-
-
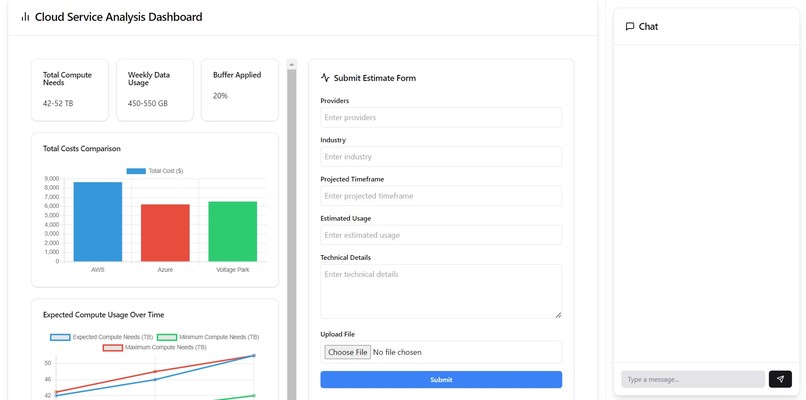
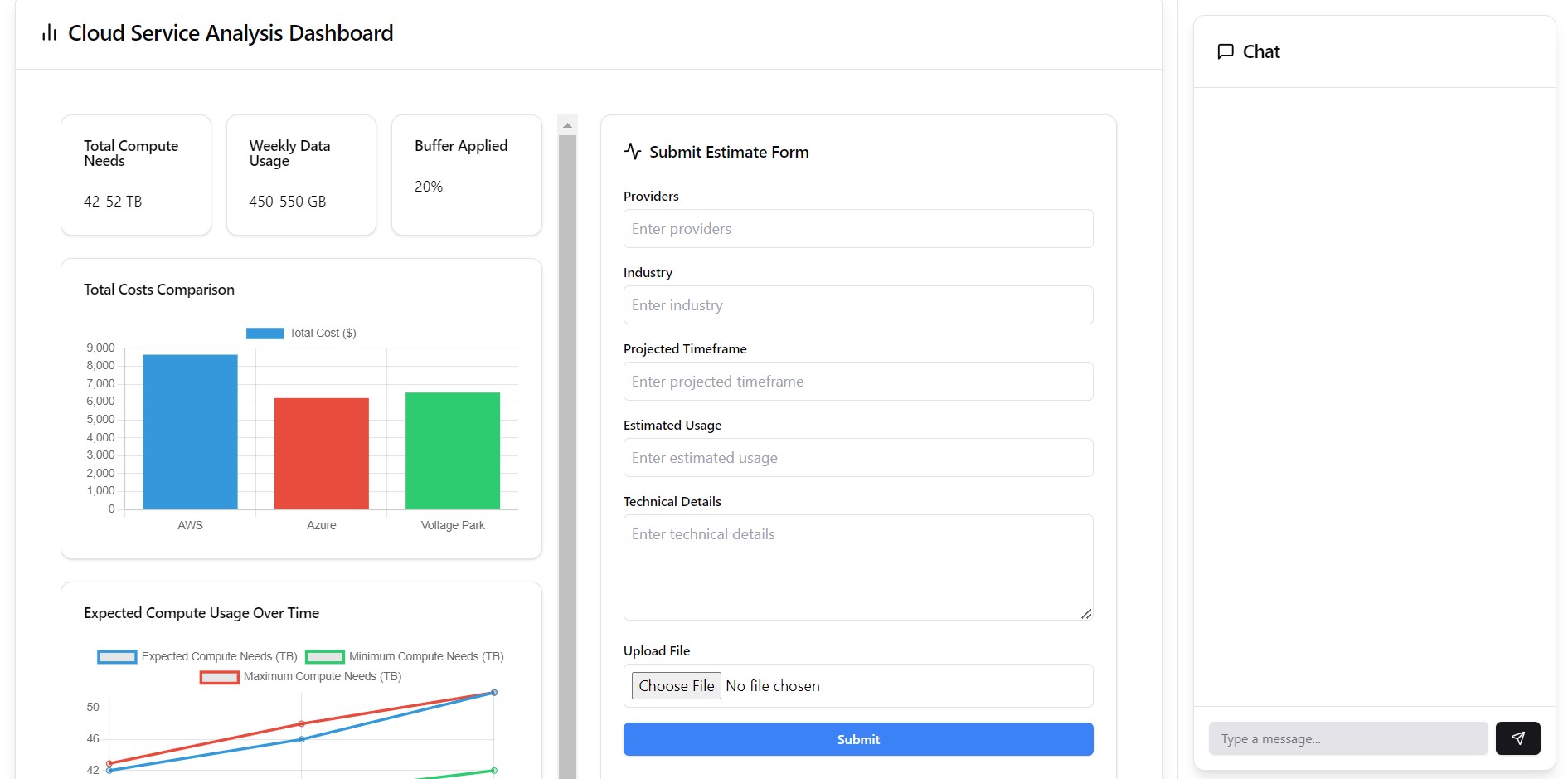
Cloud optimization dashboard we built this weekend
Inspiration
While working on my own AI research, I routinely relied on cloud computing. Last summer, I encountered a major setback: after three weeks of work, I had under-allocated compute resources for my experiment - all my progress was lost. Frustrated, I turned to my mentors for advice, only to discover that this issue—either over-provisioning or under-utilizing cloud resources—was a common problem they had faced as well. I realized this same issue had to apply to the wide variety of cloud computing customers.
