


Inspiration
Many of our friends and acquaintances who have studied in the medical field have talked to us about the lack of images and databases that can be used for the detection of tumors and other skin lesions. As such, we decided to recreate downsized images that can be used as practice.
What it does
We used a variation of Generative Adversarial Networks (GANs) to use downsampled images from the HAM10000 dataset to recreate 32x32 images. The Autoencoder generative adversarial network (AEGAN) is a variation of GANs aiming . The model manages to recreate skin lesion images, but it produced a checkerboard pattern preventing the model to further improve.
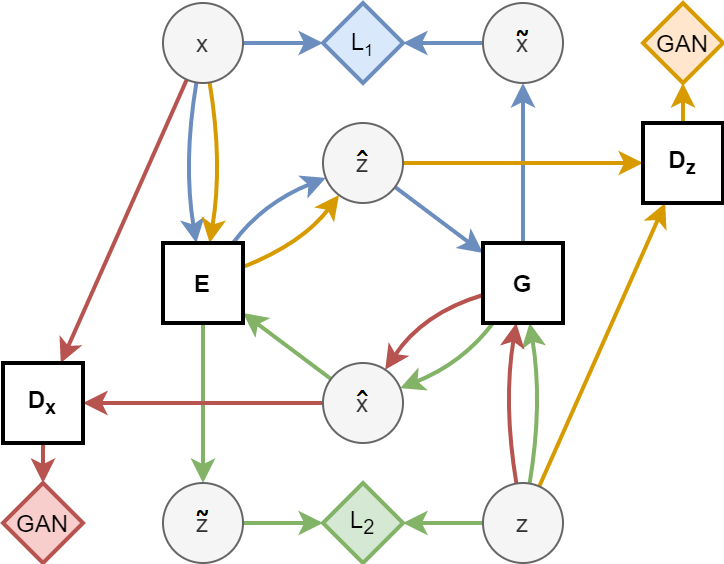
Overview of the algorithm
In GANs, a generator and an encoder-discriminator play a tug of war; the generator wants to create images as real-looking as possible and the encoder wants to distinguish te generated images from real images with the highest certainty and outcome. With AEGANs, there are two similar neural networks which operate similarly but on encoded and generated images and latent space images. Each of these neural networks learn from stochastic gradient descent. Since the algorithm is very sensible, it is mandatory to fine-tune the learning hyperparameters and to find the optimal sweet spot.
When generating and encoding images and images in latent space, we use multiple layers of 2d convolution and transposed convolution. Although it is straight-forward, it is important to be creative depending on the type of data as a poorely built model will learn in only a certain way.
Challenges
GANs are notoriously hard to train and to diagnose. Here are some issues we encountered and how we addressed them:
Vanishing gradient This occurs when the encoder-discriminator becomes too strong compared to the generator. In order to do fix this, we reduce the learning rate of the discriminator, we change the value of true and false label to 0.95 and 0.05 rather than 1 and 0 and we randomly zero some of the discriminator outputs.
Mode Collapse This can be seen in the final image where some of the fake images look similar. It is a similar issue to overfitting where
Checkerboard artifacts In the generator, instead of simply running deconvolution layers, we first upsample the image before doing a convolution on itself.
Unfortunately, the architecture of this algorithm is not robust enough yet to allow. We ran the almost same algorithm with 32x32 game sprites and obtained a much better outcome: Why is the model better at recreating intricate pixel art than skin marks? We don't know :).
What's next for Skin Autoencoder GAN
As pointed out, there are many issues with the outputs and the model still needs fine-tuning. Ideally after, we would like to reproduce images on a 256x256 scale. An interesting direction to accomplish this is to first train downsampled 2x2 images, then use the layer already trained for 4x4 images and repeat to any image size.
Useful resources
Original AEGAN paper Original AEGAN code Checkerboard artifacts Dataset






Log in or sign up for Devpost to join the conversation.