-
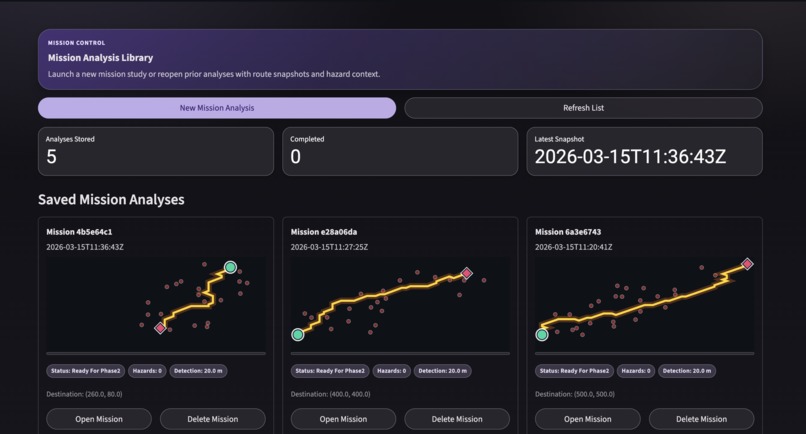
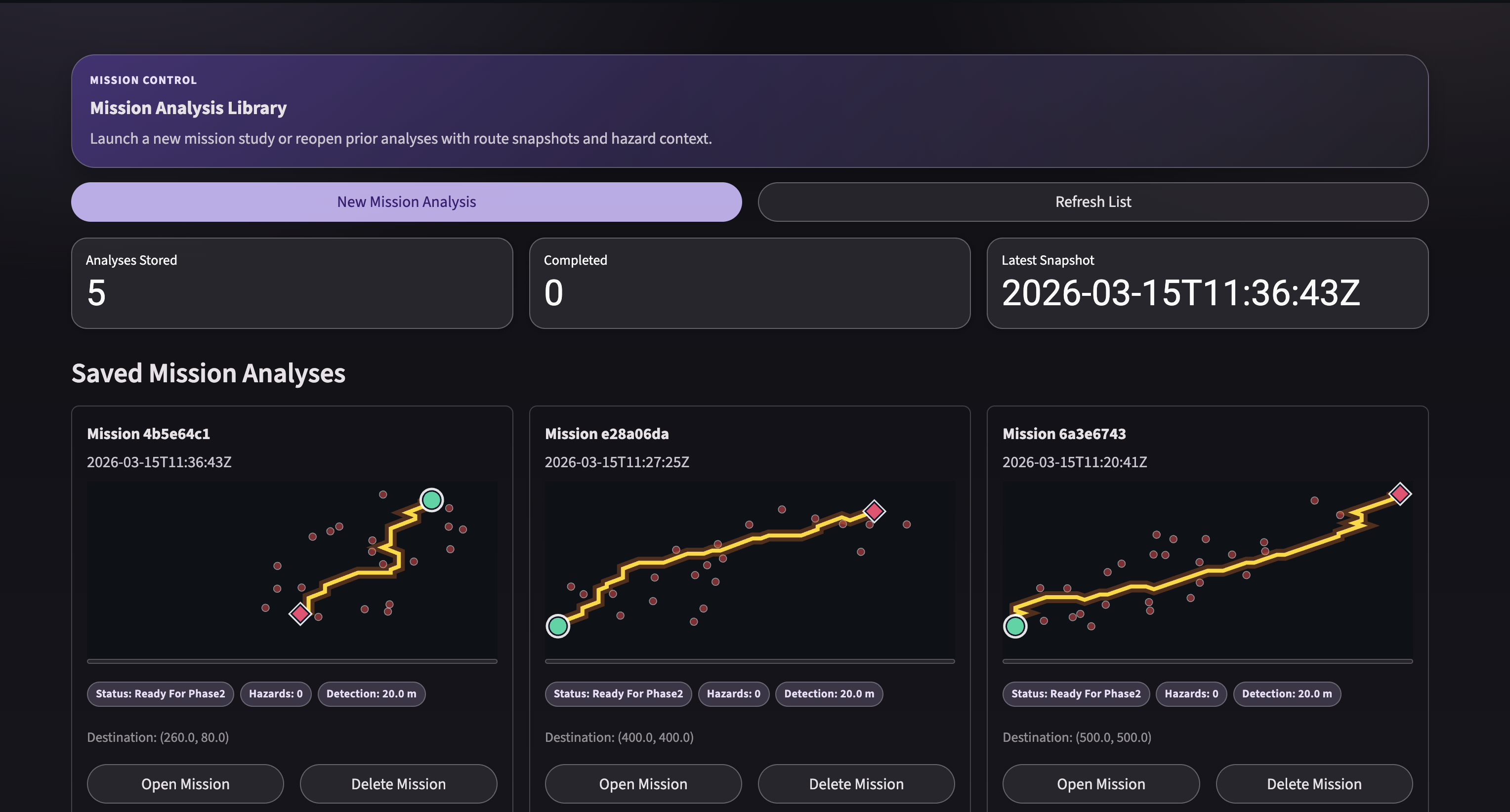
Main Dashboard
-

Drone path and terrain scan with custom algorithem
-
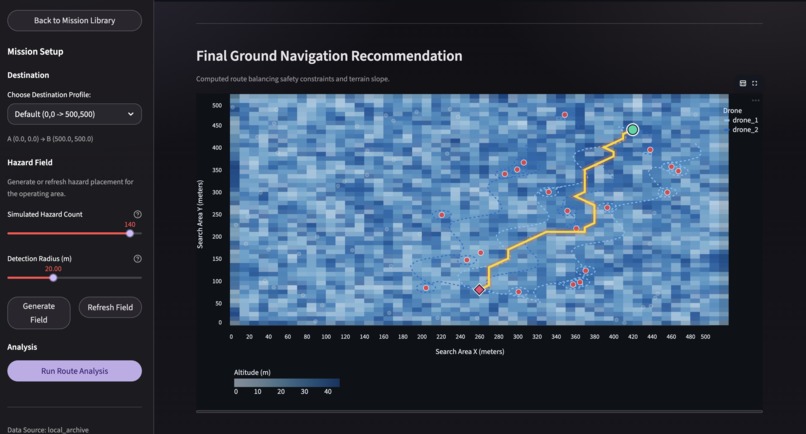
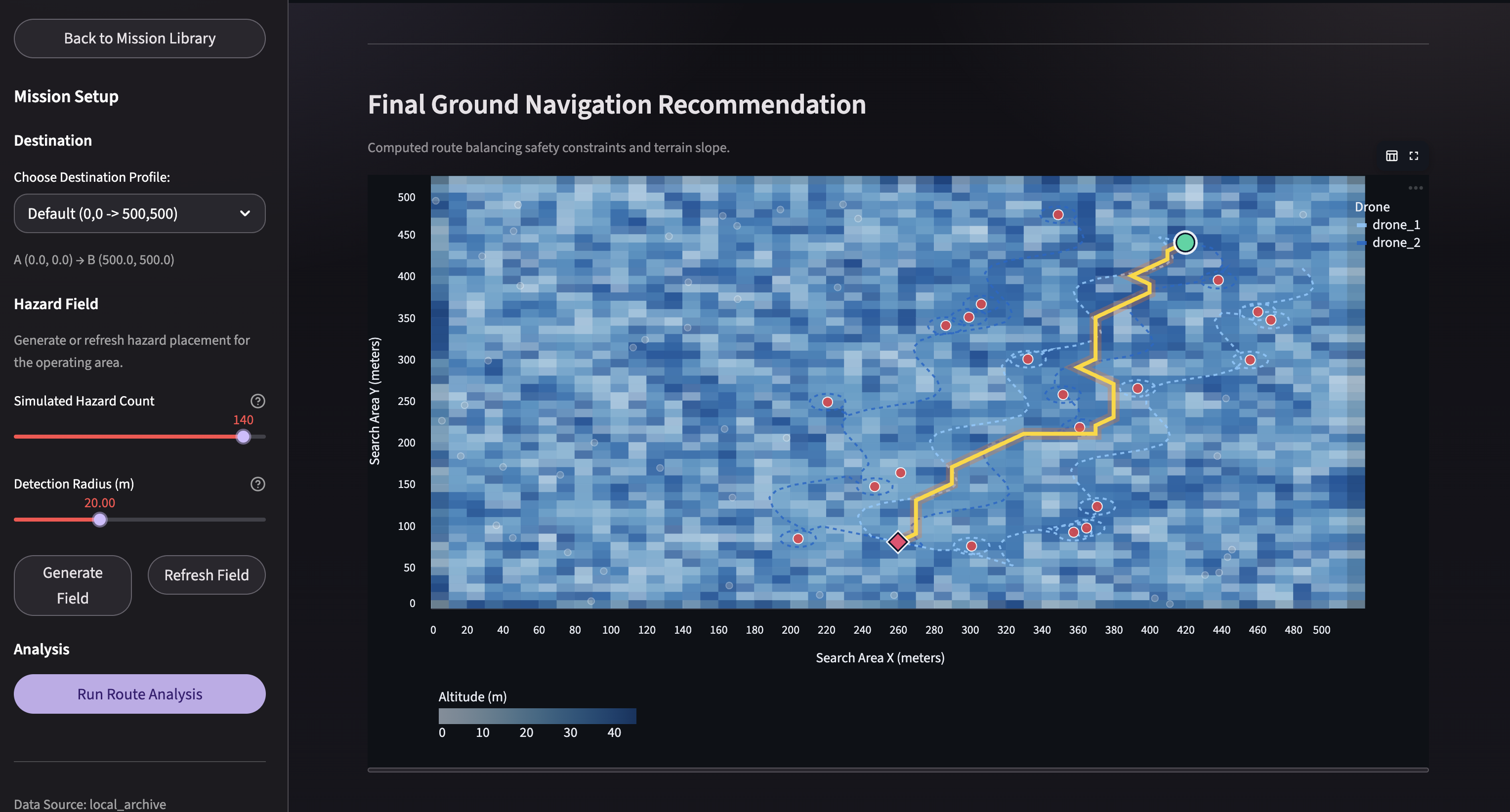
A* path generation for ground navigation routes

Inspiration
OOPS started from a simple problem we kept seeing in mission-style simulations: teams have plenty of data, but not enough clarity at decision time. Telemetry streams, map layers, and event logs all exist, yet they are usually spread across different tools and formats. That creates delay, uncertainty, and higher operational risk.
