-
-

-
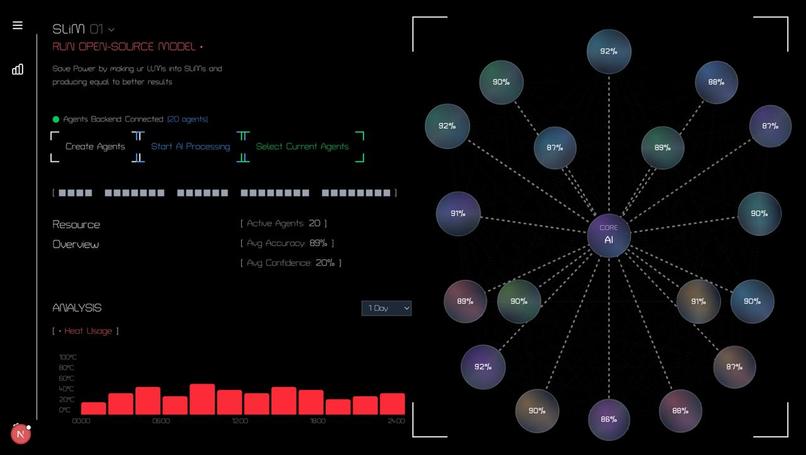
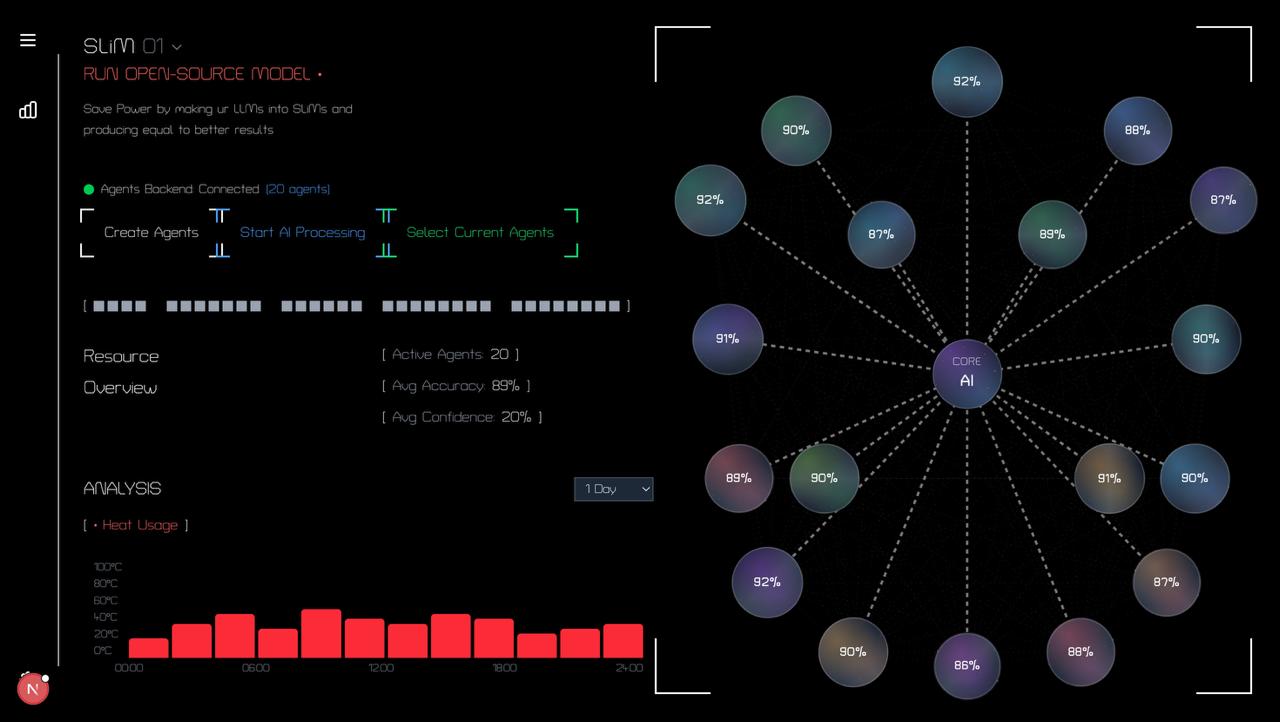
Dashboard
-
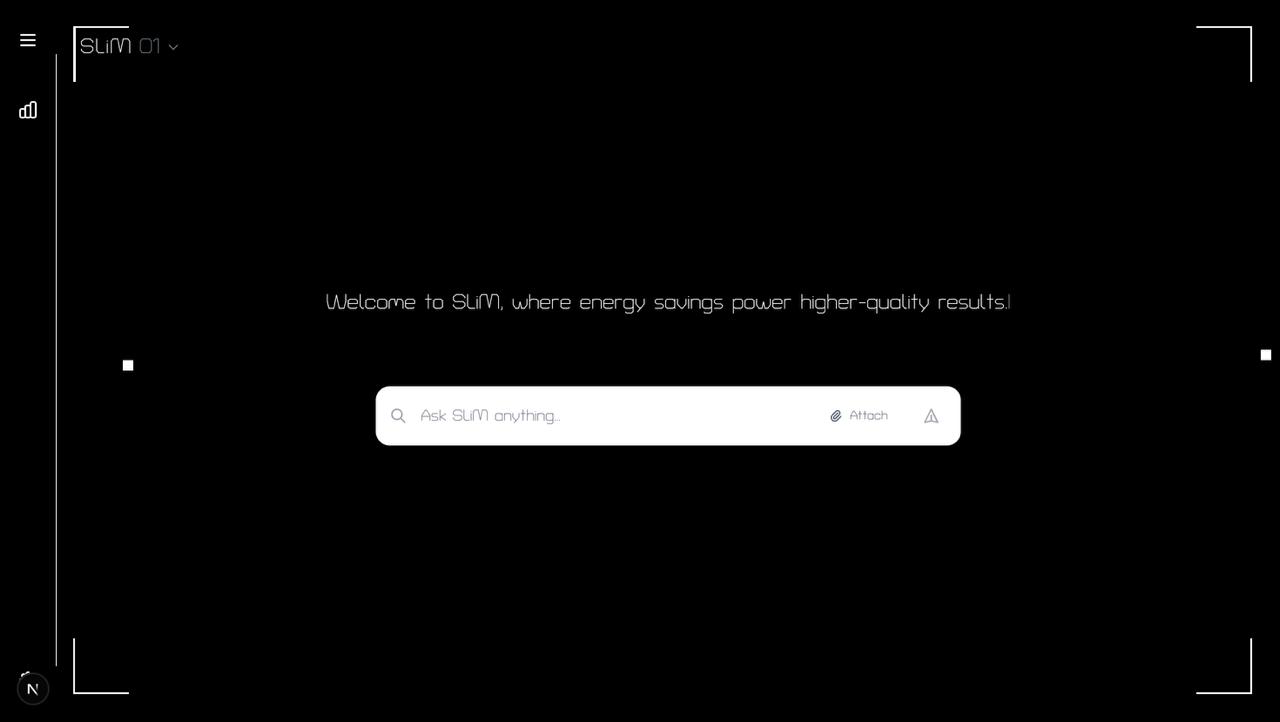
Landing Page
-
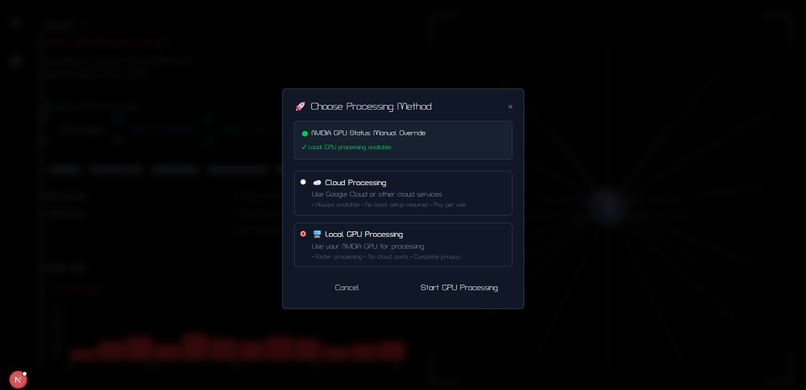
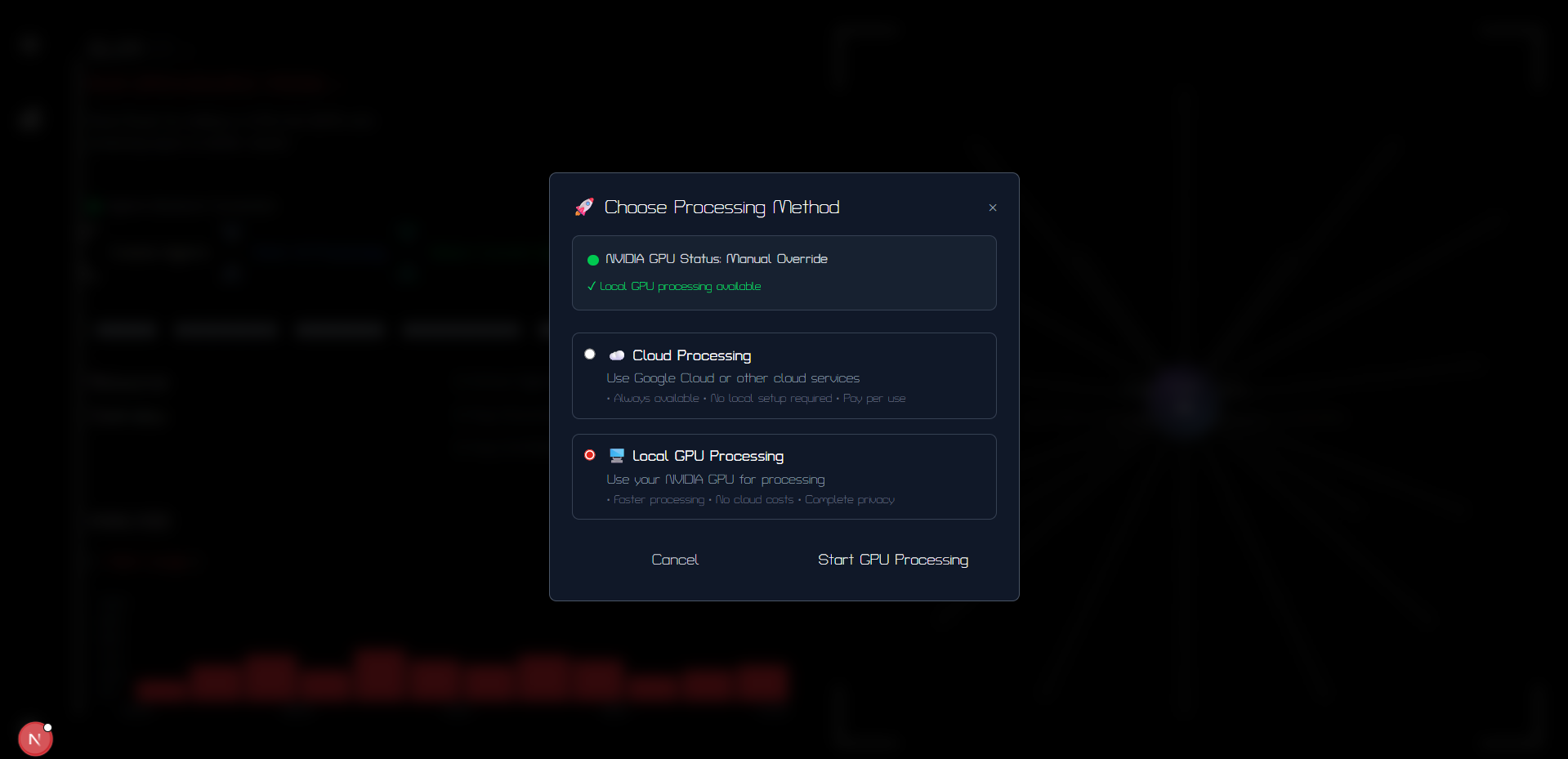
CUDA GPU Decider
-
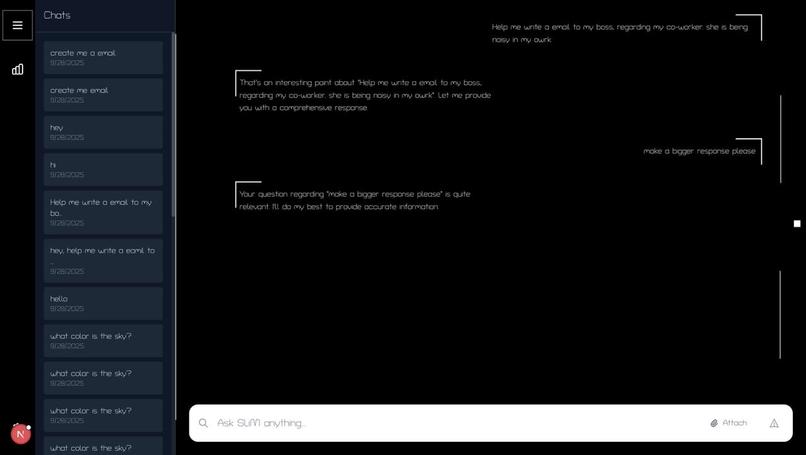
LLM

Inspiration
Large Language Models are powerful, but expensive and slow to call repeatedly. Teams often ask the same kinds of questions (emails, bug fixes, summaries), wasting tokens and compute. We wanted to build a system that learns from repetition, automatically training a small language model to handle common queries while routing complex tasks back to a larger LLM.
This inspired SLiM (Smart LLM Router + Incremental Model trainer) — a framework that reduces cost and latency by auto-promoting common queries into a small specialized model.
What it does
- SLiM routes user prompts to:
