⚡ Skorpio
An Agentic AI Operator Console for Grid Planning and Datacenter Siting
Live Demo · Sample Reports (Drive) · Demo Video (YouTube)
🌍 Inspiration
Ontario's grid is about to absorb three concurrent shocks: AI datacenters chasing cheap, clean power, mass electrification of heat and transport, and intensifying climate extremes. Each is normally analyzed in isolation by a different team, on a different timeline, using a different toolchain.
| Reality | Scale |
|---|---|
| US power capacity stuck in the interconnection queue | ~2,600 GW (LBNL Queued Up, 2024) |
| Typical project wait, request to commercial operation (2018-2023 cohort) | ~4 years (LBNL Queued Up, 2024) |
| Datacenter share of US electricity by 2028 | 6.7 to 12% (DOE / LBNL, 2024) |
| Ontario electricity demand growth by 2050 | ~65% (IESO Annual Planning Outlook, 2026) |
The problem is not a lack of data. The IESO publishes hourly demand and prices, ECCC publishes climate normals, OSM has every substation in the country, the OEB publishes utility-level financials, and StatsCan publishes provincial generation. The problem is that turning that data into a defensible plan still takes weeks of analyst work per question.
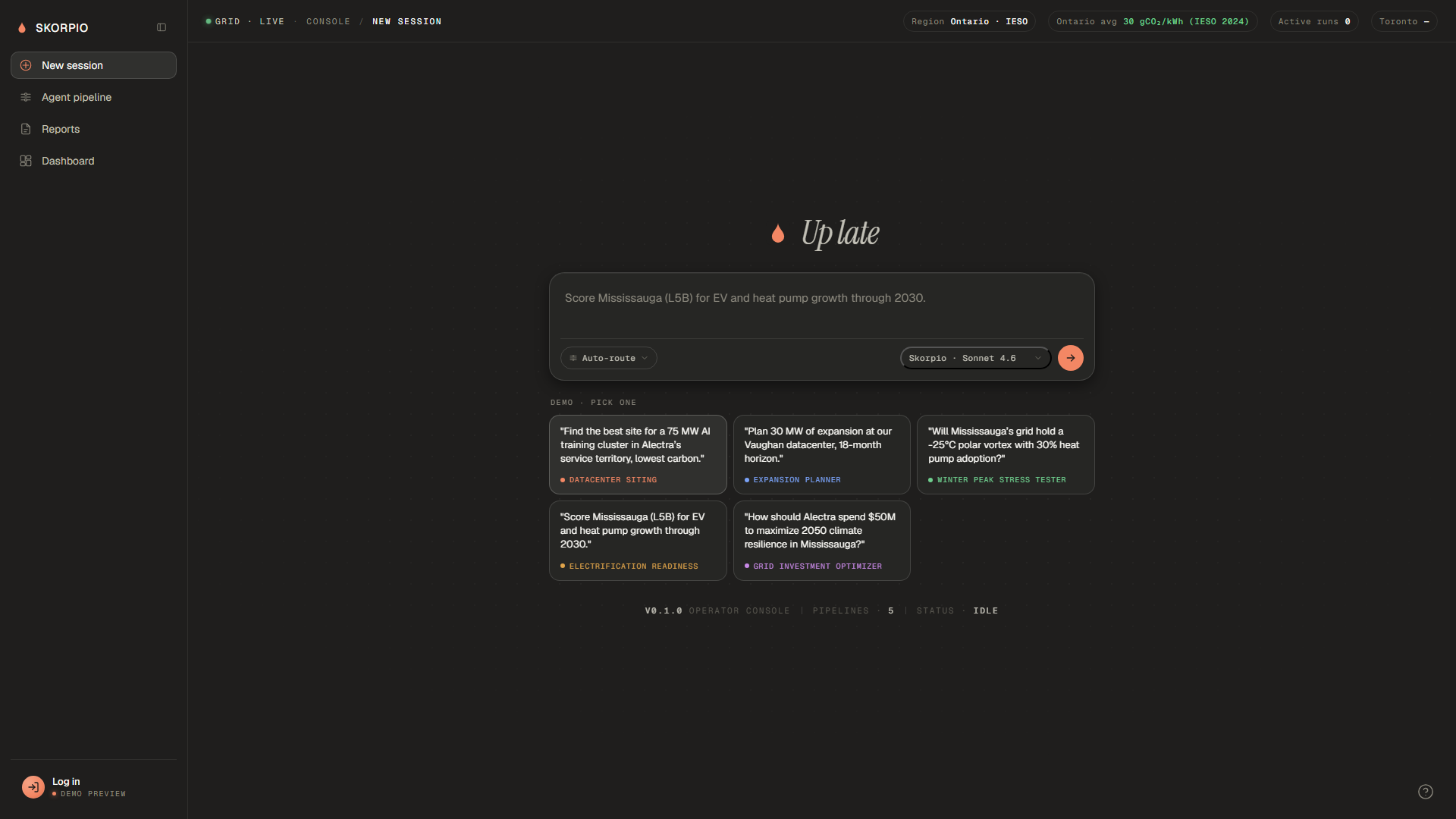
Our goal: Build an operator console where a planner asks a one-sentence question and watches an agent pipeline pull real grid data, run real simulations, and produce a ranked, sourced plan in minutes instead of weeks.
🚀 What It Does
