
Inspiration
Reading out loud — with someone there to correct you — is one of the highest-leverage ways a person ever learns to read or to speak a new language. I do it all the time. And there's a small, maddening thing I kept hitting: when I read alone, I have no idea which sound I just got wrong.
Here's the cruel part. When you misread thorough as furrow, your brain hears the word you meant — not the sound that actually came out. Your own ear quietly autocorrects the exact mistake a tutor would catch. So the slip just… repeats. A kid at the kitchen table, an adult practising literacy in private because reading aloud in front of people is humiliating, an ESL learner drilling pronunciation at home — they all hit the same wall: nobody in the room can tell them which sound slipped, and they can't hear it themselves.
Existing tools work at the word level ("wrong word, try again"). But the feedback that actually changes how you say something lives one level down, at the sound: "/θ/ became /f/." That gap — between the word you meant and the sound you made — is the whole reason I built Slip.
If reading aloud is how we learn, why does the one piece of feedback that fixes it — which sound slipped — disappear the instant nobody's listening?
What it does
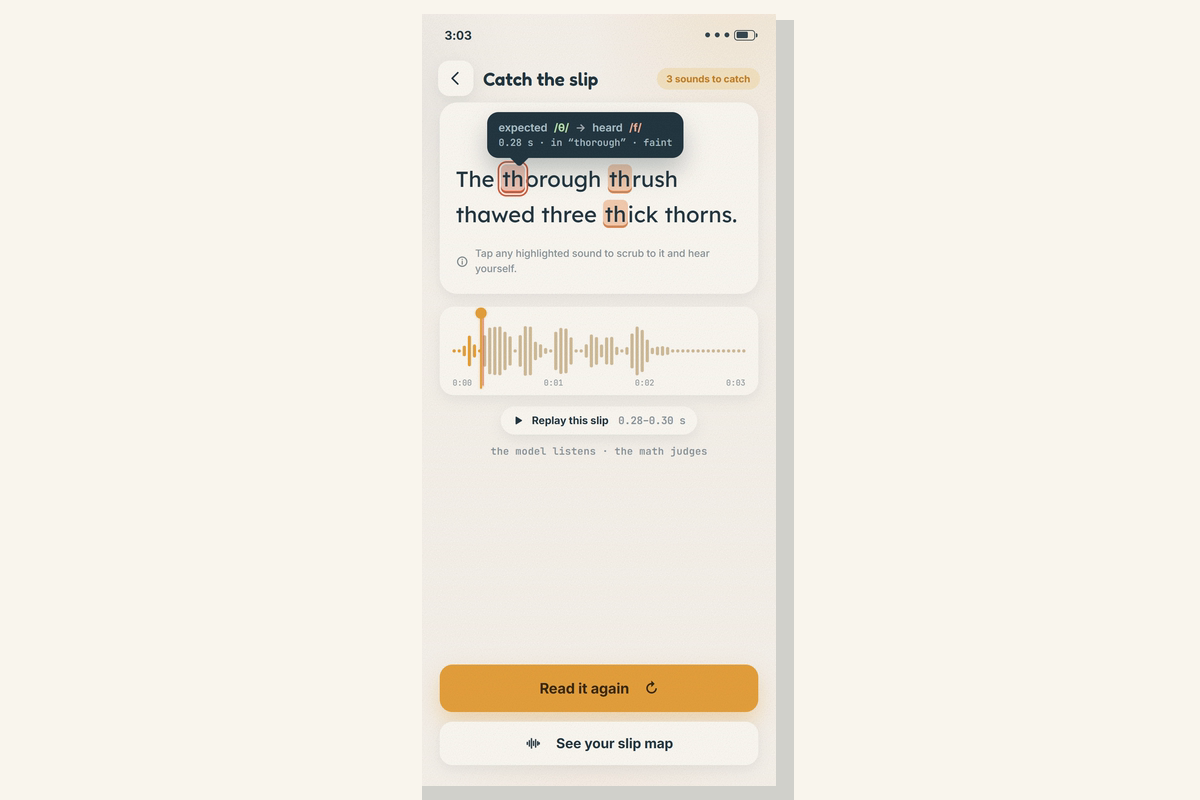
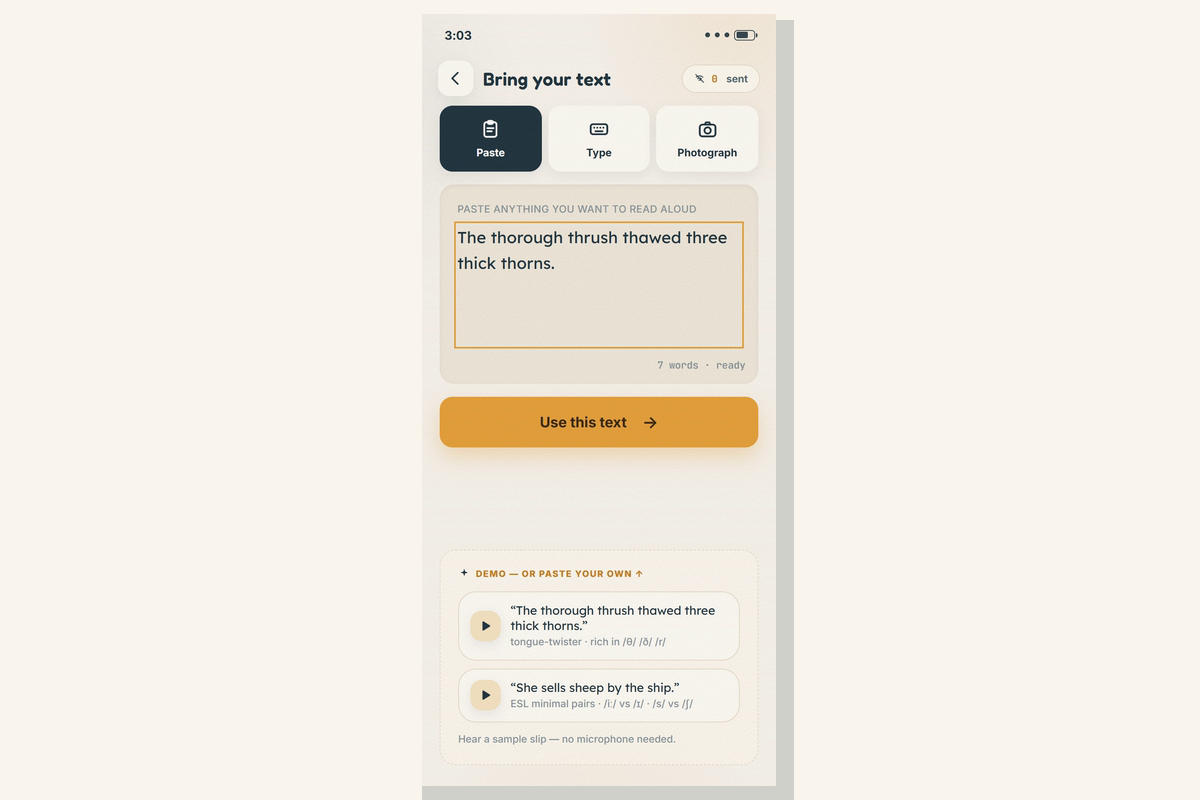
You bring any passage — type it, paste it, or photograph a page — read it aloud once, and Slip re-renders the passage with every slipped sound highlighted. Tap a highlight and it scrubs the waveform to that exact millisecond and replays your own voice at the slip.
