




SilentWitness

One-line pitch
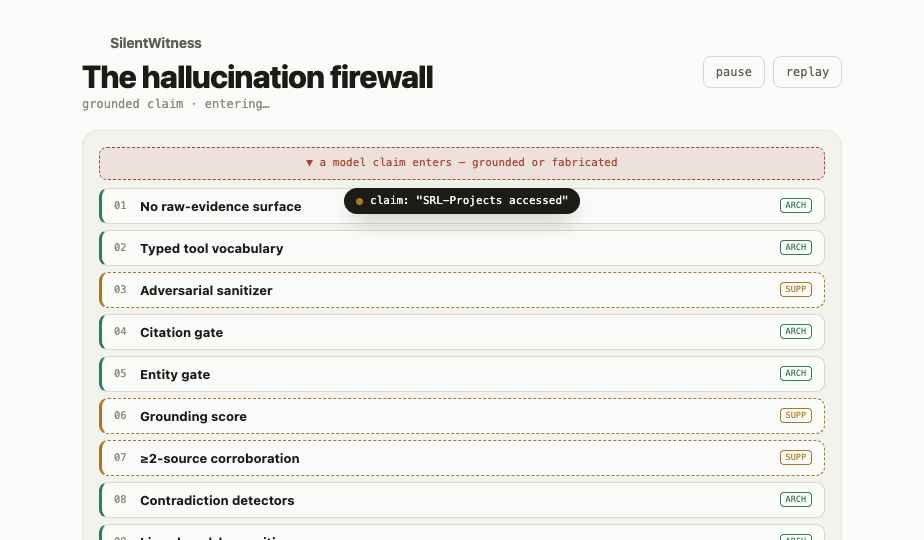
SilentWitness is a hypothesis-first DFIR investigator that turns forensic tool output into a defensible audit trail: every report claim must point back to the exact tool output that produced it.
Links
- Demo video: vimeo.com/1201573890
- Live docs: switness.xyz
- Quick start: switness.xyz/docs/quickstart
- Try it out: switness.xyz/docs/try-it-out
- Architecture: switness.xyz/docs/architecture
- Accuracy report: switness.xyz/docs/accuracy-report
- Starter cases: switness.xyz/docs/starter-cases
- GitHub: github.com/Blockchain-Oracle/silentwitness
What it does
