

Inspiration
Nowadays, an increasing number of people experience symptoms of insomnia, either mild or severe. The sales of melatonin have also remained consistently high. The average age of patients with sleep-related disorders is gradually decreasing. We are facing a significant challenge in the realm of sleep. If we can obtain more data related to sleep, perhaps we can better combat sleep-related disorders, allowing more people to experience complete and wonderful dreams. During the program, we initially used a relatively common CNN model for training. Meanwhile, we used methods like applying a learning rate scheduler, doing data augmentation and regularization to increase both the efficiency and accuracy. Realizing that time is a very important factor in our data, we also implemented a HMM model to further incorporate temporal dynamics.After conducting a more in-depth analysis of the data, we discovered that sleep stages might have a strong correlation with certain specific channels. Therefore, we also utilized RNN and a hybrid CNN and LSTM model for training. While comparing the results of RNN and CNN data, we considered whether using the random forest model could provide another perspective on the data and models. So, we embarked on the path of exploring the random forest model further.
What it does
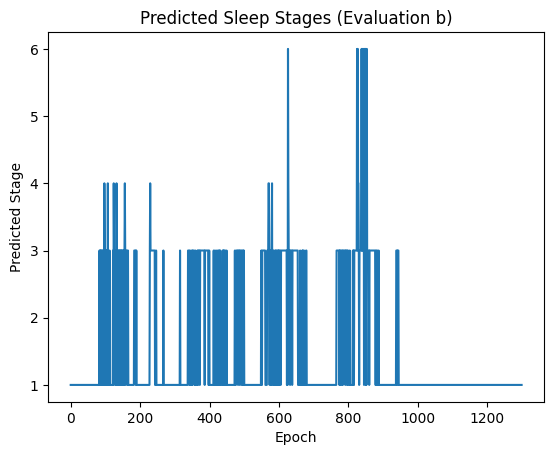
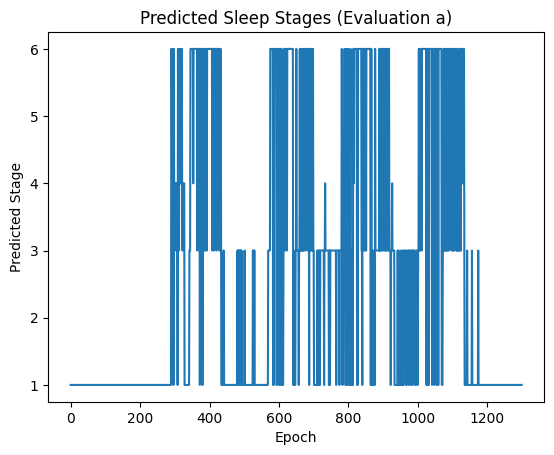
We initially used a relatively common CNN model for training. Meanwhile, we used methods like applying learning rate scheduler, doing data augmentation and regularization to increase both the efficiency and accuracy. Realizing that time is a very important factor in our data, we also implemented a HMM model to further incorporate temporal dynamics.After conducting a more in-depth analysis of the data, we discovered that sleep stages might have a strong correlation with certain specific channels. Therefore, we also utilized RNN and a hybrid CNN and LSTM model for training. While comparing the results of RNN and CNN data, we considered whether using the random forest model could provide another perspective on the data and models. So, we embarked on the path of exploring the random forest model further. Through sleep information from different channels, we can predict the sleep stage of an individual within a single epoch and generate corresponding sleep images for patients and doctors to use as medical and health references.
How we built it
One of our teammates modified the input data file. She strived to decompose the data into 2-dimensional versions and to shrink the size of X values. Each of the other three teammates chose one possible model and wrote the code to implement the model. All of them would take responsibility to calculate accuracy of outcomes and plot hypnograms for the evaluation data sets. Furthermore, they used the mean value of accuracy, which was obtained from the tests with all given training data, to determine the final candidate model.