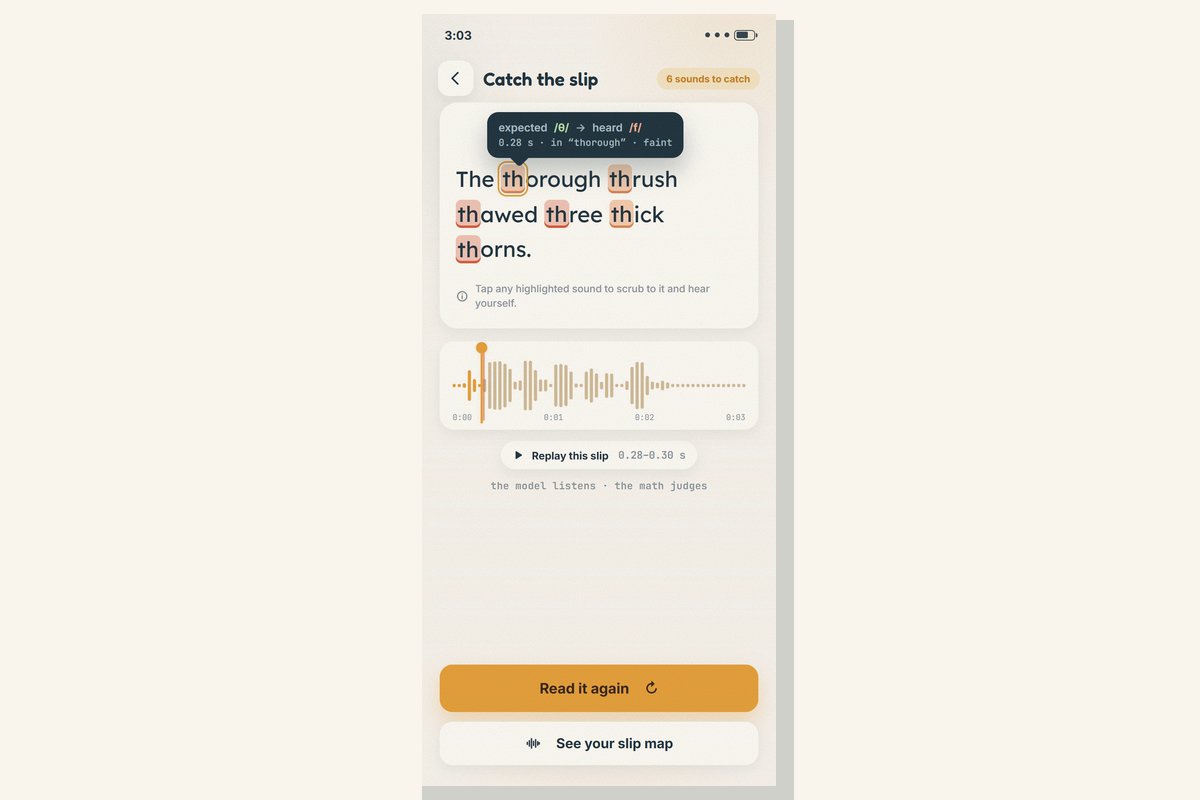
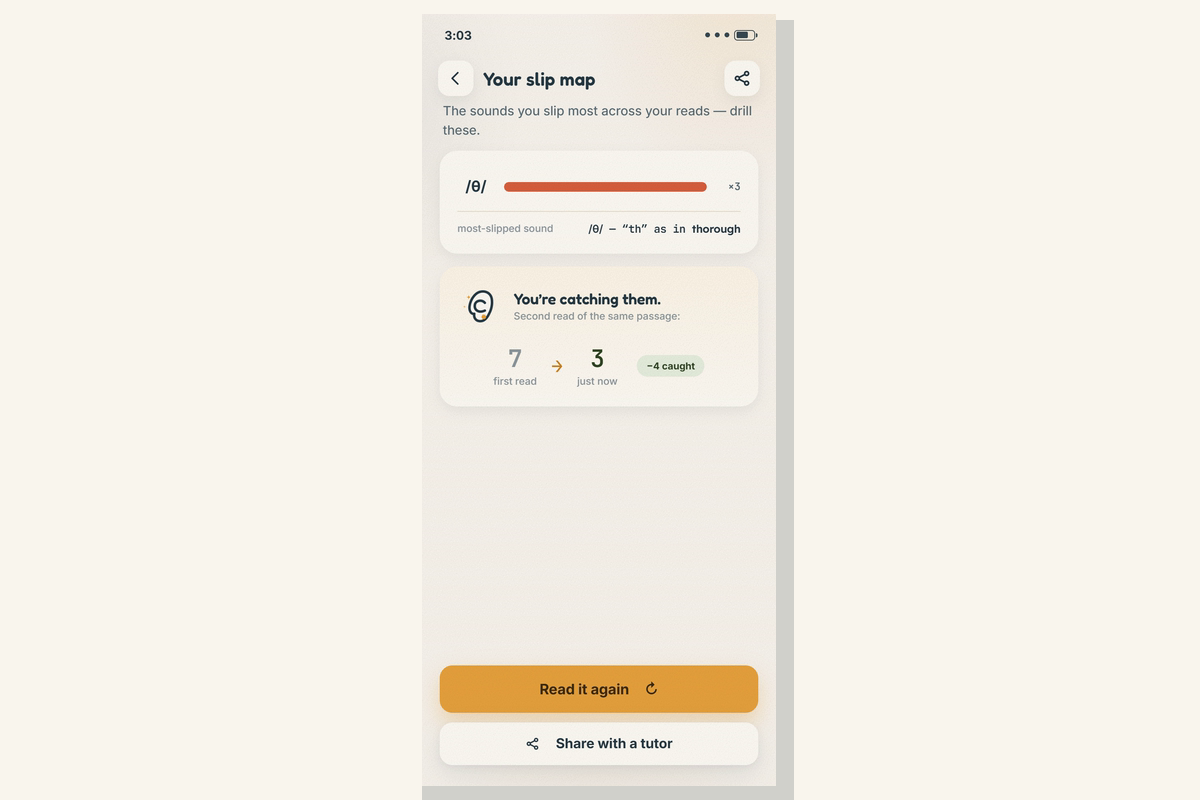
- Catch the slip (the one mechanic): read once → each slipped sound is highlighted on a warm honey→coral ramp; tap one to hear expected /θ/ → heard /f/, with the onset to the millisecond.
- The model listens; the math judges: a real in-browser phoneme neural net produces the acoustics; a deterministic, from-scratch aligner + scorer makes the actual call. Not a chatbot's opinion — math over the audio.
- Read it again: re-record the same line and watch the highlights shrink — in my demo, six slipped sounds drop to three. That visible shrink is the whole practice loop.
- It points at the sound, never the person: feedback glows warm, never stoplight-red, and Slip says plainly it's a practice coach, not a speech diagnosis.
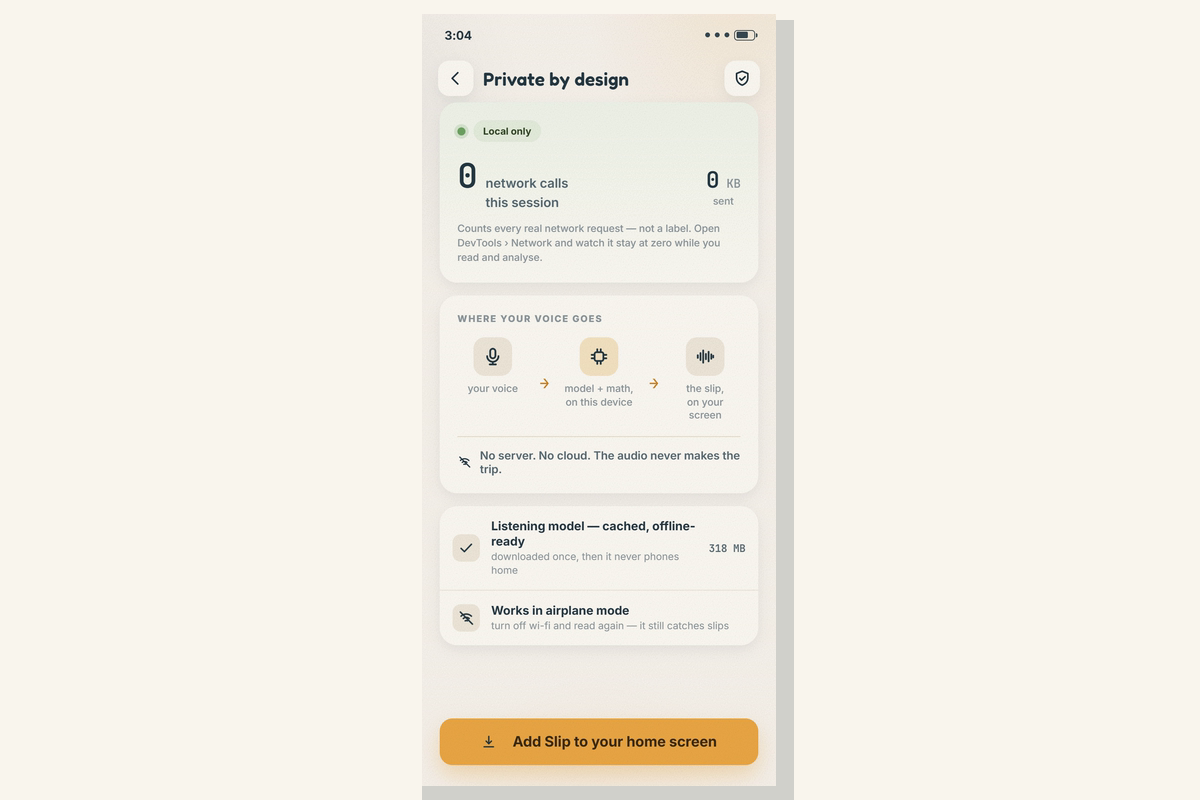
- Private by design: after a one-time model download it runs fully on your device — the audio of a child's voice never leaves the machine, and a live counter shows 0 network calls while you read and analyse.