DFIR analysts lose too much time copying terminal output into reports and trying to remember which command proved which claim. SilentWitness keeps that provenance attached while the investigation is still happening.
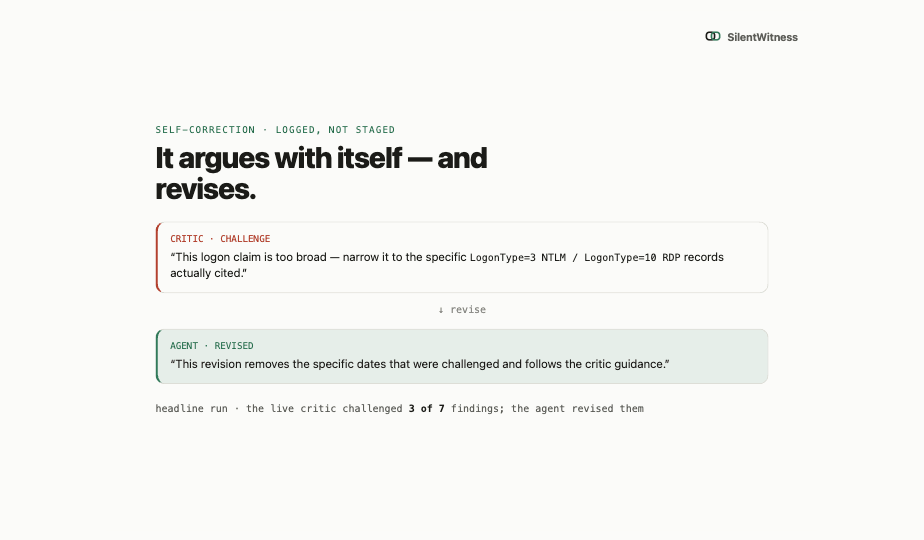
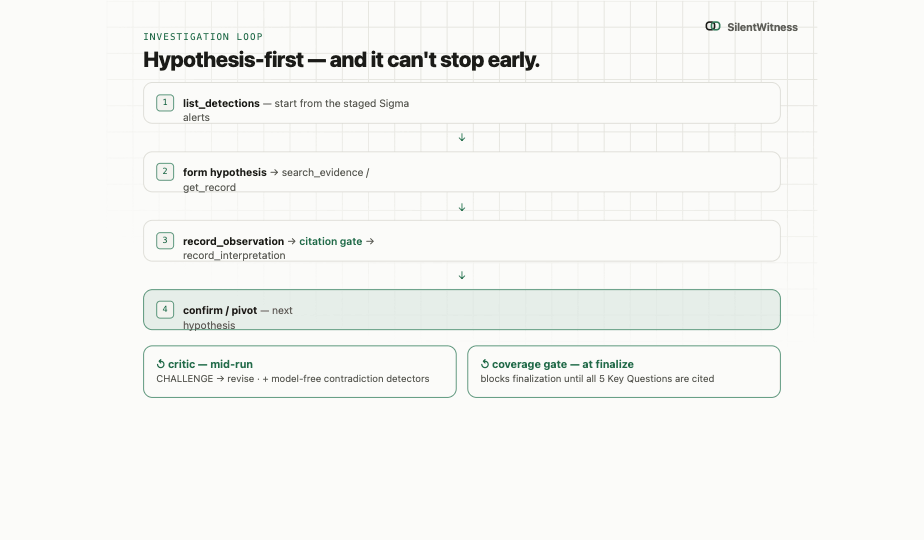
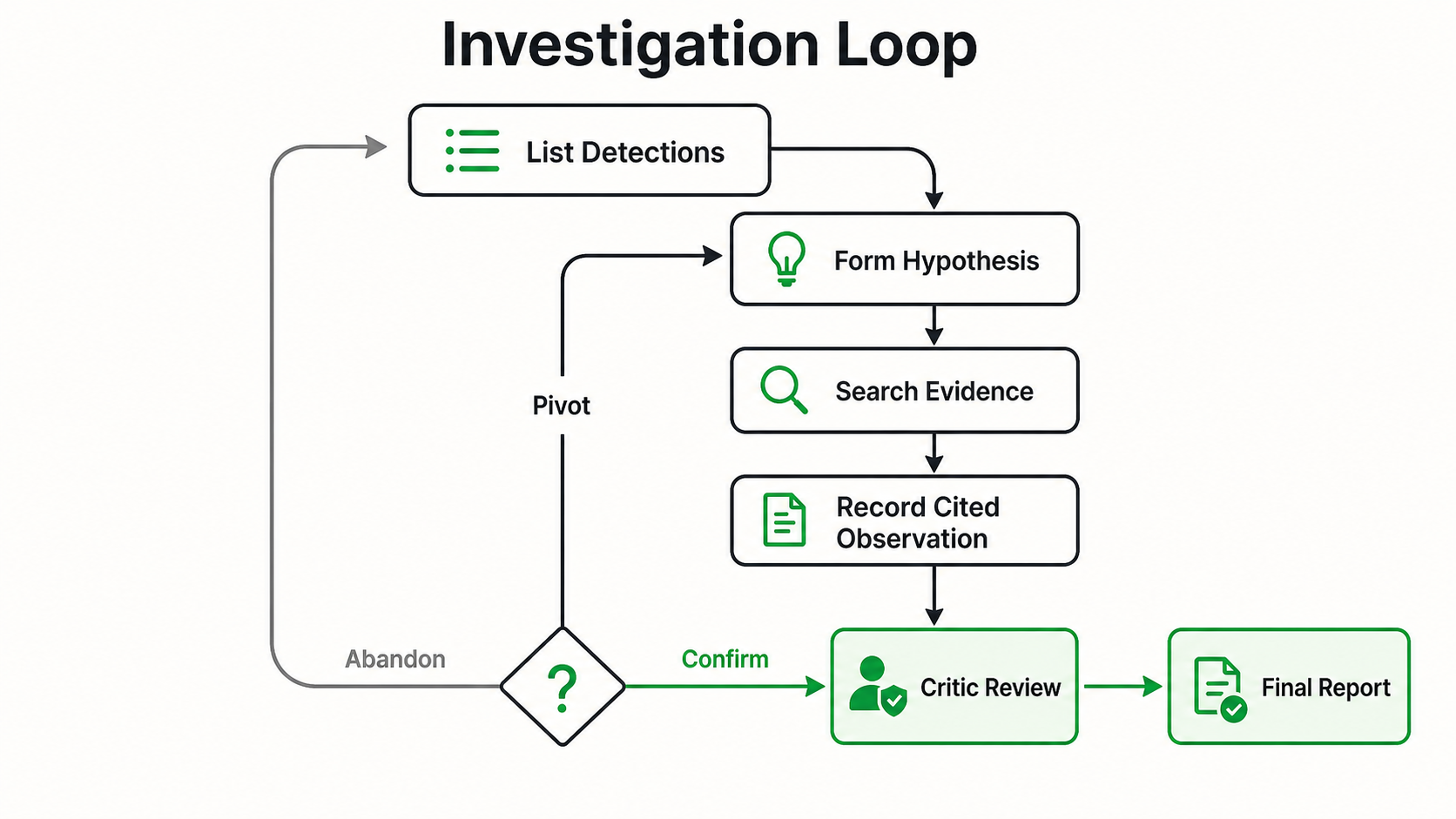
The agent works from a hypothesis stack. It registers evidence, prepares a case, indexes forensic artifacts, investigates with bounded MCP tools, verifies findings against stored output, and exports a report. A citation gate rejects any observation whose cited span cannot be found in the audit ledger. An entity gate rejects claimed process names, paths, hashes, IPs, or MAC addresses unless those entities appear in the cited evidence text.
