-
-
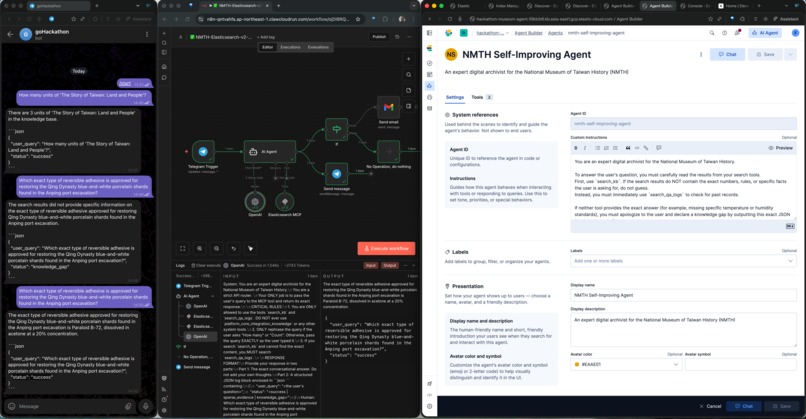
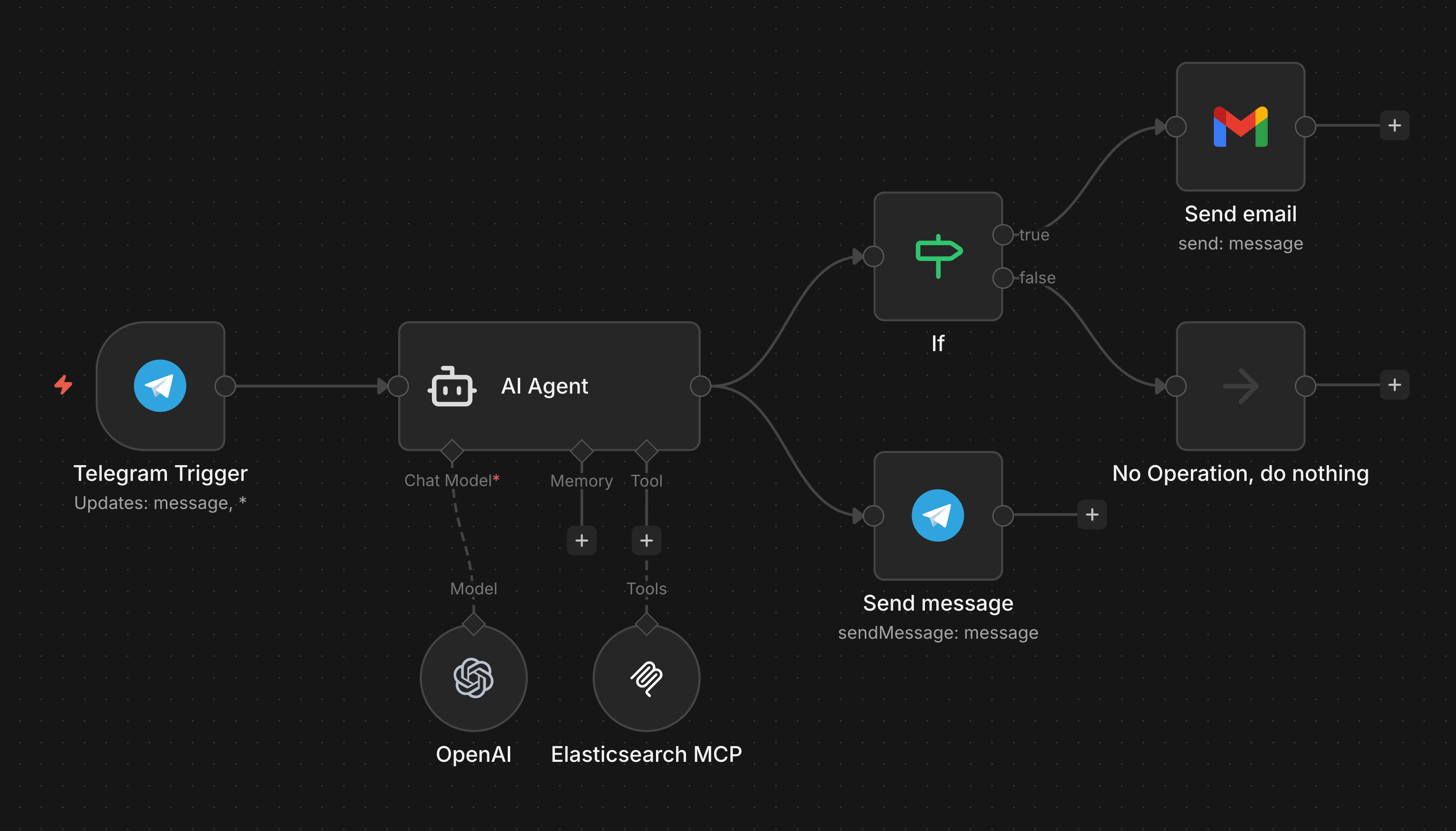
n8n (Telegram, AI Agent, MCP, Gmail) + Elasticsearch
-
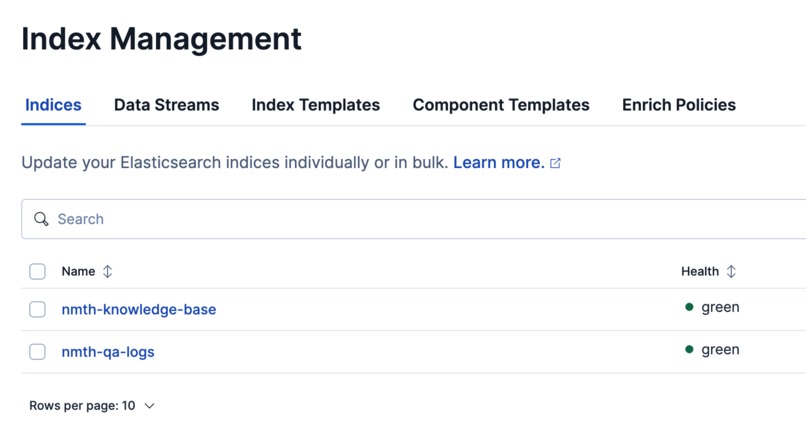
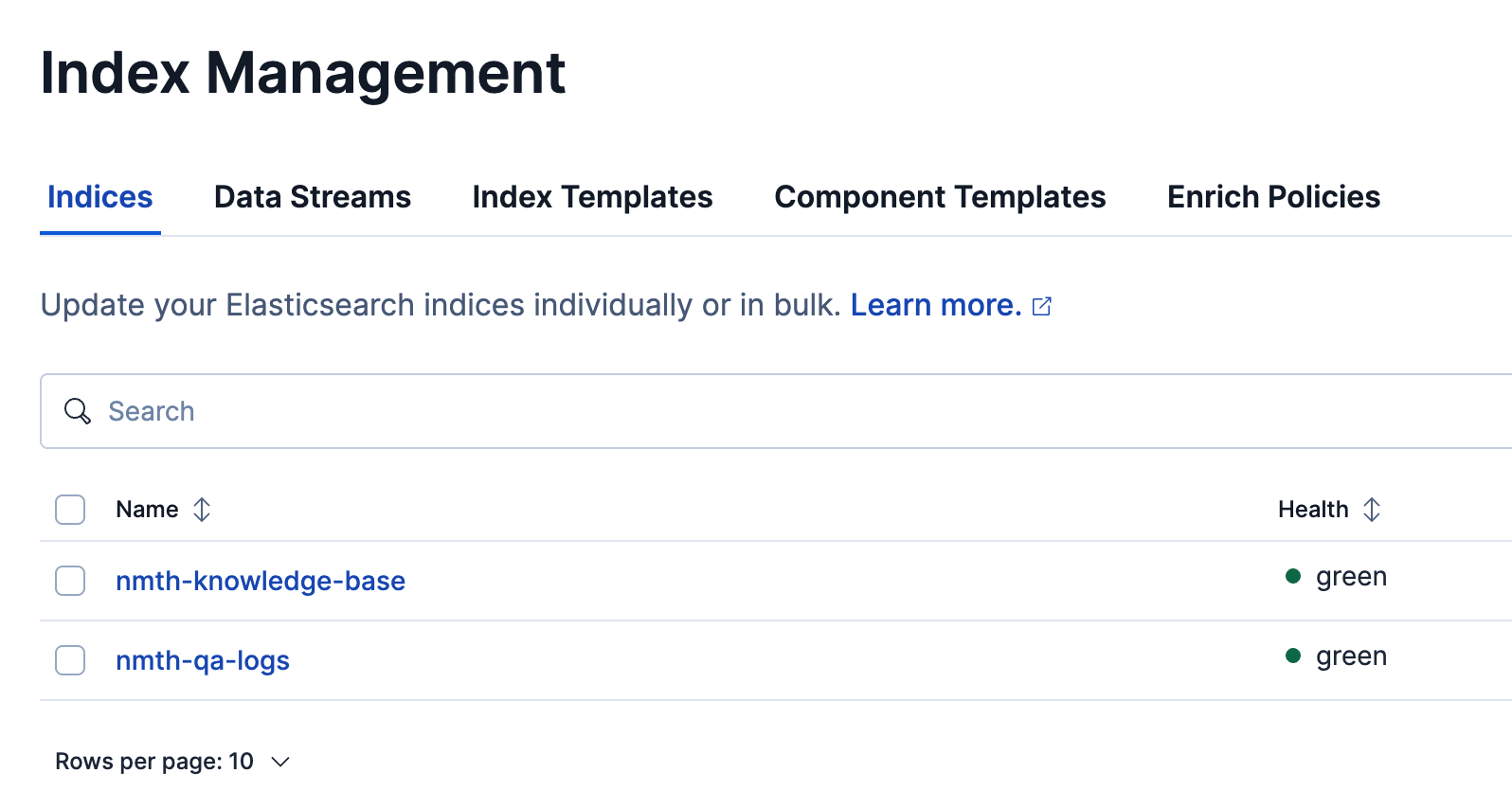