How I built it
Slip is a single-page Next.js PWA. The whole pipeline — capture, neural net, alignment, verdict — runs client-side in the browser; the heavy ML loads lazily so it never bloats first paint.
The text side (what you're supposed to say). lib/g2p.ts turns your passage into the expected phoneme sequence with espeak-ng compiled to WASM, greedy-matched against the model's own 392-token vocabulary, then anchored back to the on-screen graphemes (so the highlight lands on the "th", not the whole word). Text can also come from a phone photo via tesseract.js OCR, on-device, with per-word confidence flagged, never hidden.
The audio side (what you actually said). lib/audio.ts captures a live MediaRecorder stream, decodes and resamples it to a 16 kHz mono buffer for the model while keeping the full-rate buffer for crisp replay.
The neural net. lib/model.ts runs the public facebook/wav2vec2-lv-60-espeak-cv-ft checkpoint — a ~315M-parameter wav2vec2-LARGE that emits IPA phonemes, not words — in the browser via transformers.js / ONNX Runtime Web (the onnx-community ONNX export, int8, ~318 MB cached once). I load it through AutoModelForCTC to get the raw frame-wise logits, not a transcript — the entire money shot depends on the posterior matrix, not on decoded text.
The verdict (deterministic). lib/dsp.ts does a numerically-stable log-softmax; lib/align.ts is a CTC forced aligner I wrote from scratch in TypeScript — the trellis + Viterbi backtrace from the torchaudio forced_align algorithm, the universal 2L+1 blank-interleaved form — time-aligning the expected phonemes to the audio frames; lib/gop.ts computes a per-phoneme Goodness-of-Pronunciation (GOP-CTC) score over the aligned posteriors → which sound slipped, expected → heard, the onset on the 20 ms frame grid, and a severity. lib/analyze.ts orchestrates it into the highlights you tap.