Skorpio is a multi-pipeline agentic AI platform purpose-built for the Seneca Hackathon's Smart Grid Resilience and Preparing for Electrification track.
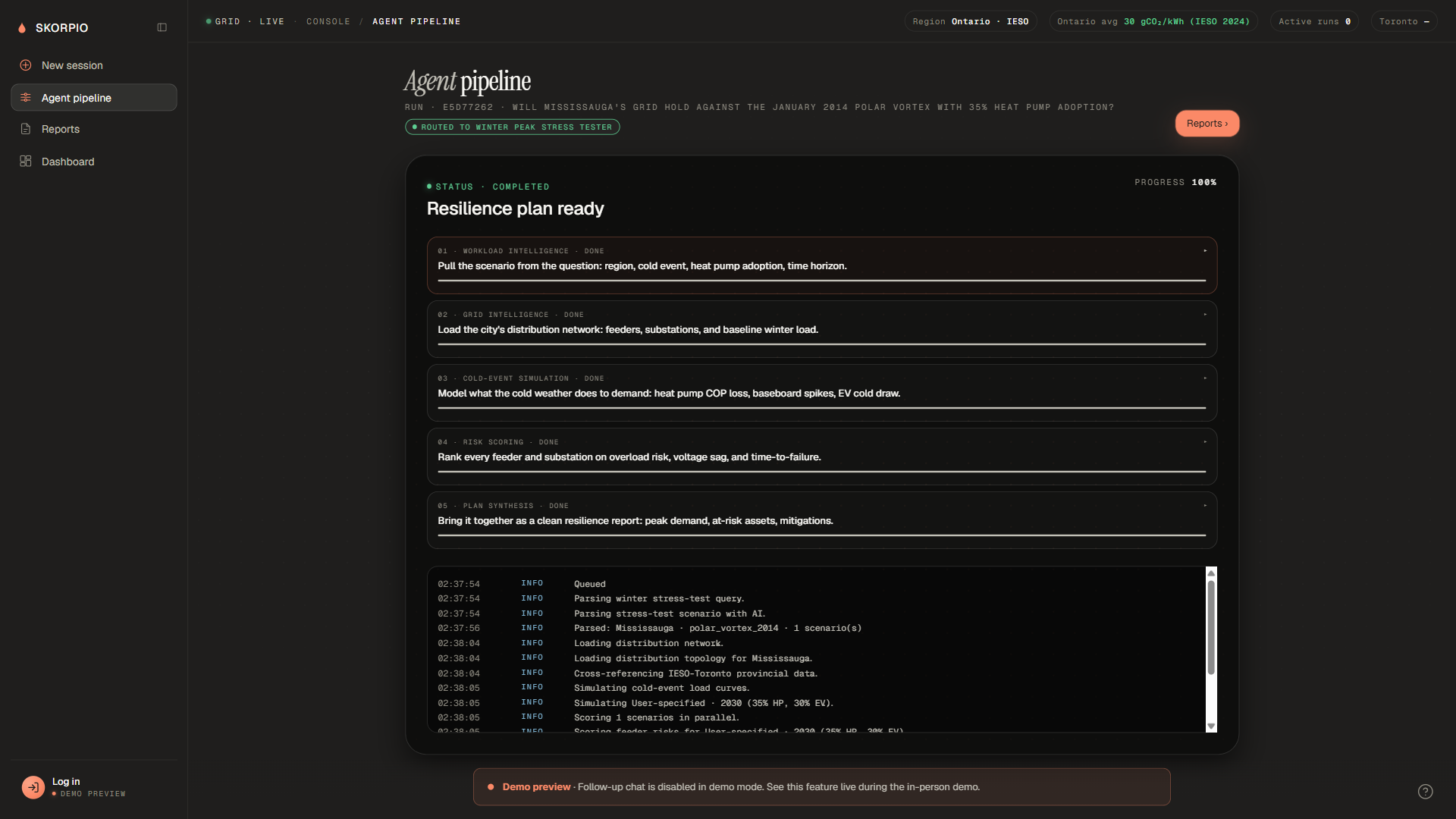
A planner types a single sentence ("Find the best site for a 75 MW AI training cluster in Alectra's territory, lowest carbon"). A router agent dispatches the prompt to one of five specialized pipelines. Each pipeline runs five sequential stages, each stage is its own agent with its own tool budget, and the operator watches the work happen live with per-stage progress, log lines, and intermediate visualizations.
The Five Pipelines
| Pipeline | Question it answers |
|---|---|
| Datacenter Siting | Where should a new datacenter go, given capacity, latency, and carbon constraints? |
| Datacenter Expansion | How should an existing operator grow capacity at a specific site over a horizon? |
| Winter Peak Stress | Can a city's grid hold a polar vortex with X% heat pump adoption? |
| Electrification Readiness | How ready is a neighborhood (FSA) for EV and heat pump growth through a target year? |
| Grid Investment Optimizer | How should a utility spend a fixed capex budget to maximize long-term resilience? |
Each pipeline ends with a structured report: an executive summary, a 3-card verdict grid, a Mapbox view of the relevant geography, ranked candidates or recommendations, and a follow-up chat where the operator can interrogate the result.
⚙️ How It Works
