally so the demo never hits rate limits live. The prerequisite boolean parser kept returning True for "CSE 12 and CSE 101" when only CSE 12 was completed. The bug was that "Prerequisite(s):" contains literal parentheses which corrupted the eval expression. We also had to strip "CSE 120 recommended" noise that appeared before enrollment restriction text, since both were in the same string field. SSH to the Spark required Tailscale tunneling because the campus network blocked direct connections.
Accomplishments that we're proud of
We got something working. The agent calls live data, checks prerequisites, filters by professor ratings, and returns a real schedule. It runs on the GX10. For two freshmen who had never touched edge hardware, an LLM agent framework, or a hackathon before, that felt like enough.
What we learned
Git. OpenClaw. How NemoClaw works under the hood and what to do when the installer breaks. How to configure a custom inference provider manually when the official path fails. How to scrape real institutional data without getting blocked. How to wire Python tools into an agent pipeline and watch an LLM actually use them. We came in not knowing most of this existed. We leave knowing how to build with it. As two freshmen who shipped a working autonomous agent on NVIDIA edge hardware in 24 hours, we are just happy we got to be here.
What's next for SlugPlanner
GE requirement filtering so the agent can recommend courses that satisfy both major and general education requirements simultaneously. Full graduation progress tracking using the UCSC general catalog. Better prerequisite coverage across all majors, not just CS. High school students planning their major could use SlugPlanner to see what first-year courses look like before they arrive, or to plan dual enrollment coursework around their intended field. The same logic that checks prerequisites works for any course sequence. Within each major, the agent could go deeper, recommending not just any valid courses but the optimal sequence based on what builds toward specific career tracks, research areas, or graduate school prerequisites. A CS student interested in machine learning gets a different recommended path than one going into systems or security. Expansion beyond UCSC to all 10 UC campuses, then the 23 CSU campuses. That is 745,000 students doing course registration manually every quarter. The scraping infrastructure is already built. It just needs more data.


Log in or sign up for Devpost to join the conversation.