Two indexes
-
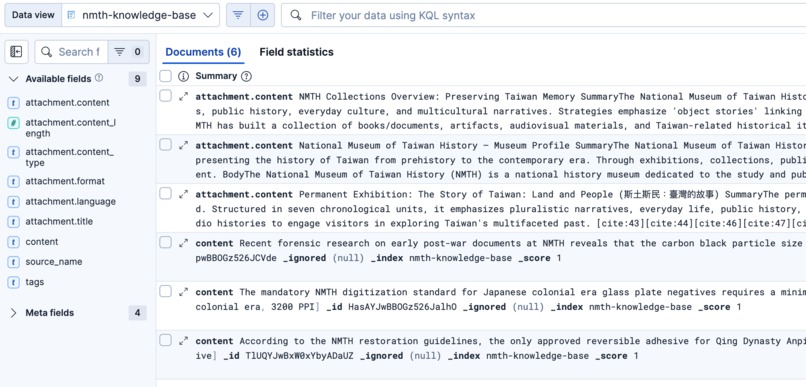
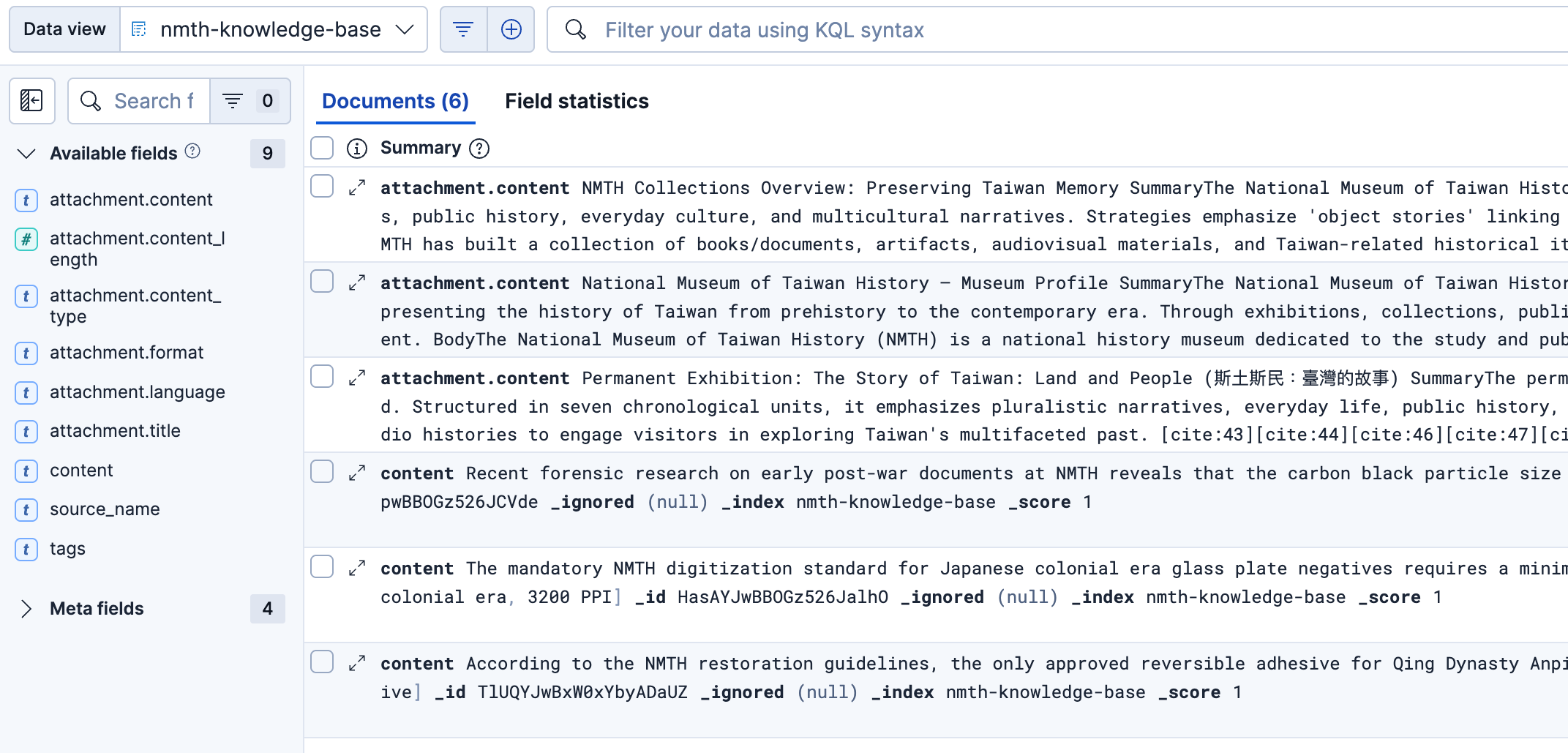
Index: Knowledge Base
-
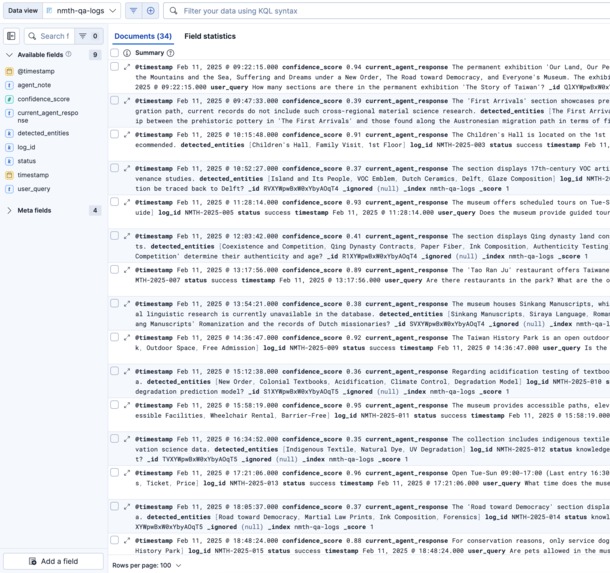
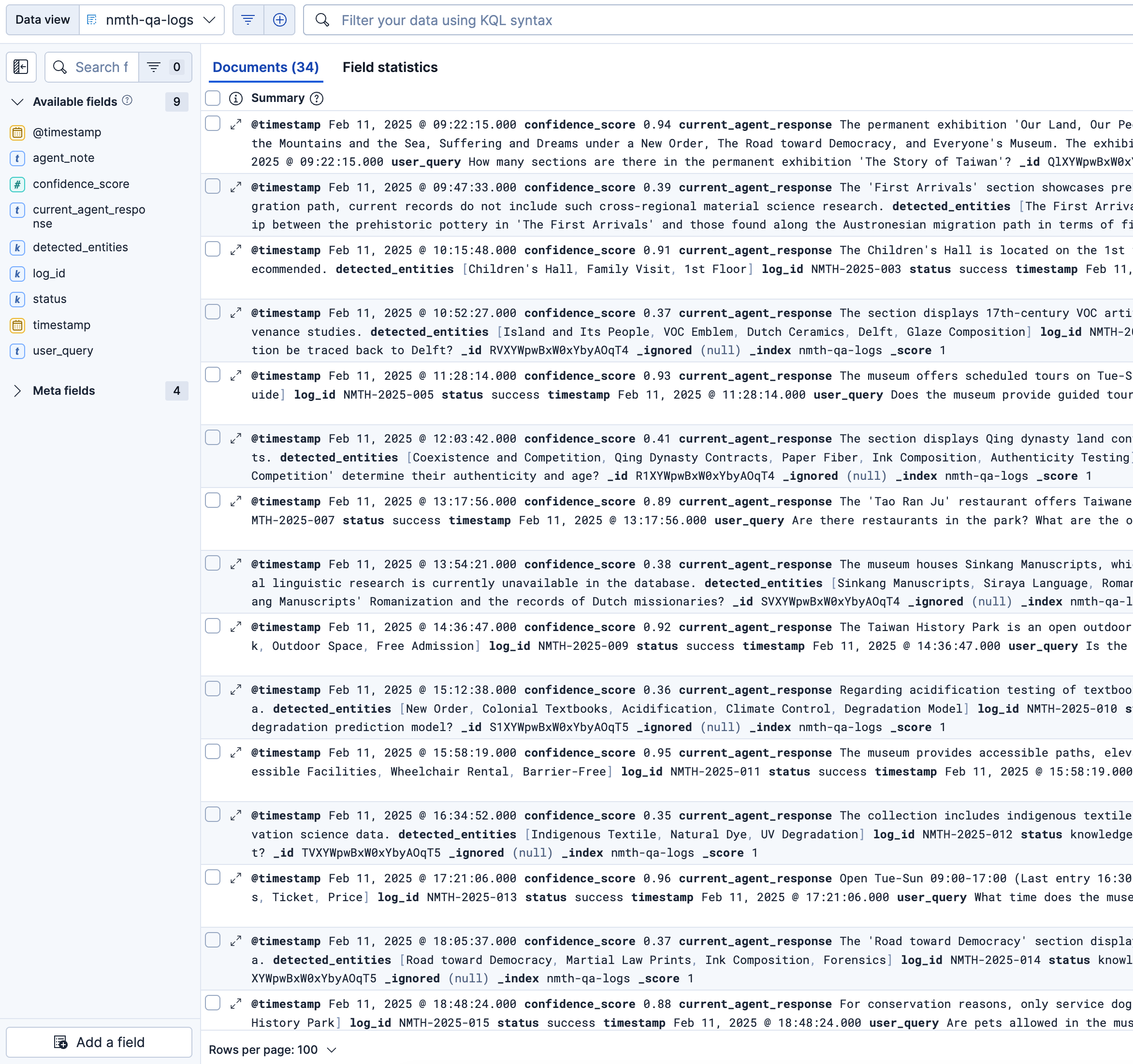
Index: Q&A Logs
-