Every pipeline shares the same architectural pattern: a Python Orchestrator instance drives five StageAgent instances in sequence, each emitting structured progress events that stream to the browser over Server-Sent Events.
Stage Pattern
Workload Intelligence → Grid Intelligence → Simulation → Risk Scoring → Plan Synthesis
Each stage:
- Pulls live data from the relevant ingest tables (real grid data, never synthetic)
- Calls Anthropic Claude with a tight, structured prompt and pipeline-specific tools
- Validates the output against a Pydantic schema before persisting
- Emits a
stream_eventso the frontend can update the stage card in real time
Data Sources (All Real)
The §0 Data Provenance rule we hold ourselves to: no fabricated quantitative values, ever. Every number in every report traces back to one of these:
- PeeringDB: datacenter operator footprints and capacity
- ECCC
bulk_data: climate normals and historical cold events - IESO: Ontario hourly demand, HOEP prices, generator output
- AESO: Alberta pool price + Alberta Internal Load
- OSM Overpass: substations, transmission lines, voltage classes
- StatsCan Tables 25-10-0015, 25-10-0021, 23-10-0308: generation, heating mix, vehicle stock
- OEB Yearbook: Ontario utility customers, peak load, capex
- OEB territory polygons: distributor service boundaries (used as a geofence so we never assign load to the wrong utility)
When a fact cannot be sourced, the report says so explicitly rather than guessing.
