-
-
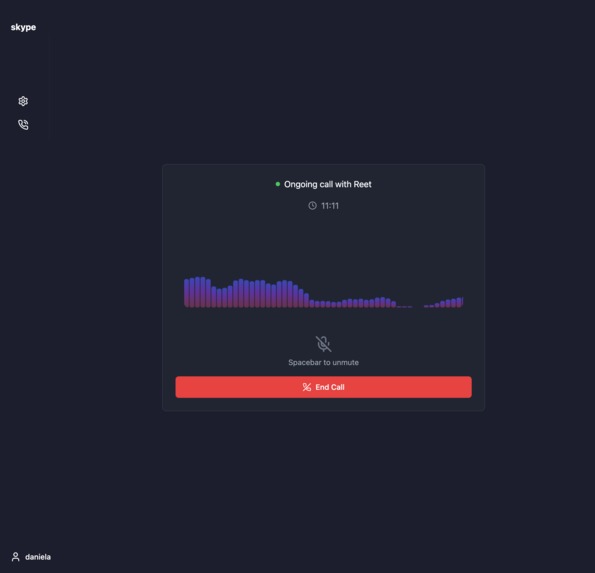
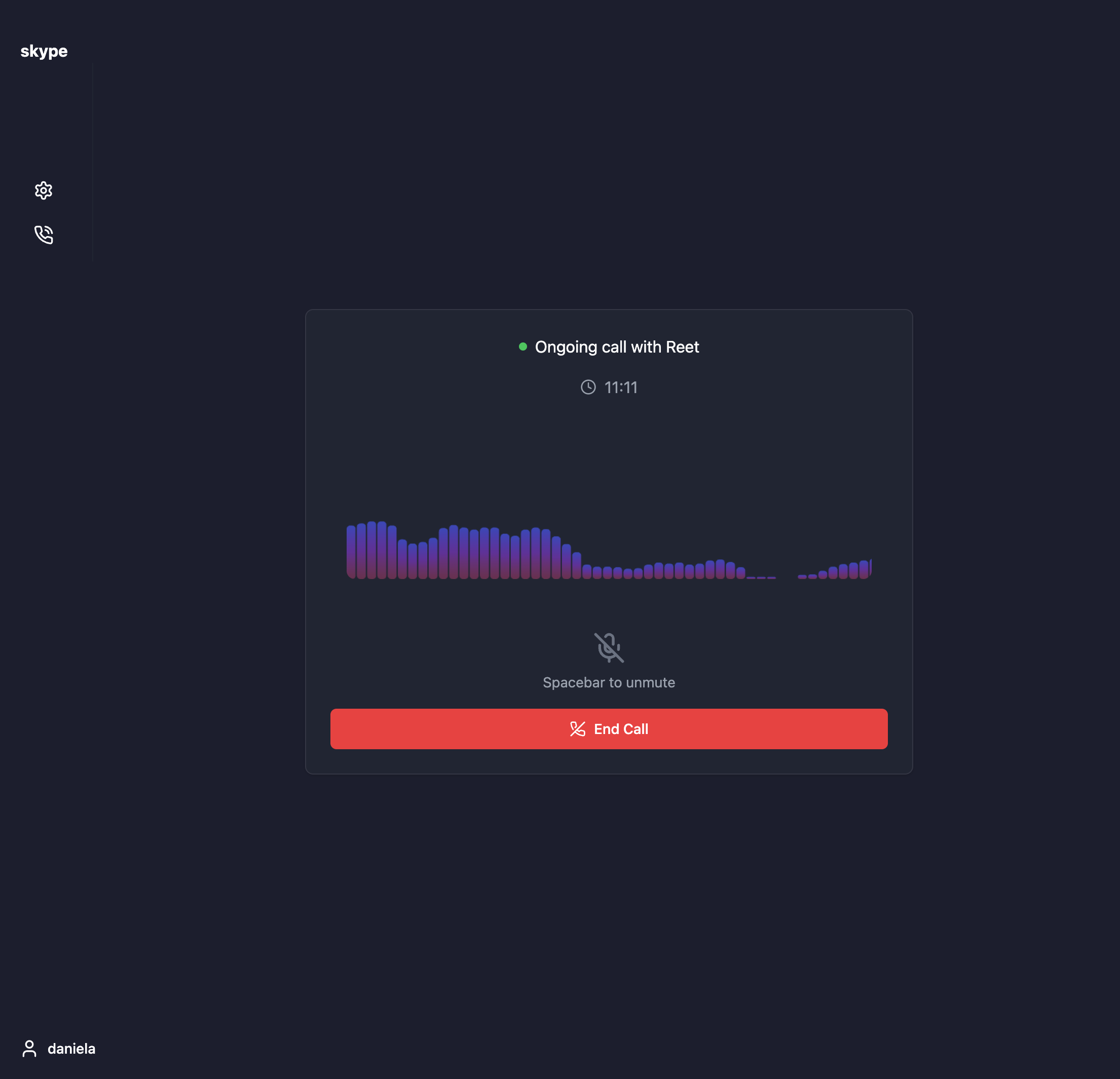
Real-time calling software
-
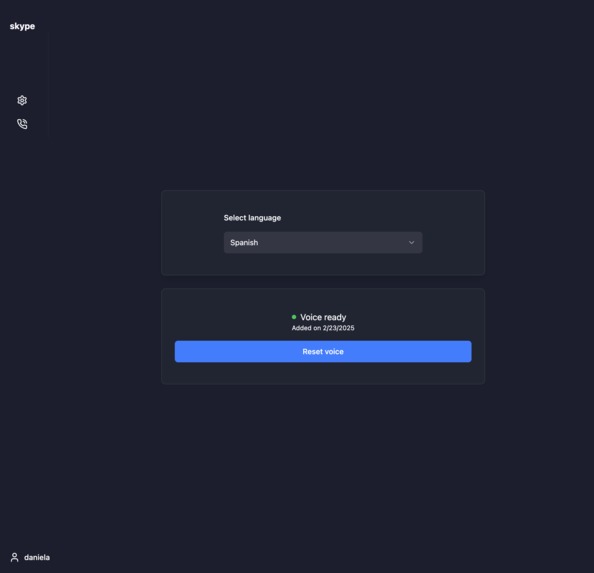
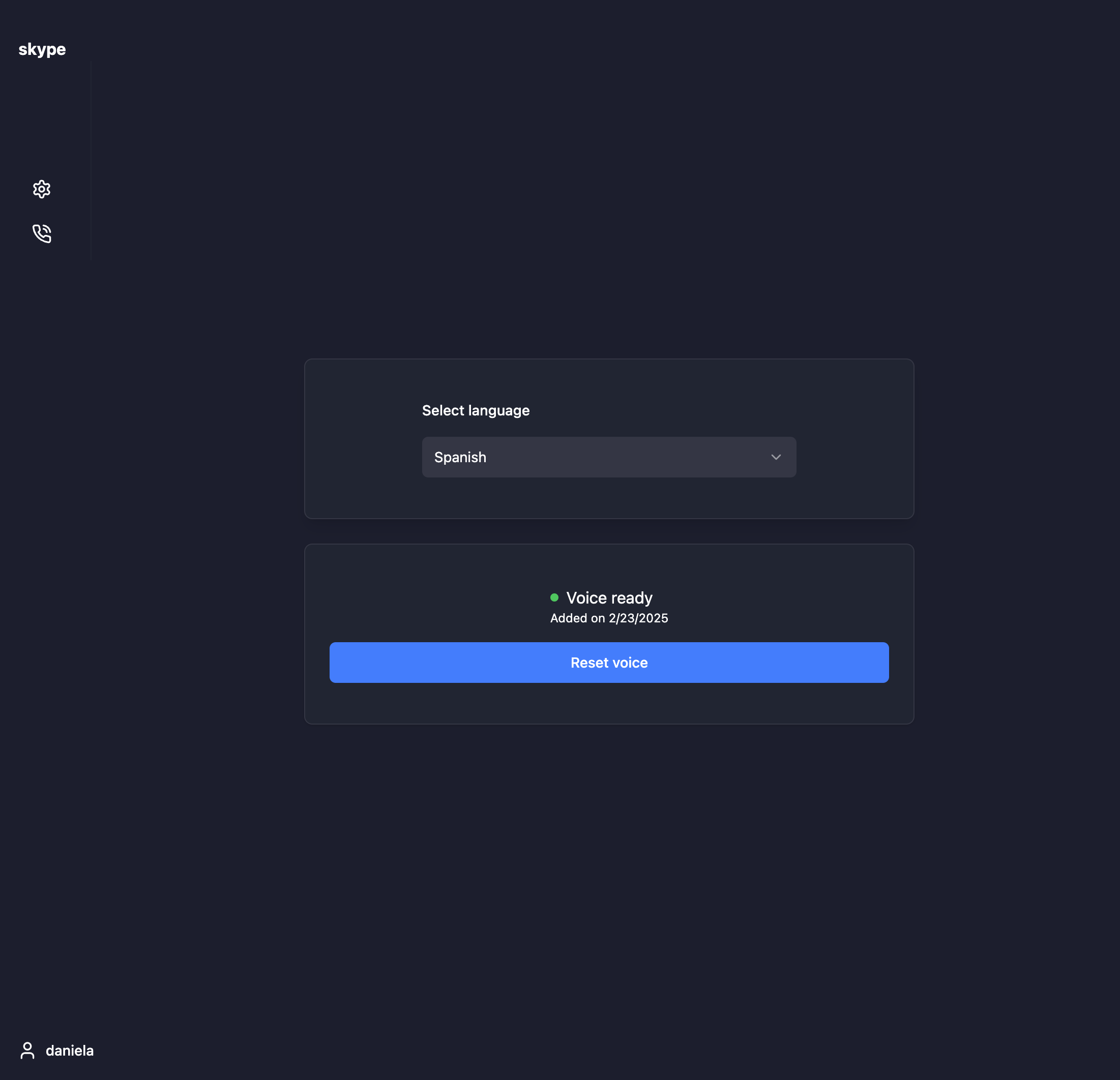
Voice clone setup
Inspiration
Our families live thousands of miles away, and we treasure our daily calls with them as precious moments of connection. For others, the distance is even larger due to language barriers. There's so much wisdom and love to be shared with family members who speak different languages, and we've built Skype (reimagined) to bridge these gaps.
What it does
- Creates a voice clone for each user, later used for translated call output
- Allows users to call each other and hear the call in their preferred language, real-time
How we built it
We used NeonDB, Vercel, and Render, and our stack is based in Python and React + Vite + TailwindCSS. Our system relies on device audio input / output and websocket infrastructure.