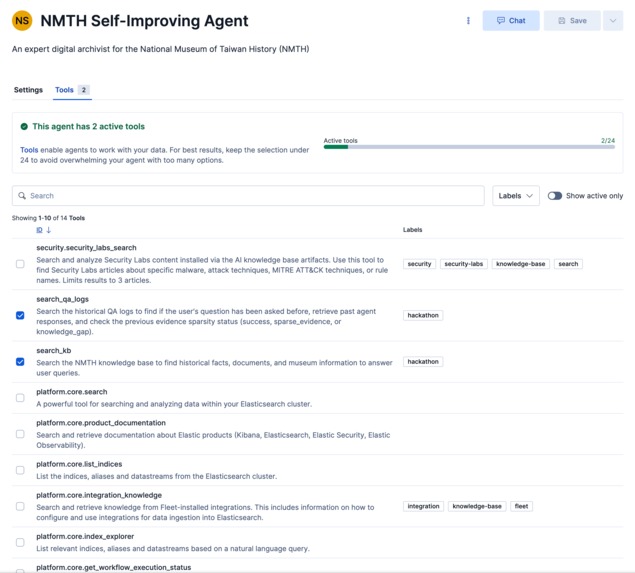
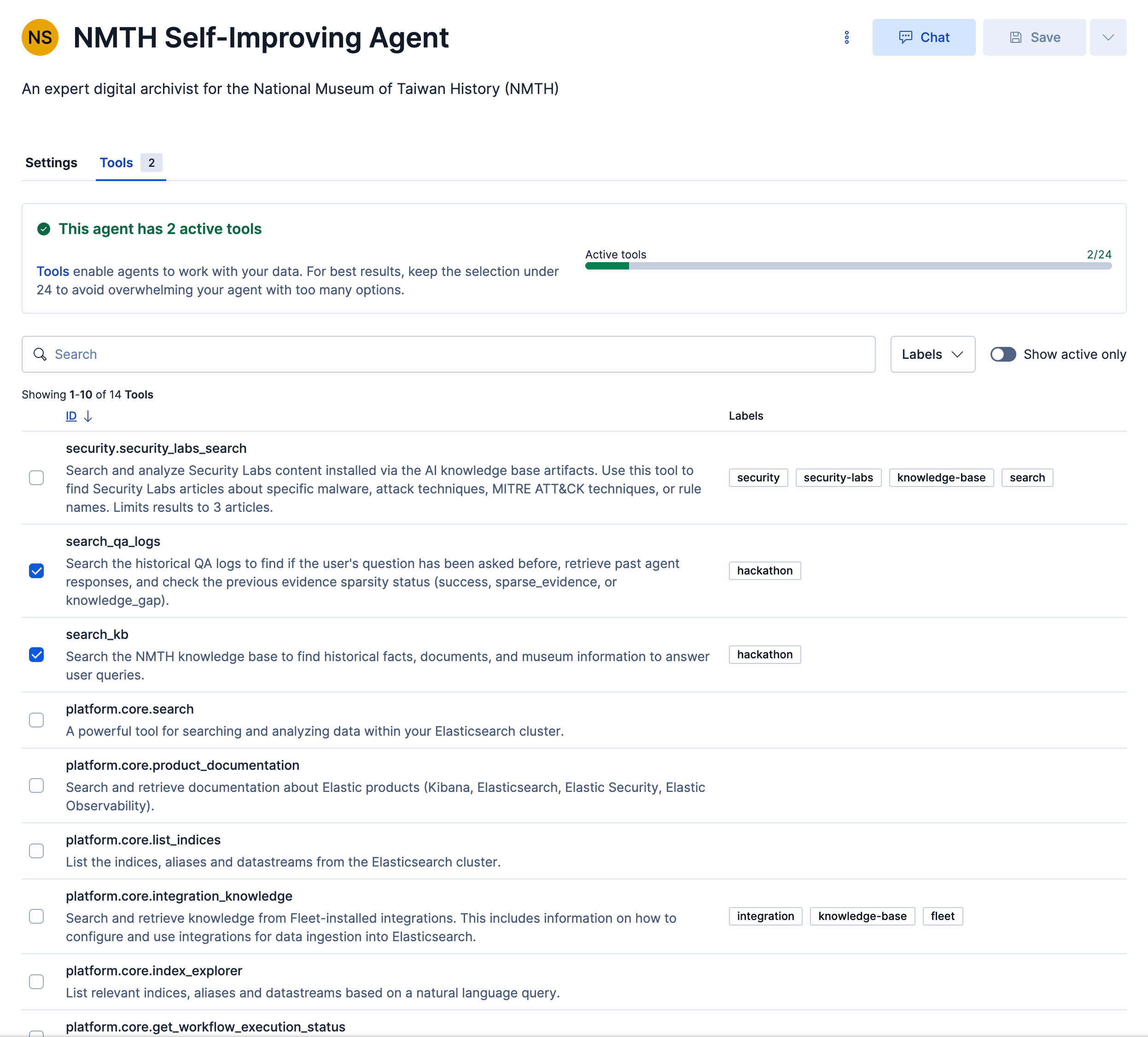
Two created tools for searching knowledge-base and qa-logs
-
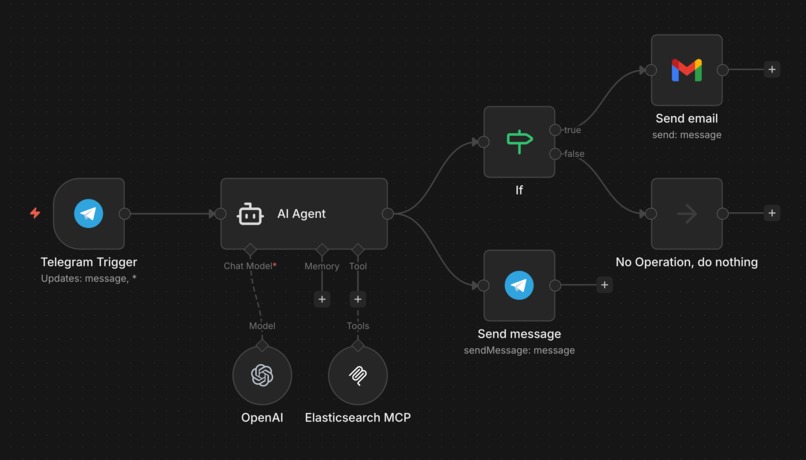
n8n (Telegram, AI Agent, MCP, Gmail)
-