🛠️ How We Built It
Backend
Python · FastAPI · SQLAlchemy 2.0 (async) · PostgreSQL · asyncio
Anthropic SDK · Pydantic · GeoPandas · Shapely · NumPy · Pandas
The orchestrator manages five pipelines, each with five stage agents. Pipelines run in isolated asyncio tasks so multiple planners can run in parallel without blocking each other. The async session pattern (AsyncSessionLocal) means a single uvicorn worker can comfortably hold ~20 concurrent pipeline runs.
Frontend
React 18 · TypeScript · Vite · React Router · Mapbox GL · Recharts
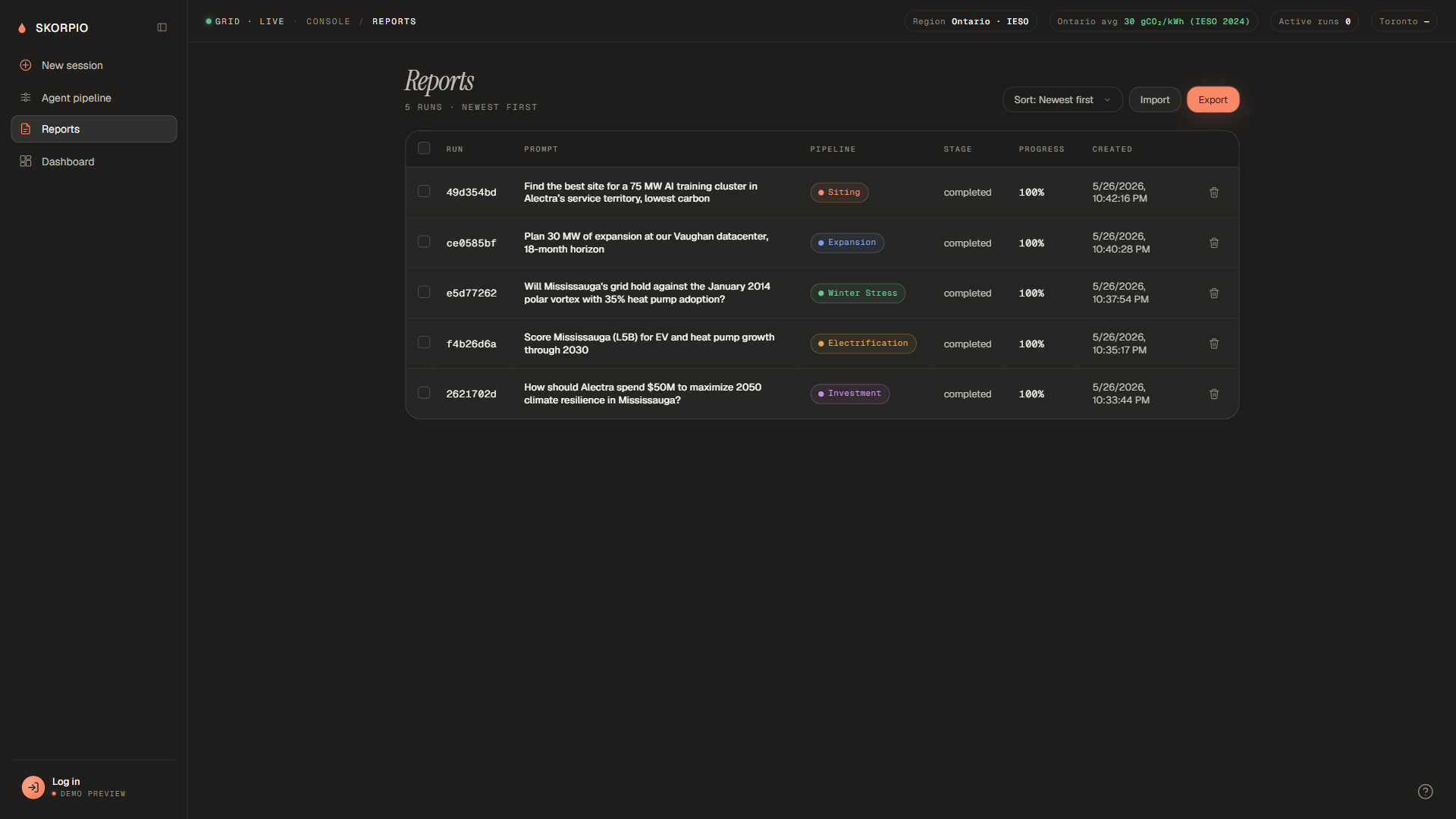
The console is split into four tabs: New Session (composer + suggestion cards), Agent Pipeline (live stage view), Reports (history table with re-run and re-tag), and Dashboard. Every report includes a Mapbox visualization, a 3-card verdict grid, and an embedded follow-up chat backed by the same Claude API.