Honest engineering seam. There's no turnkey browser phoneme model, so the in-browser path is the headline; an opt-in FastAPI inference seam (services/infer) returns the identical logits so the identical TS math runs on weak devices — off by default, and it degrades honestly (it never fabricates a verdict). Cross-origin isolation (COOP: same-origin, COEP: credentialless) unlocks multi-threaded WASM for the model; it falls back to single-thread where unavailable.
Challenges I ran into
- No phoneme model ships for the browser. Every turnkey browser speech model is word-level, and a word-level model literally cannot say "/θ/ became /f/". Fix: take the public espeak-phoneme wav2vec2 checkpoint, use its ONNX export, and load it through
AutoModelForCTCso I get the raw posteriors instead of a transcript. - A language model would autocorrect the exact mistake I'm trying to surface. Pipe audio through a normal speech-to-text decoder and it cheerfully writes "thorough" even when you fumbled it — erasing the slip. Fix: never decode to text. The verdict is pure math (forced alignment + GOP) over the acoustic posteriors. The model listens; the math judges.
- Writing a forced aligner from scratch. Getting the CTC trellis right — the
2L+1blank-interleaved lattice and the Viterbi backtrace — so phoneme onsets land within ~one 20 ms frame took real care; an off-by-one in the blank interleaving silently smears every timestamp. - Calibrating "a slip" honestly. GOP scores aren't examiner-grade. I calibrated the severity thresholds against real reads (clearly-correct phones score around −0.1…−3.5, genuine substitutions around −6…−8, so a "good" cutoff near −4 separates them) and exposed a sensitivity slider — rather than pretending a single magic cutoff is the truth.
Accomplishments that I'm proud of
- A real phoneme model running in the browser — ~318 MB, cached once, then 0 network calls; airplane-mode demonstrable.
- A from-scratch CTC forced aligner + GOP scorer in TypeScript — the antithesis of a GPT wrapper, and the thing a fake provably can't reproduce on arbitrary input.
- The click-and-hear money shot works live on a sentence nobody prepared — type any line, fumble any sound, and it lands on the exact phoneme and replays your own error to the millisecond.
- Honesty as the brand: Slip says out loud that it's a coach, not a clinician, and shows its own accuracy plainly (below).
What I learned
- Where the posteriors are computed is the only thing that's negotiable — what they mean isn't. Browser or server, the same deterministic math makes the call.
- The honest number is more persuasive than a hyped one. GOP-CTC lands around 0.44–0.46 phone-level correlation where expert humans agree at about 0.55 on SpeechOcean762 — useful and directionally right, not human-parity. Saying so is what makes the rest believable.
- For a vulnerable reader, the feedback's tone is a feature, not decoration — warm severity, never alarm-red, "point at the sound, never the person."
What's next for Slip
- Accuracy: per-speaker calibration and confidence-aware highlighting so faint detections read as faint.
- Reach: more target languages/accents (the checkpoint is multilingual); a Spanish/Mandarin pass for ESL symmetry.
- The tutor force-multiplier: the on-device share-card (passage + slip map + timestamps, nothing uploaded) so one volunteer tutor can "sit beside" 30 readers asynchronously.
- Distribution: deeper PWA/offline polish so it installs and runs on a borrowed laptop with flaky wifi.
The bigger picture
One-on-one corrective reading feedback is a privilege most literacy and ESL learners never get — a tutor's time is scarce, classrooms run 30 deep, and the people who'd benefit most often practise alone, out of embarrassment, exactly when feedback disappears. Slip turns any phone or laptop with a microphone into the patient ear that points at the sound — free, private, offline, and on a device you already own. It doesn't replace a teacher. It lets the one teacher in a 30-kid room be beside all 30 at once.
Built With
- css3
- ctc-forced-alignment
- espeak-ng
- fastapi
- goodness-of-pronunciation
- html5
- huggingface
- indexeddb
- mediarecorder
- next.js
- onnxruntime-web
- pwa
- react
- service-worker
- tesseract.js
- transformers.js
- typescript
- vercel
- wav2vec2
- web-audio-api

Log in or sign up for Devpost to join the conversation.