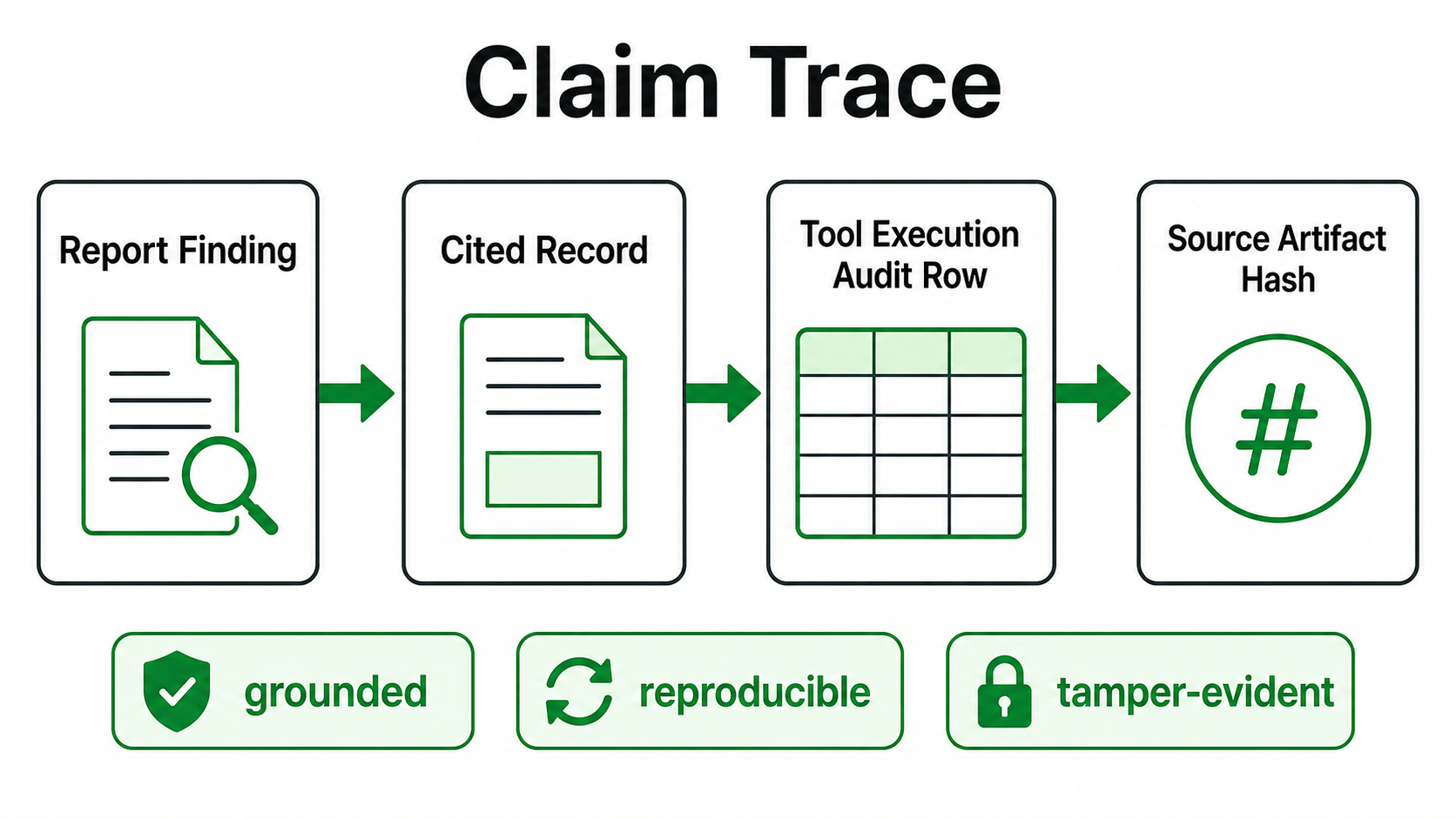
The result is a report where each finding carries a verification reference, not a loose narrative paragraph. The analyst can audit the chain from conclusion back to command output.
Visual overview
Inspiration
The SANS Find Evil! challenge is a strong fit because the work is not just "can an agent run forensic tools?" The harder question is whether an agent can produce findings that a senior analyst can review, challenge, and reproduce.
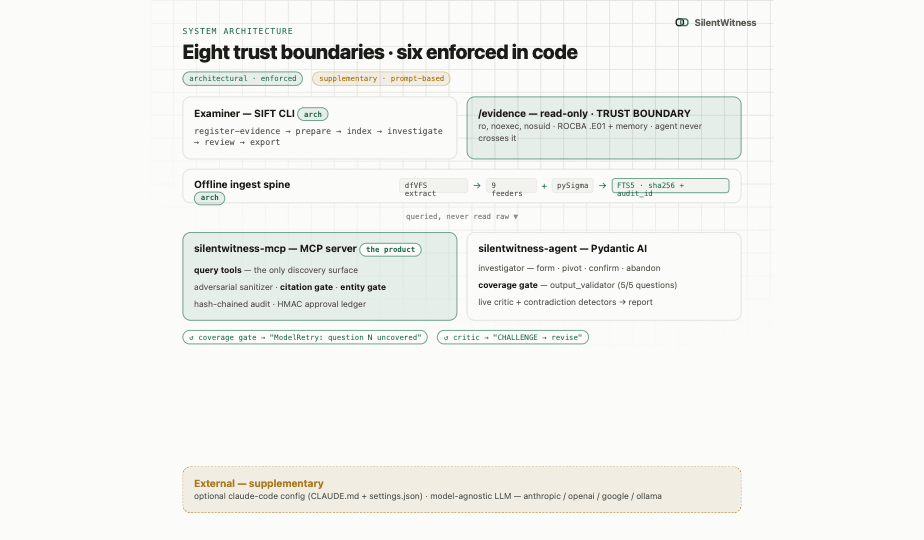
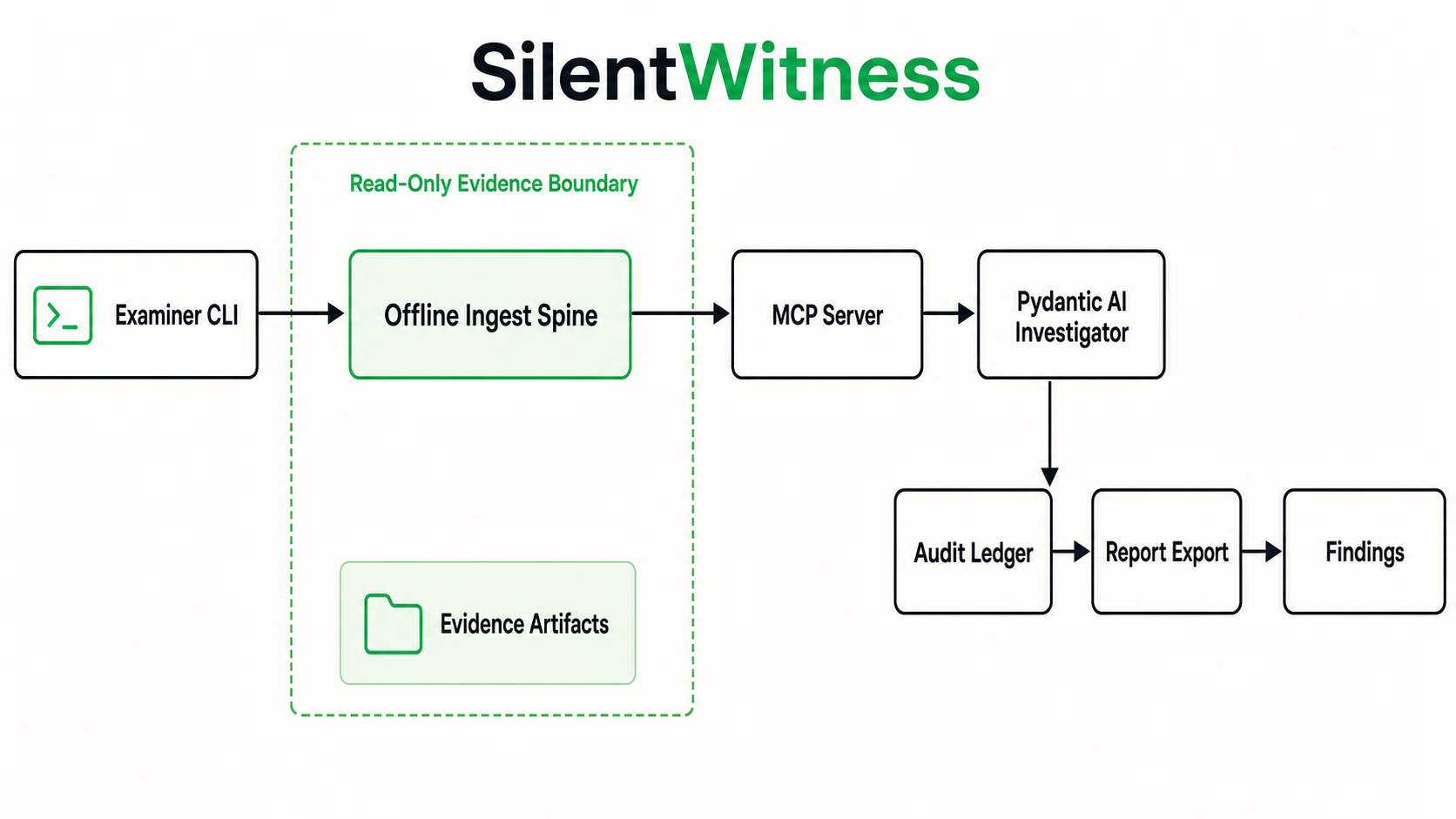