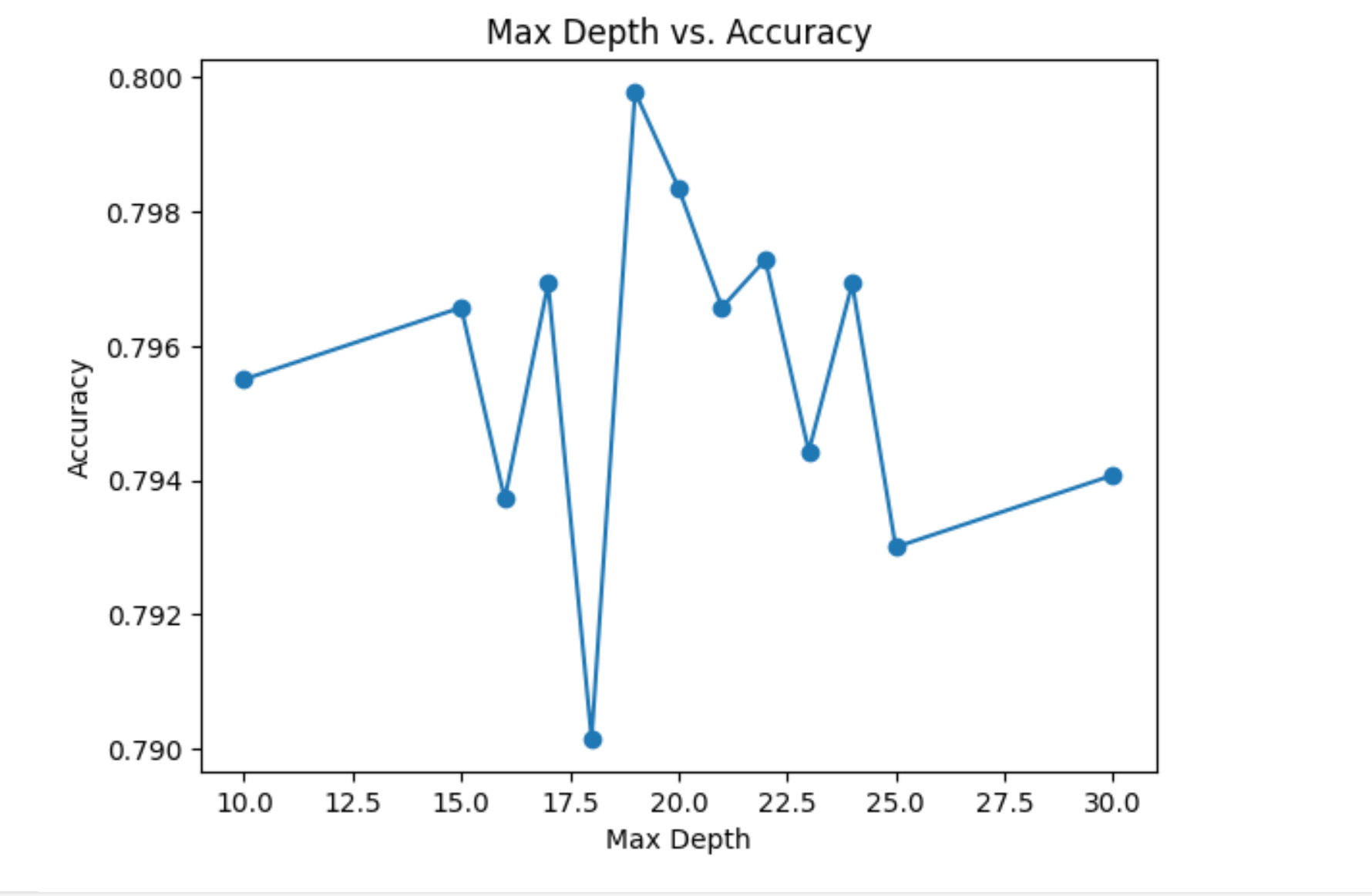
Random forest (Winner model) A smaller size will make the whole program run faster and cover more pairs of data In order to improve the accuracy of the output Get all accuracy results of all given training data and compute the mean value. We use this mean value to compare with other candidate models. (Of course, this is the best!)