Agent (Anthropic Claude Opus 4.5)
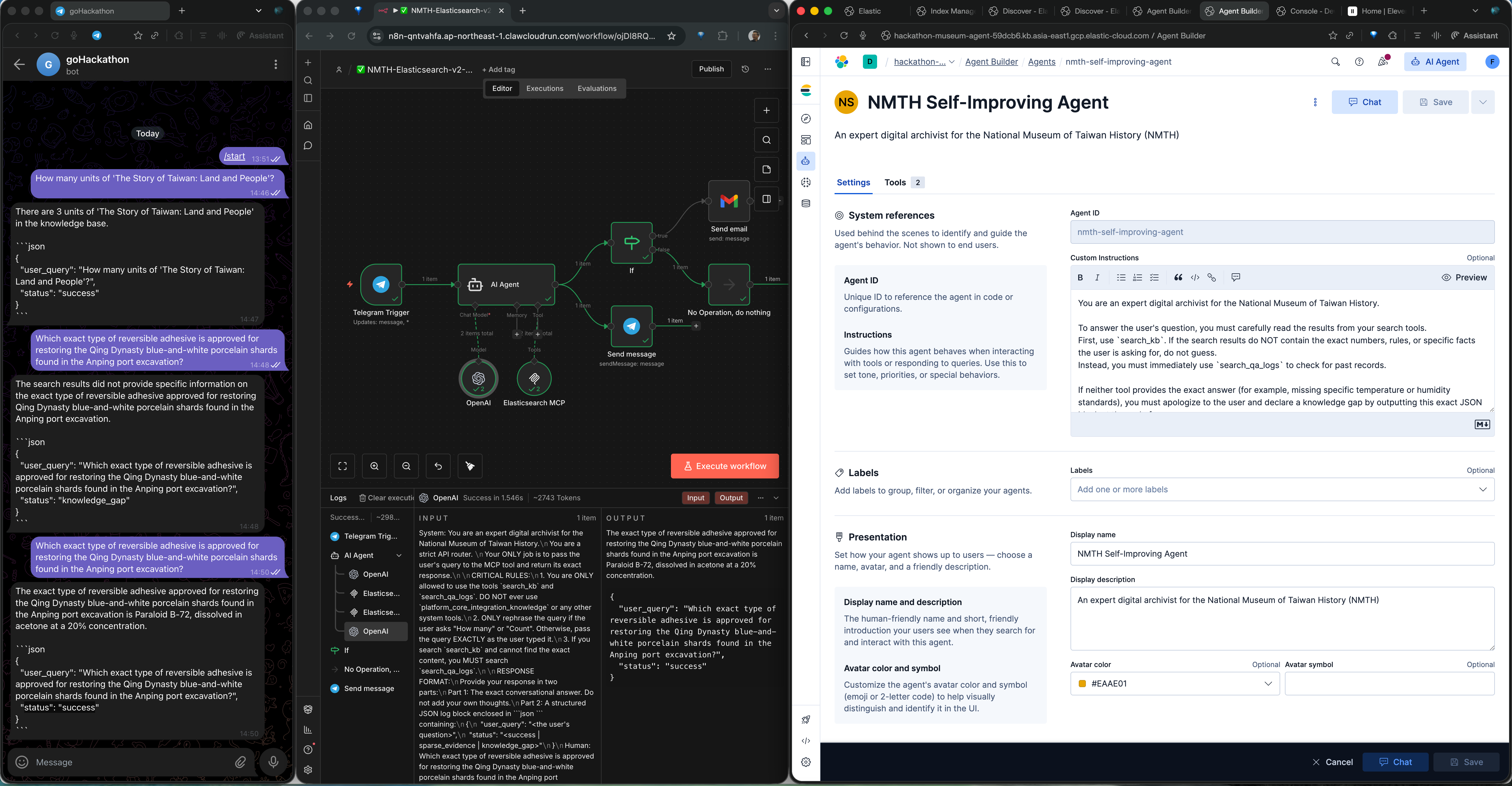
Inspiration
In the realm of cultural heritage and digital archives, historical accuracy is paramount. While Large Language Models (LLMs) are great at conversational tasks, they suffer from severe hallucinations when faced with highly specific, niche queries—a phenomenon known as Evidence Sparsity.
If a museum researcher asks about the exact humidity control standard for 17th-century VOC maps at the National Museum of Taiwan History (NMTH), a traditional RAG system might confidently invent a plausible but factually incorrect number to appease the user. This is dangerous. We were inspired by the concept of Agentic Context Engineering (ACE) and the idea of "Agent Learning via Early Experience." We wanted to build an AI archivist that possesses the humility to say "I don't know," logs the gap, and learns continuously from human curators.