Demo Mode
For the Vercel deploy where no backend is reachable, the app ships with five pre-recorded fixture JSONs (one per pipeline) exported from a local run. A small intercept layer in the API client serves these fixtures synchronously when the requested job_id matches a fixture UUID, so the demo experience is identical to the live one except for the actual agent invocation. A guided 10-step PowerPoint-style walkthrough auto-plays for first-time visitors.
🧩 Challenges We Ran Into
Data heterogeneity. IESO publishes in EST with daylight-saving quirks, AESO publishes in MST, ECCC bulk data is CSV-with-headers-on-row-25, OSM data is XML with implicit assumptions about voltage. The first month was almost entirely an ingest layer.
Sticking to §0. It is genuinely tempting to "fill in a reasonable estimate" when a data source has gaps. Holding the line that an empty cell stays empty (or the report flags a data gap) was harder than writing the pipelines.
Agent reliability vs latency. Claude Sonnet 4.6 is reliable but a full pipeline run is 20-40 seconds. We use Haiku 4.5 for the router (sub-second prompt classification) and Sonnet 4.6 for the actual stage work. Opus is exposed in the model picker for the rare deep-investigation case.
Pipeline cohesion. Five pipelines built by one person over a hackathon means style drift. We maintain a REPORTS_COHESION.md doc as the single source of truth for cross-report naming, structure, and vocabulary so each pipeline does not invent its own labels.
🏆 Accomplishments We're Proud Of
We shipped a system where you can type "Will Mississauga's grid hold a -25°C polar vortex with 30% heat pump adoption?", watch a 22-second agent pipeline ingest ECCC cold-event data, pull the city's transmission topology from OSM, simulate per-feeder load under the cold event, score every feeder for failure risk, and produce a ranked resilience report. Every number in that report traces back to a real, published source.
The platform compresses a question that would normally need a weeks-long analyst engagement into a couple of minutes, without sacrificing the auditability of the data trail.
📚 What We Learned
In grid planning, the value of an agent system is in the rigor of its data provenance, not the cleverness of its prompt.
The agent reasoning is, frankly, the easy part. The hard part is integrating heterogeneous public datasets into a coherent decision-making substrate, then keeping the agents disciplined enough to say "I do not have data for this" instead of confabulating.
We also learned how much UX care a multi-pipeline tool needs. Five pipelines that each produce a different report shape would be unusable without aggressive cross-report cohesion work on naming, layout, and verdict structure.
🔭 What's Next
The next priority is a real-time grid-state feed so the pipelines run against current data rather than the most recent batch. Practical next steps:
- Live IESO 5-minute demand stream as a websocket
- Per-substation operational status (currently we use the static OSM snapshot)
- Forecasted vs realized comparison so reports can flag when a simulated load actually showed up on the wire
Beyond that, we want to extend the pipeline set to cover transmission planning (line additions, reactive support) and to integrate with the IESO's market interface so a "what if" question can also surface market-clearing implications.
Skorpio. Real grid data. Real agents. Real plans.
Built With
- css
- dockerfile
- html
- javascript
- python
- typescript

Log in or sign up for Devpost to join the conversation.