What it does
SkyScale helps organizations optimize their cloud computing usage by providing tailored recommendations. A user would first fill out data about their organization as a whole and upload documentation (think business plans, slide decks, proposals, papers, etc.) SkyScale analyzes this data, extracts pertinent information, determines the necessary compute units needed, and determines the best cloud computing services for the use case. Unlike all other existing cloud optimization softwares, SkyScale looks at your use case as a whole and determines the best allocation of services for your specific application. After a user is up and running, SkyScale connects with cloud computing services to continuously real-time monitor your usage to forecast future needs. This allows organizations to dynamically scale and adjust allocations to pay for only what they are using.
How we built it:
Before we began building, we spent the first ten hours of the hackathon ideating and researching cloud computing. We spoke to two cloud computing customers and a FinOps specialist at a big company to understand what causes so much cloud computing over expenditure. We learned that the majority of over expenditure occurs during the transition from in house servers to cloud computing as most companies have no understanding of the field and opt for the default setup, which is also most inefficient (almost by design … ).
We then began building. We split SkyScale into three stages: input, processing, and output. We used Next.js to create a web page to retrieve input in a user-friendly manner. User input consisted of several different info sources that could help us determine their cloud computing requirements. Then, we integrated the front-end with our backend LLM. We used a fine-tuned GPT, prompted specifically for cloud compute solutions and real-time querying. Taking all of the prompt layers below the surface, the user inputs are parsed and analyzed for specific keywords and phrases, then used to create suggestion predictions for compute plans. Finally, we output the results in a structured JSON file, which are displayed on an analytics dashboard for the user designed in JS. Again, we highlight the importance of making the process simple and user friendly.
Challenges we ran into
We ran into numerous challenges over the past 36 hours - too many to record. One of the biggest challenges we ran into was understanding what the real problem was with cloud computing over-expenditure. There are many existing cloud optimization softwares on the market, yet the problem continues to exist. Our understanding was the diverse range of cloud computing customers caused for these softwares to be overly general. We opted for a personalized approach. We also struggled to figure out a way to make it simple for users to input their data. Most of our users do not have significant cloud computing experience or know specifics about what services they desire. We decided the best approach is to extract data ourselves from their business model and documentation using LLMs. Additionally, we ran into a lot of hurdles with fine tuning our model. Based on our product requirements, we needed to utilize LLMs that have online search capabilities that can also be adjusted and fine-tuned. Due to the need to query real-time data about cloud compute providers, GPT-4o was our top option for data integration. In fine tuning, we scraped information from online sources about cloud compute prices, FinOps, and best practices per industry. These were used to adjust the model through API fine-tuning and system call requirements. A great deal of our fine-tuning also came through prompt engineering. Using tailored prompts behind the scenes, we adjusted model settings to account for user input nuance and real-time queried data.
Accomplishments that we're proud of
Of course, we are most proud of what we built. We spent a lot of time ideating to truly find a unique unmet need and think we built a tool that actually addresses it. As researchers, we would genuinely use our tool. We are also proud of how much we learned this weekend. We came into the project with not a ton of experience working with Next.Js or building projects, but came out of it feeling a lot more confident with developer tools.
What we learned
Again, there is too much that we learned than we can list here. To list a few: Cloud computing workflows Relational Databases Enterprise payment schemas Fine tuning models NextJs Building user friendly APIs Integration OAI keys Handling multimodal inputs Deploying systems on Replicate
What's next for Sky Scale
We built an MVP for SkyScale this weekend. Our next step is to test our prototype with users to receive feedback and better understand how we can best address this problem. By talking to users, we hope to gain a better grasp on cloud computing over expenditure (much better than we could in 36 hours) and build SkyScale into an end to end solution that can benefit organizations.
Built With
- cloudflare
- next.js
- openai
- replicate

Log in or sign up for Devpost to join the conversation.