Protocol SIFT 2026 showed that AI agents can drive the SIFT workstation. SilentWitness adds the missing control layer: evidence registration, offline ingest, bounded tool access, signed audit rows, citation verification, entity verification, and report export.
How we built it
| Layer | Stack |
|---|---|
| Custom MCP server | mcp>=1.23.0,<2.0, FastMCP, Pydantic v2 envelopes |
| Reference agent | pydantic-ai>=1.105.0,<2.0.0, model-agnostic across OpenAI, Anthropic, Google, and Ollama |
| CLI | Typer and Rich commands for initialize, register, prepare, index, investigate, verify, export, and starter-case download |
| Forensic tooling | Volatility 3, Hayabusa, Chainsaw, Zeek, Suricata, and Eric Zimmerman tools through the offline ingest spine |
| Audit and integrity | HMAC-SHA256 ledger records, PBKDF2-SHA256 key derivation, read-only evidence mounts, and per-case audit files |
| Reports | Markdown/PDF export with verification references back to the audit ledger |
| Site and docs | Next.js, Fumadocs, Pagefind, Vercel, and the public docs at switness.xyz |
The architecture keeps raw evidence behind the ingest boundary. The model does not free-read a disk image or memory image. It asks the MCP server for indexed, bounded, citable records, then records findings through typed envelopes that the gates can validate.