- Basic auth, components, calling state: React context
- Voice cloning: ElevenLabs voice cloning API
- Call creation / pickup: Custom JS / Python websocketing
- Call transcription: Speechmatics Websocket API
- Transcription translation: OpenAI GPT-3.5 API (streamed outputs)
- Text-to-speech: ElevenLabs text-to-speech (streamed inputs / outputs) with voice clone
Challenges we ran into
The websocket infrastructure was complex to build from the ground up, and we learned how to build custom websocket clients and robust client / server real-time interactions. We also had to figure out how to chunk audio input to reduce lag yet still receive quality translations. In the end, we ran into some limitations - we would've built the whole system as a continuous stream, but OpenAI's APIs don't support streamed inputs yet.
Accomplishments that we're proud of
We chained a lot of complex components together in a short amount of time, including three different vendors (Speechmatics, OpenAI, ElevenAI) with websocket / streaming based APIs. We were able to successfully pipe a stream of audio bytes through our whole system, ensuring that the global multiplayer state is accurate, and deployed it live as well.
What we learned
We learned that it's important to de-risk certain technical components beforehand and check for limitations at the start. Had we known about OpenAI's streaming limitations, we might've considered a simpler approach (e.g. chunking audio bytes ourselves).
What's next for skype (reimagined)
We want to make this system smarter and even more agentic. The system can decide how / when to chunk input audio bytes and send them over, passing any useful conversation context into the translation model. We want to build the best, most reliable calling system for people to call home more often.
Built With
- elevenlabs
- fastapi
- python
- react
- typescript
- vercel


Log in or sign up for Devpost to join the conversation.