Challenges we ran into
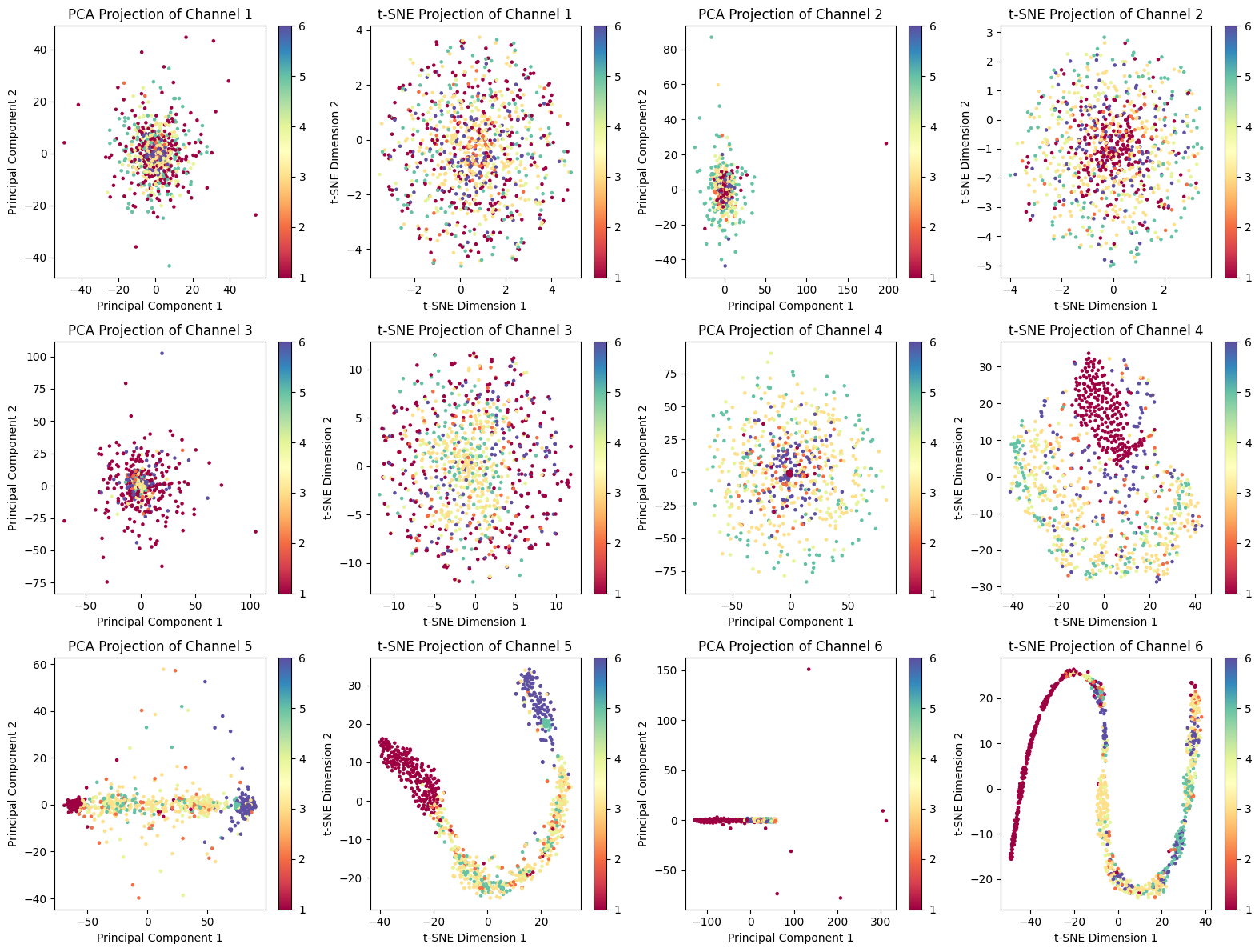
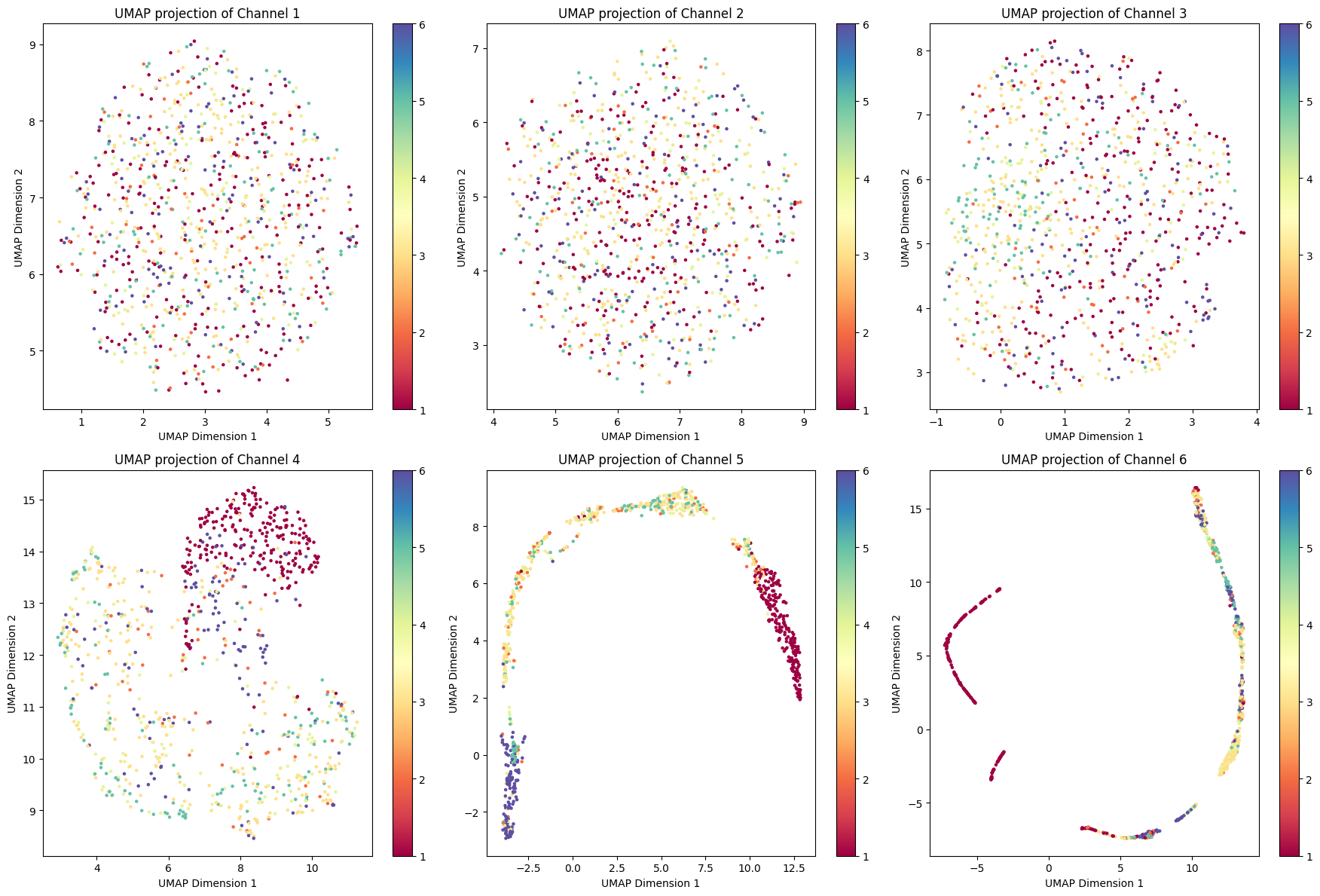
We try to utilize dimensional reduction to perform feature extraction so that we can break down the multidimensional values into 2-dimensional values. Due to the variance in sample size, it’s hard for us to tune the CNN and RNN model and hypnogram.
