

Inspiration
We noticed a critical gap in professional training: the Cognitive Disconnect.
Whether it's a medical student studying anatomy or a factory worker reading a safety protocol, there is a massive gulf between reading a static PDF and facing a real-world scenario. Humans are visual learners, yet our training documentation remains stuck in dense, text-heavy formats.
We asked ourselves:
What if AI didn't just summarize a document, but actually read it, looked at the diagrams, and role-played it with you?
Thus, SkillSync was born — an autonomous Multi-Agent System that transforms passive documentation into active, visual, and audited simulations.
What It Does
SkillSync is not a chatbot. It is a coordinated swarm of AI agents that ingest technical documents to build immersive training scenarios.
👁️ Visual Perception Agent (PaddleOCR)
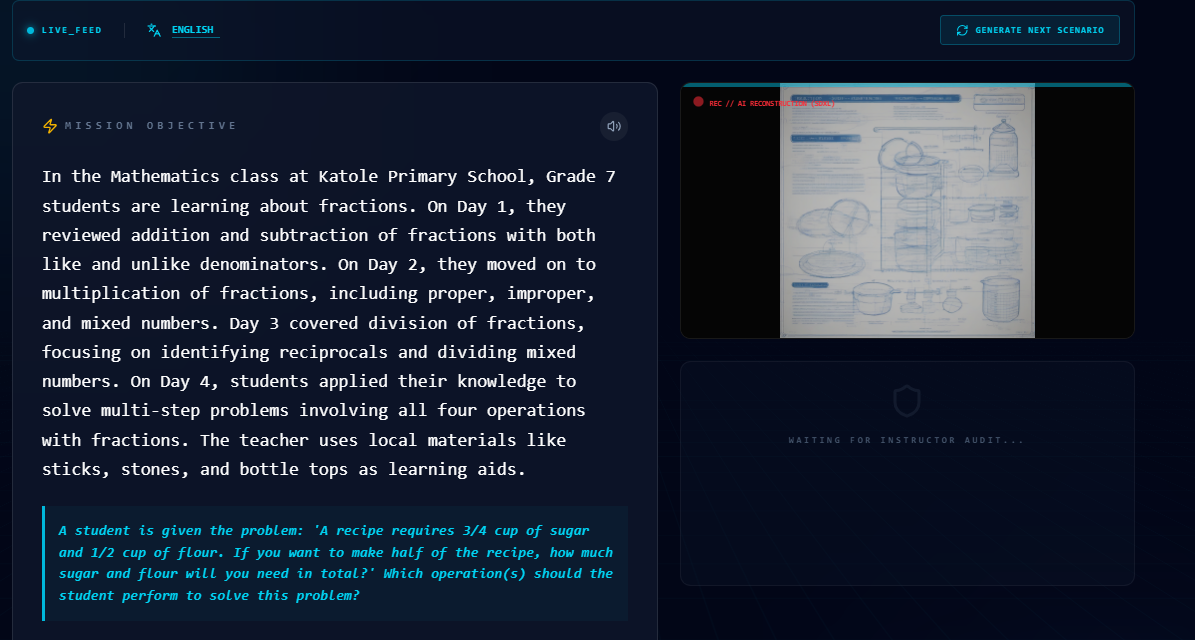
Unlike standard LLMs that ignore images, our Visual Agent scans the PDF to extract charts, blueprints, and biological diagrams. It sees what the text describes, allowing the system to generate questions about visual elements
(e.g., “Identify the specific valve in this schematic”).
🧠 Instructional Architect (CAMEL-AI + ERNIE)
Using the CAMEL-AI framework, an Architect agent analyzes the content and designs a high-stakes scenario. It uses ERNIE-4.0 as a dynamic Dungeon Master, creating adaptive storylines in English, Spanish, or Chinese.
⚖️ Compliance Auditor (Adversarial Agent)
To solve the AI hallucination problem, we built a separate Auditor agent. It strictly cross-references every user answer against the source text. If the AI cannot find a citation in the PDF, it rejects the feedback.
How We Built It
We moved beyond simple API calls to a Multi-Agent Orchestration Architecture:
- The Framework: CAMEL-AI manages the handshake and message passing between specialized agents (Architect vs. Auditor).
- The Brain (Logic): Baidu’s ERNIE-4.0 (via AI Studio) provides the reasoning core, chosen for its superior cross-lingual logic and long-context understanding.
- The Eyes (Vision): PaddleOCR acts as the visual cortex, extracting text layout and diagrams while preserving spatial context.
- Lite vs. Pro Cloud Strategy:
- Pro Mode: Runs locally with full PaddleOCR for deep analysis
- Lite Mode: Runs on Render (Docker) with lightweight drivers to guarantee 24/7 uptime for judges
- Pro Mode: Runs locally with full PaddleOCR for deep analysis
Challenges We Ran Into
🧩 Context Blindness of LLMs
Standard models read text but missed diagrams.
Solution: A dedicated Visual Perception Agent using PaddleOCR feeds visual data into the context window, effectively giving ERNIE eyes.
🎭 The Hallucinating Tutor
Early versions invented safety rules.
Solution: An adversarial CAMEL workflow where the Auditor debates the Instructor before results are shown.
💾 Resource Constraints
Running PaddleOCR and an agent swarm requires heavy RAM.
Solution: Optimized Docker images and a Lite fallback mode for cloud deployment.
Accomplishments We’re Proud Of
True Multimodal Integration
Seamless fusion of Text (ERNIE) and Vision (PaddleOCR). The system doesn’t just read — it looks.Autonomous Agent Coordination
Two independent AI personas (Teacher vs. Auditor) collaborating on a single request.The “Babel Fish” Capability
Upload a complex medical anatomy PDF in English and instantly simulate a diagnosis scenario in Spanish — with zero latency.
What We Learned
- Agents > Chatbots: Specialized agents dramatically improve accuracy.
- Vision Is Critical: In technical training, diagrams often matter more than text.
- Verification Is Mandatory: Adversarial auditing eliminates hallucinations.
What’s Next for SkillSync
- 🎙️ Voice-Activated Simulations for hands-free training
- 🥽 AR Overlays projecting schematics onto real equipment
- 🤝 Team Swarm Mode enabling multiple users to collaborate in the same simulation

Log in or sign up for Devpost to join the conversation.