-
detecting an ai essay
Inspiration
We heavly considerd our idea for many hours before we started, trying to nail down something on theme that we thought would make a difference. Slop Scan came to us top down as a way to help with the growing battle of telling what's real from what's fake.
What it does
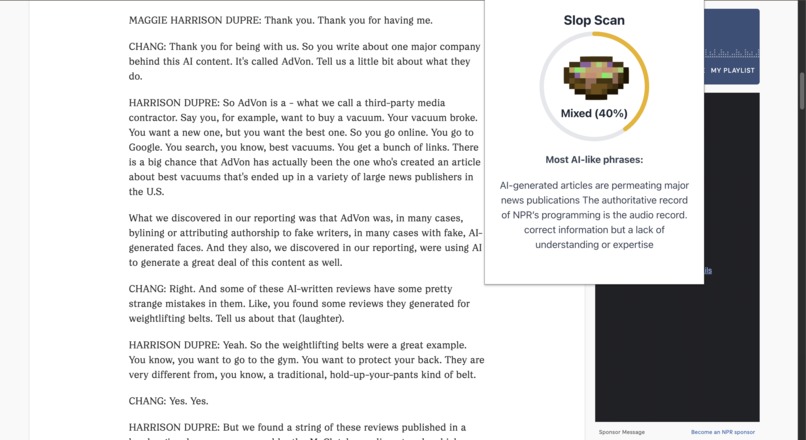
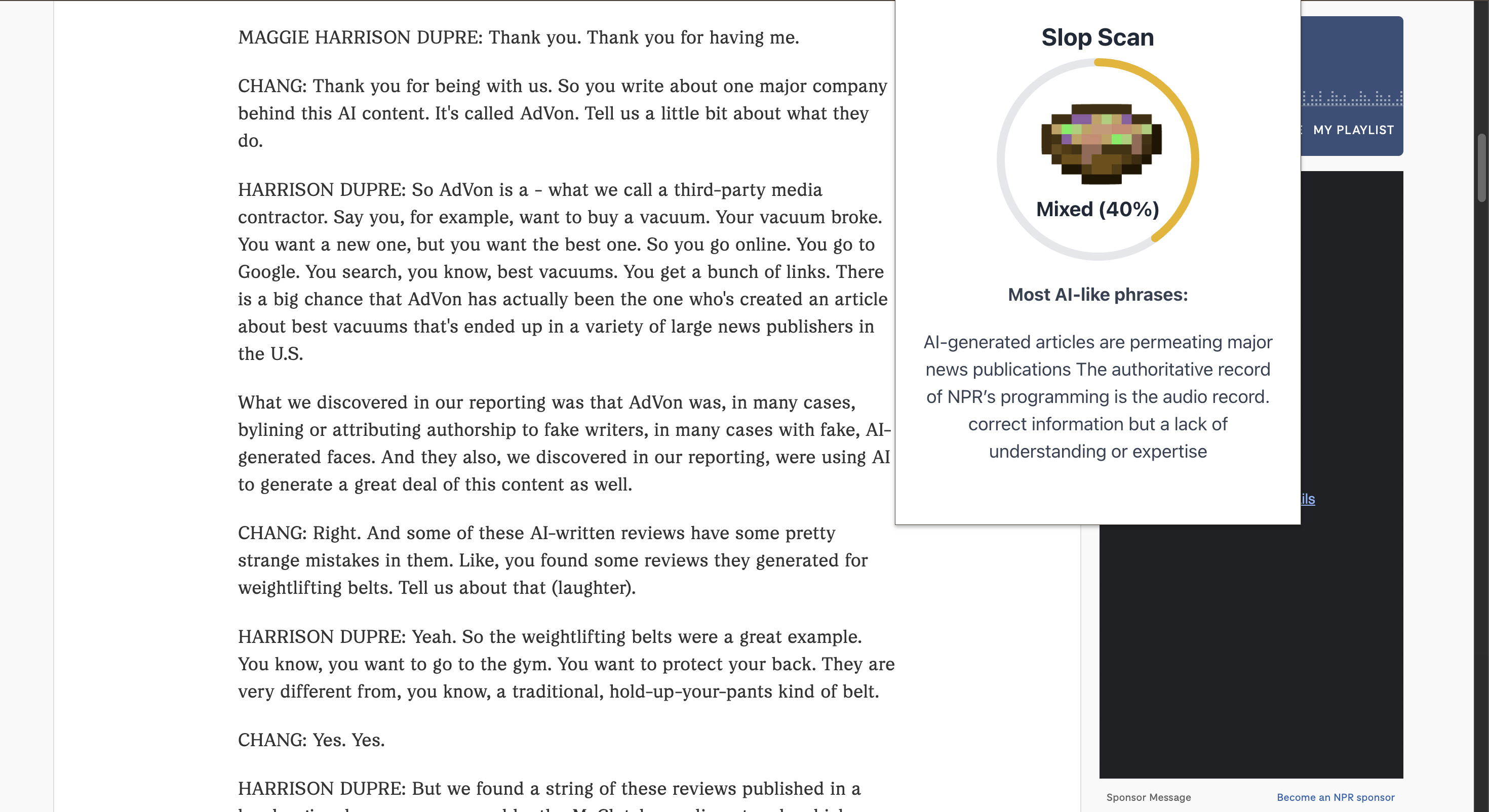
Once you download our Chrome extension, Slop Scan uses a pipeline of scraping, LLMs, and React to scan your pages and display the piece's slop score from 0-100.
How we built it
We used React for the front end, Python for web scraping, and LM based ai detection. When installed, our React frontend will query our backend each time a new page is loaded, converting the scraped data into text and images. These will each go into their own detection pipeline using LM API to generate a score and description, returning it to our front end to be displayed as our slop score.
Challenges we ran into
It was really tough for us to find the right text detection model. We started by trying big-name models such as OpenAI's reberta, but they were either too old or too small to work well. We overcame this challenge through simple trial and error, but these struggles definitely taught us well, as we knew where to look for our image model and were able to implement it far quicker and with less trails.
Accomplishments that we're proud of
We are proud of our perseverance through the many brick walls we faced this hackathon, eachother and our project. We think we have something really special for you guys this year.
What we learned
to avoid hugging face at all costs, always drink more caffeine, and AI detection in respect to both text and images, lots of really interesting information about metadata detection and consistent noise patterns.
What's next for Slop Scan?
Improving the speed and polish would be our next steps. Improving our pipelines by cashing and paying for better ML keys would help optimize the program. We would also like to spend more time on our React and make it look more custom and refined.



Log in or sign up for Devpost to join the conversation.