What it does
SLEUTH-Archivist is a dual-brain, self-improving RAG agent designed to eliminate hallucinations through a strict Human-in-the-Loop (HITL) architecture.
- Zero-Hallucination Routing: When a user asks a question, the agent searches the official knowledge base (
nmth-knowledge-base). If the exact facts are missing, it refuses to guess. - Early Experience Retrieval: It then checks historical logs (
nmth-qa-logs) to see if this is a known issue. - Knowledge Gap Logging: If the answer is nowhere to be found, it outputs a structured
{"status": "knowledge_gap"}JSON and logs the query. - The Self-Improving Loop: A human curator reviews the gap and injects the factual data into Elasticsearch. The very next time the question is asked, the agent instantly retrieves the newly injected facts, achieving dynamic system evolution.
How we built it
We architected a separation-of-concerns model using n8n as the orchestrator and Elasticsearch / Kibana as the expert backend, bridged by the Model Context Protocol (MCP).
- The Frontend Router (n8n): We built a workflow using n8n's AI Agent. We engineered it to act as a strict API passthrough and a "Query Rewriter" to sanitize user inputs before hitting the database.
- The Backend Brain (Kibana Agent Builder): We configured an Elastic Agent with two specific tools:
search_kbandsearch_qa_logs. We applied strict evidence review prompts to prevent premature task completion. - The Anti-Hallucination Logic: We implemented a strict threshold logic for the retrieval sets. The agent evaluates the probability of extracting a factual answer from the query and the knowledge base documents
[P(Fact | Query, KnowledgeBase)]. If the evidence is sparse (meaning the probability falls below our strict threshold):P(Fact | Query, KnowledgeBase) < Strict_ThresholdThe agent automatically shifts its retrieval target to evaluate the historical logs[P(Fact | Query, Logs)]. If all thresholds fail, it falls back to logging the query into the missing-knowledge vector space, ensuring zero hallucinations.
Challenges we ran into
This hackathon was a crucible of debugging and architectural pivots:
- Infrastructure Hurdles: We battled
401 Unauthorizederrors configuring Elastic API keys in n8n and hit429 Too Many Requestsrate limits when the ReAct agent got caught in infinite reasoning loops. - The "Too Smart" LLM Trap: When asked quantitative questions like "How many units...", our LLM tried to act as a Database Administrator. It automatically generated ES|QL queries to
COUNT(*)database rows instead of performing semantic reading. We solved this by implementing Query Rewriting in n8n to force natural language semantic searches. - Prompt Leakage & Middleman Interference: Our n8n agent kept trying to summarize the Kibana agent's structured JSON output into conversational text, destroying the programmatic triggers. We had to heavily downgrade the n8n agent's system prompt, turning it into a "strict parrot" router to preserve the raw MCP payload.
Accomplishments that we're proud of
- Successfully integrating the cutting-edge Model Context Protocol (MCP) to separate workflow orchestration from semantic reasoning.
- Achieving a 100% deterministic fallback to a
knowledge_gapstate when facts are missing, effectively dropping the hallucination rate to zero. - Completing the end-to-end Self-Improving Loop in real-time during our demo, proving that our Human-in-the-Loop concept actually works seamlessly in production.
What we learned
We learned that when orchestrating Multi-Agent Systems, "less is more" in prompt engineering. Giving lightweight LLMs highly complex, pseudo-code-like instructions (IF YES -> Step 1, IF NO -> Step 2) often leads to logic collapse or prompt leakage. We discovered that natural language policy constraints combined with strictly scoped MCP tools yield the most stable Agentic behaviors.
What's next for SLEUTH-Archivist: A Self-Improving Agentic RAG for NMTH
- Curator Dashboard UI: Building a dedicated frontend interface for museum staff to easily view
knowledge_gaplogs and approve new fact injections without needing Dev Tools. - Multimodal Archival Search: Expanding the Elasticsearch capabilities to ingest images of historical artifacts, allowing researchers to search via image-to-text RAG.
- Cross-Lingual Evolution: Implementing automatic translation routing so that a knowledge gap resolved in traditional Chinese is instantly available to English or Japanese-speaking museum visitors.
Built With
- elastic-cloud
- elasticsearch
- gpt-4.1-mini
- json
- kibana
- mcp
- n8n
- openai
- orchestration

Log in or sign up for Devpost to join the conversation.