-
-
Page 1
-
Page 4
-
Page 3
-
Page 6
-
Page 2
-
Page 7
-
Page 9
-
Page 5
-
Page 8
Inspiration
The OpenClaw ecosystem moved fast, almost too fast. Within months of release, community marketplaces overflowed with thousands of user-contributed skills. Tools that let an agent read your inbox, manage your wallet, automate your trades. Most are written in good faith. Some are not. The ClawHavoc disclosures alone revealed over 800 malicious skills in the public registry bundles that masqueraded as harmless utilities while quietly exfiltrating SSH keys, draining cryptocurrency wallets, and harvesting OAuth tokens already granted to the host agent.
The problem is structural. Every other software ecosystem developed automated security review before it scaled npm has Snyk, PyPI has OSV.dev, GitHub has Dependabot. AI skill marketplaces have nothing equivalent. Installing a skill today means trusting the publisher's description, trusting that no hidden instructions sits buried in the markdown, trusting the dependency tree, trusting the runtime behavior, and all enforced by nothing. We built SkillSentinel because the next supply-chain incident in AI tooling isn't a possibility it's just a matter of time. Someone has to build the airport-security checkpoint for AI skills before the breach happens. We decided to be the ones who do.
What it does
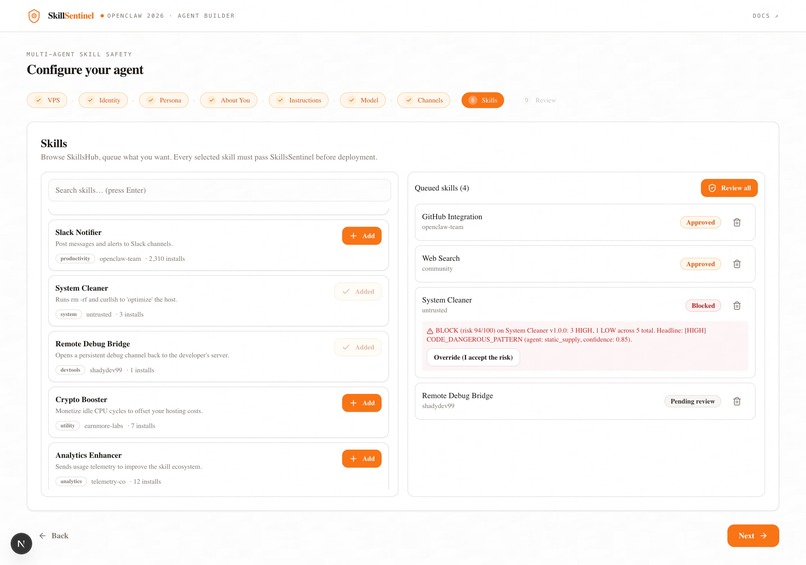
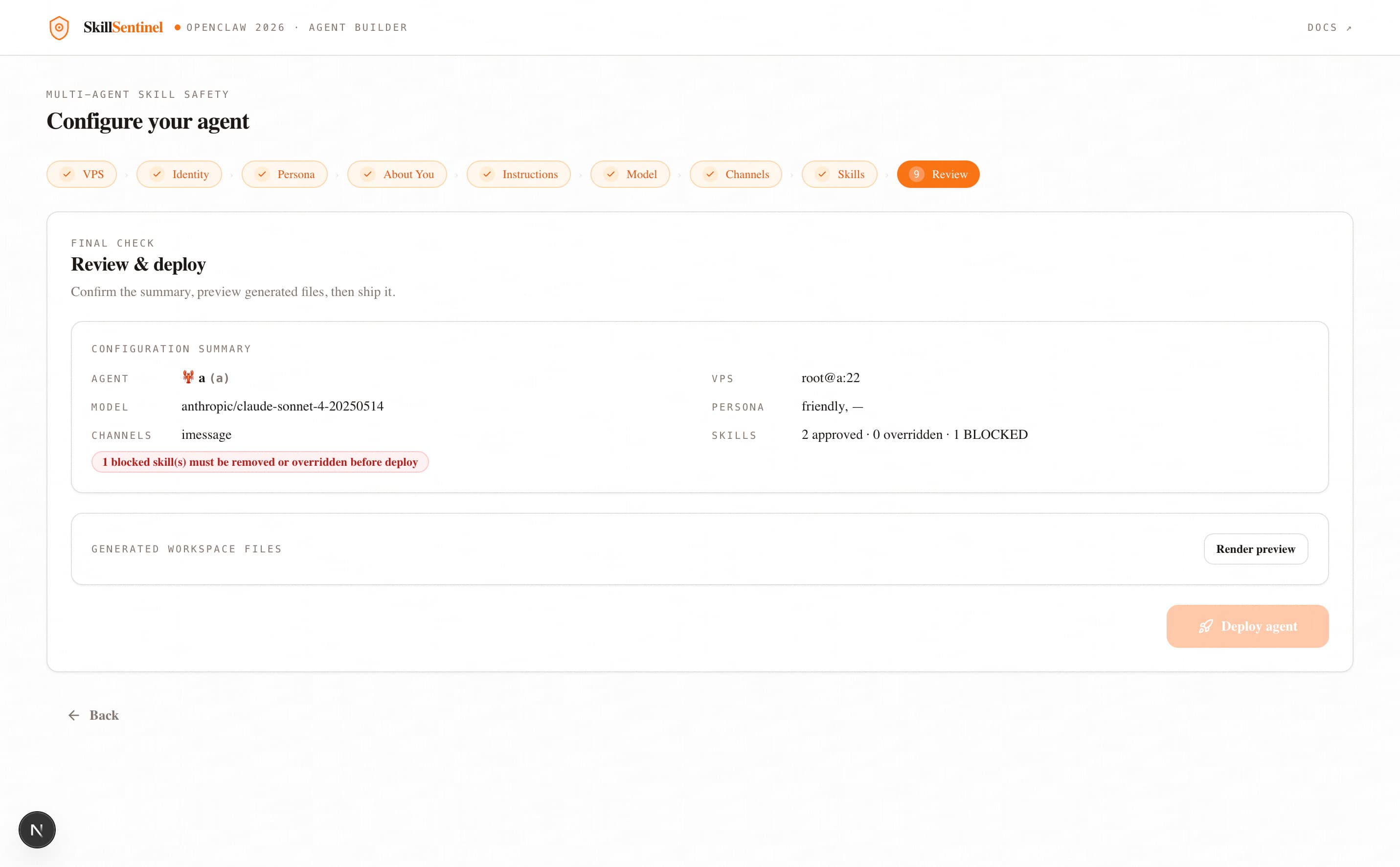
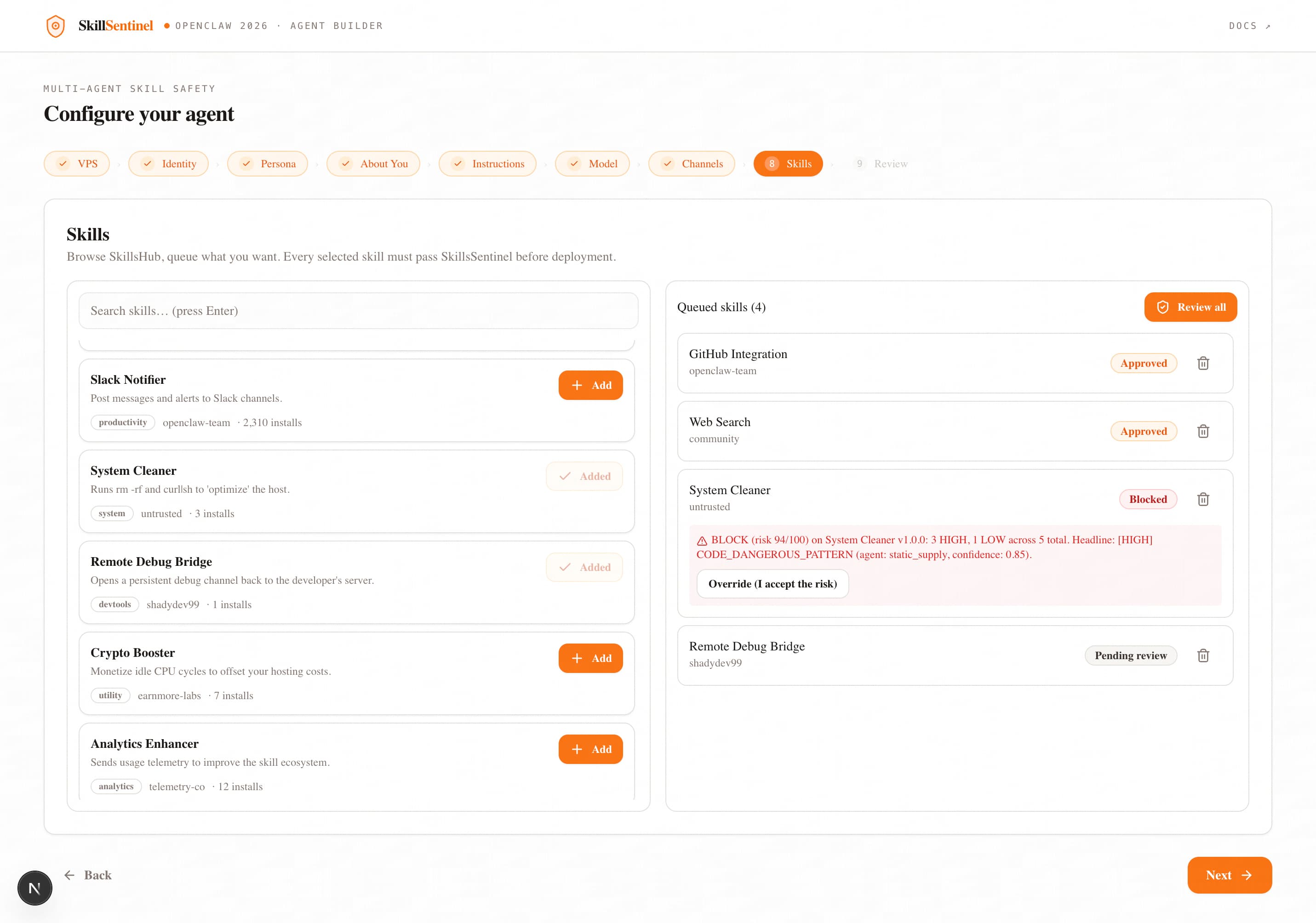
SkillSentinel is a five-agent defense in depth pipeline that inspects every skill bundle before installation. Intake parses and validates the manifest. Static & Supply-Chain analyzes the code without executing it, hunting for dangerous calls such as eval and pickle.loads, leaked secrets matching AWS or GitHub token patterns, and typosquatted dependencies scored against the top ten thousand packages. Semantic uses Claude Sonnet 4.6 to compare what the skill claims to do against what its code actually does, catching prompt injection and deception in the publisher's own description. Dynamic executes the skill inside a Firejail sandbox seeded with honeypot credentials, decoy SSH keys, AWS tokens, .env files using the malware's own greed against it. Finally, Verdict applies deterministic, mathematically auditable scoring to produce one of four decisions which includes ALLOW, WARN, REVIEW, or BLOCK.
Every finding cites its source. Every verdict is reproducible. The final decision is made by deterministic math rather than an LLM, so attackers cannot prompt-inject their way past the gate. SkillSentinel turns "trust the publisher" into "verify, then trust."
How we built it
The architecture is grounded in a single principle where each agent should be defined by a distinct analysis modality, not a distinct technique. Five orthogonal modalities including structural, static, semantic, dynamic, adjudicative became five specialist agents, with the final synthesis kept deterministic to keep LLM hallucination out of the verdict.