We were especially inspired by how quickly conditions can change in the field. A route that looked safe minutes ago can become risky when new signals appear. We wanted to build something that helps operators move from “data overload” to “clear next action.” OOPS is our answer: a system that continuously interprets incoming telemetry against tactical context and highlights risk before it becomes failure.
What it does
OOPS is a tactical decision-support engine that combines flight telemetry with map intelligence to produce actionable risk insights. Instead of just visualizing raw coordinates or status updates, it identifies patterns that matter operationally: risky zones, route exposure, and potential conflict points.
At a high level, OOPS:
Ingests telemetry and mission-state data Merges that data with tactical map layers Detects hazard proximity (including mine-related risk regions) Scores route and zone risk in near real time Outputs structured artifacts (JSON/CSV/logs) for monitoring, analysis, and replay The end result is not just “where things are,” but “what is likely to go wrong and where to act first.”
How we built it
We built OOPS in a modular pipeline so each part could evolve independently while still working end-to-end under hackathon time pressure.
The architecture includes:
Simulation layer: Generates and replays mission telemetry scenarios so we can stress-test behavior under different conditions. Processing/engine layer: Fuses telemetry with tactical map data and normalizes events into consistent internal structures. Risk evaluation layer: Applies scoring logic over routes, zones, and proximity signals to identify elevated risk regions. Validation loop: Repeated test runs to tune thresholds, compare outputs, and reduce noisy detections. Python was used for rapid iteration and data workflow control. We intentionally relied on transparent, inspectable outputs (CSV/JSON/log traces) so we could debug quickly and explain why OOPS produced a specific risk call.
Challenges we ran into
One of the hardest issues was data alignment. Even in a controlled simulation environment, telemetry timing, map geometry, and event semantics can drift out of sync. A small mismatch in coordinate handling or timestamp interpretation can produce misleading risk results.
Another challenge was balancing sensitivity and reliability. If the system is too sensitive, operators get alert fatigue from false positives. If it is too conservative, it misses meaningful hazards. We spent significant effort tuning for “useful signal,” not just maximum detection count.
Performance was also a concern. Tactical insights are only valuable if they arrive quickly enough to influence decisions. We had to optimize the pipeline to keep iterative runs fast and outputs stable while still preserving enough detail for debugging and review.
Accomplishments that we're proud of
We are proud that OOPS is a true end-to-end prototype, not an isolated algorithm demo. It accepts mission-like inputs, processes them through a tactical engine, and produces interpretable outputs teams can act on.
We’re also proud of the iteration workflow we established. By combining simulation, engine processing, and repeatable test loops, we created a development cycle that let us improve rapidly and verify changes with evidence instead of guesswork.
Most importantly, OOPS demonstrates practical value: it turns raw telemetry into risk-aware guidance. That shift—from passive data display to decision support—is the core accomplishment we aimed for.
What we learned
We learned that data contracts are foundational. Before model sophistication, you need consistent schemas, stable semantics, and reliable transformation steps. Clean interfaces between simulation, engine, and output layers saved us from compounding errors.
We also learned that explainability is a feature, not a bonus. In operational contexts, users need to trust why a location or path is flagged as risky. Transparent scoring and structured outputs made OOPS easier to validate and easier to trust.
Finally, we learned that fast feedback loops win in hackathon environments. The ability to run, inspect, tune, and rerun quickly was more valuable than pursuing overly complex logic too early.
What's next for OOPS (Overhead Obstacle Penetration System)
Next, we want to move OOPS from offline and replay-centric workflows to live streaming telemetry ingestion. That would make it useful in continuously evolving operational settings rather than only post-run analysis.
We also plan to improve the risk model with probabilistic forecasting and uncertainty estimates, so users can distinguish high-confidence warnings from ambiguous edge cases. That will make prioritization and escalation more intelligent.
On the product side, we want a polished operator-facing interface with:
Real-time risk overlays Route comparison and what-if scenario planning Alert management and mission replay After-action analytics for continuous improvement Longer-term, the goal is pilot deployment with real stakeholders to validate OOPS under realistic operational constraints and refine it into a production-grade decision-support platform.

Log in or sign up for Devpost to join the conversation.