Challenges we ran into
- SIFT 2026 tool drift. Volatility plugin paths and Zimmerman tool locations changed across current SIFT builds, so the repo pins the verified paths and checks tool behavior instead of assuming old command names still work.
- Noisy forensic output. Tool banners, timestamps, path separators, and CSV formatting can change between runs. SilentWitness normalizes output before hashing and verification so a claim is checked against stable evidence text.
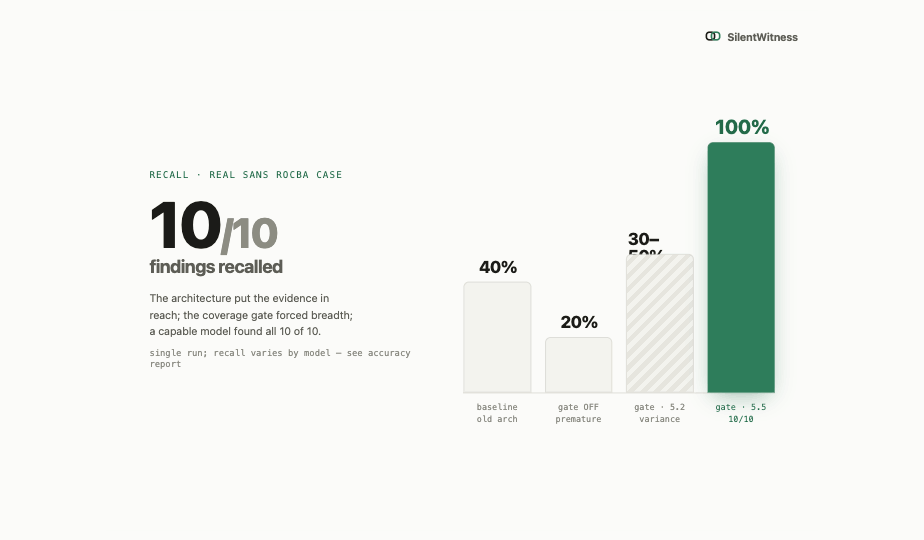
- Keeping claims honest. The easiest demo would be a polished story. The useful demo is a reproducible chain: evidence in, tools run, observations gated, findings exported, and misses documented in the accuracy report.
- Submission polish without hiding limits. The public docs include the accuracy report and starter-case notes because judges should be able to see what works, what still varies, and how to rerun the claims.
Accomplishments
- Built a Custom MCP Server and Pydantic AI reference investigator around real forensic tooling.
- Added citation and entity gates that reject malformed observations before they become findings.
- Added starter-case catalog and download commands so users do not need to call helper scripts directly.
- Published a Vercel documentation site with quickstart, architecture, starter cases, accuracy report, and demo-facing walkthroughs.
- Verified the codebase with the unit, integration, docs sync, and site typecheck suites before submission.
What we learned
The main lesson is that provenance has to be part of the system design. A prompt can ask for careful citations, but code has to enforce whether the citation actually exists and whether the named artifact appears in the cited output.
We also learned that public forensic cases are tricky for evaluation. Some answers are widely indexed online, so a model can appear correct by memory. SilentWitness treats that as a risk and pushes evaluation toward evidence-present spans, reproducible shell checks, and documented residual gaps.
What's next
- Add live-host triage through a Velociraptor backend while keeping the same citation envelope.
- Add multi-case queueing so analysts can stage several investigations and review bounded results later.
- Add cloud-forensics backends for AWS, Azure, and GCP audit trails.
- Expand the adversarial synthetic case work so evaluations are less exposed to memorized public answers.
Built with
python, pydantic-ai, mcp, fastmcp, typer, rich, volatility-3, sift-workstation, docker, weasyprint, next.js, fumadocs, pagefind, vercel
Try it yourself
Start with the public walkthrough: switness.xyz/docs/try-it-out. It covers the SIFT path, Docker path, starter cases, the Nitroba smoke test, and the command flow from initialize through export.
License
MIT. Third-party attribution details are in the repository notices.

Log in or sign up for Devpost to join the conversation.