- LLM (Gemini) when no specialized small model exists, and starts the SLM specialization process.
- SLM (small model) if one has already been trained for that topic. It also:
- Detects repetition in LLM inputs.
- Automatically queues lightweight training jobs for new or existing SLMs.
- Updates the model registry and seamlessly reroutes future prompts to the trained sLM. Result: faster, cheaper responses that improve over time.
How we built it
Backend: FastAPI (Python), Docker, Google Agents ADK Routing Logic: Embeddings + cosine similarity, keyword fallback Databases: PostgreSQL for persistence, Redis + RQ for training jobs Models: Google Gemini for LLM, DistilBERT Transformers / lightweight PyTorch models for base SLMs, LoRA model training with CUDA. Observability: Prometheus metrics, structured logging Deployment: Docker Compose + Hugging Face Spaces (for easy sLM hosting)
Challenges we ran into
- Slow training time of SLM's when threading and training. We resorted to using CUDA for the specialized training and LoRA models to further decrease the computation requirement.
- Docker builds were slow due to large ML dependencies. We had to create a lightweight dev mode with fake embeddings to test quickly.
- Managing asynchronous jobs across API + worker required careful handling of Redis queues and database migrations.
- Designing a fallback strategy so the system never fails, always routing back to LLM if the sLM is unavailable.
Accomplishments that we're proud of
- Built a production-style router in a short time.
- Achieved automatic model promotion from repeated queries → trained sLMs.
- Created a clean, extensible architecture that others can plug into their own LLM workflows.
What we learned
- How to design a model routing layer that balances cost and performance.
- How to use repetition detection (similarity scores) to drive incremental fine-tuning.
- The importance of a clean model registry for managing multiple versions of sLMs.
- How to quickly bootstrap training with synthetic datasets.
What's next for SLiM
- Add a UI dashboard to view training jobs, model registry, and routing decisions.
- Integrate more evaluation metrics to auto-promote/demote sLMs.
- Explore deployment on Azure Container Apps for always-available, low-latency sLM serving.
- Integrating aditional model types for a more diverse availability to our users.
Built With
- alembic
- docker
- fastapi
- google-gemini-api
- http
- httpx
- hugging-face-spaces
- numpy
- postgresql
- prometheus
- python
- pytorch
- redis
- rq
- scikit-learn
- sentencetransformers
- sqlalchemy
- sqlite
- uvicorn











Log in or sign up for Devpost to join the conversation.