Accomplishments that we're proud of
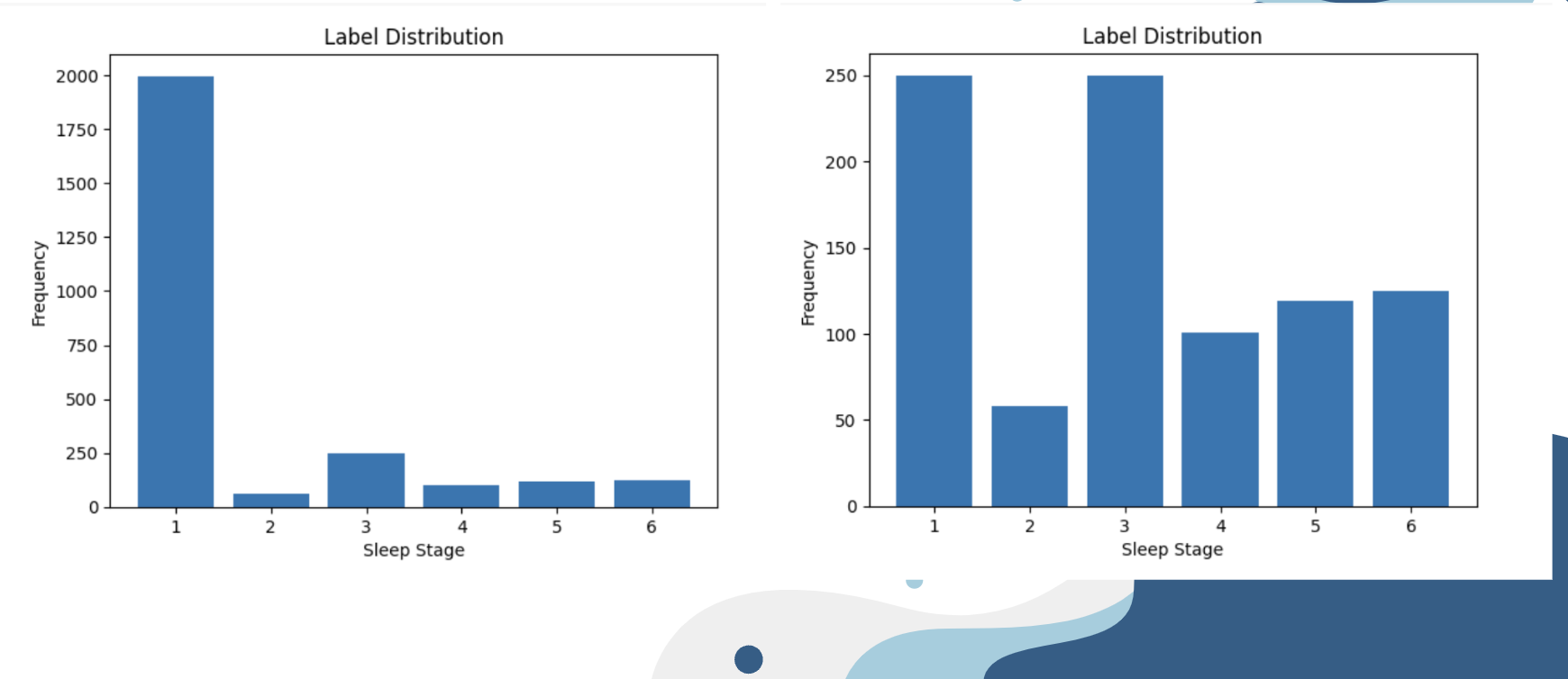
We did a very thorough and clear analysis of the dataset through data exploration and visualization. We explored a wide range of machine learning models to maximize the probability of finding the model that has good performance. Our random forest model had a relative high accuracy when we tested with all given training data. The highest accuracy is 0.98 and the lowest is 0.60.
What we learned
We have learned many different methods to try to improve the accuracy of model predictions. For example, reducing the dimensionality of the data to accommodate and train more data groups, modulating the layers and other parameters of the model settings, and conducting a more in-depth analysis of the data to determine which model may be more suitable. Sometimes we also need to make trade-offs with the model, and there are times when compromises can be made. All of these require continuous experimentation. These experiences are also our greatest wealth.
What's next for Sleepy Racoonzz
Moving forward, our team is set to delve deeper into the data, aiming to filter out less relevant information from individual patient profiles. This refined approach will streamline our model, enhancing its efficiency and allowing us to integrate more valuable data sets, thereby boosting the model's accuracy. Additionally, we plan to fine-tune various parameters within our models, optimizing their accuracy and overall performance for even more precise sleep stage predictions.
Built With
- cnn
- lstm
- python
- rf
- rnn




Log in or sign up for Devpost to join the conversation.