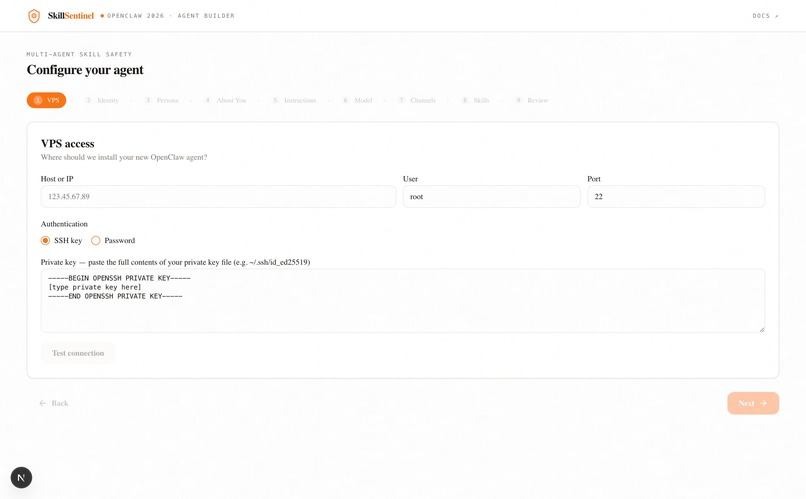
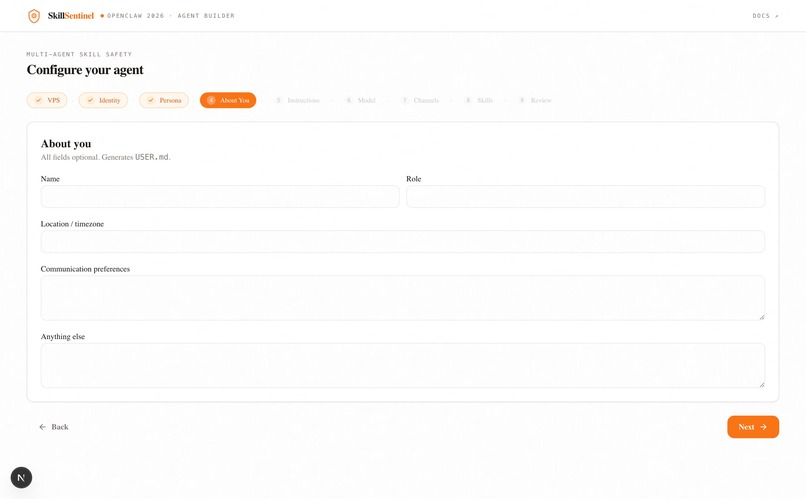
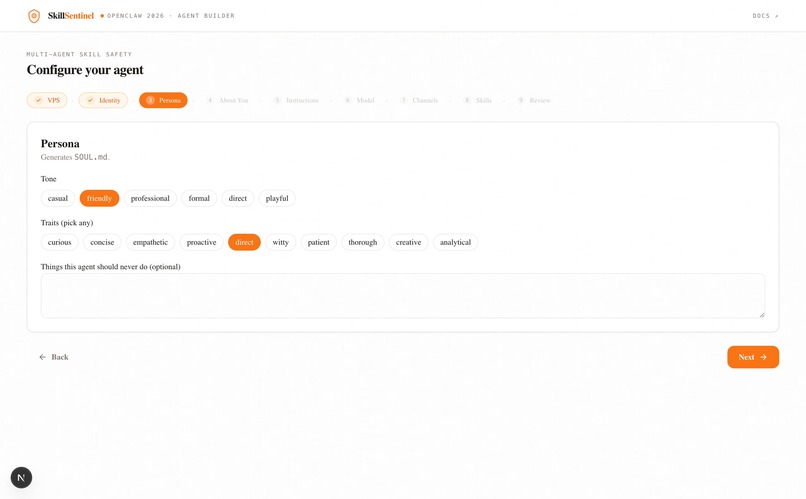
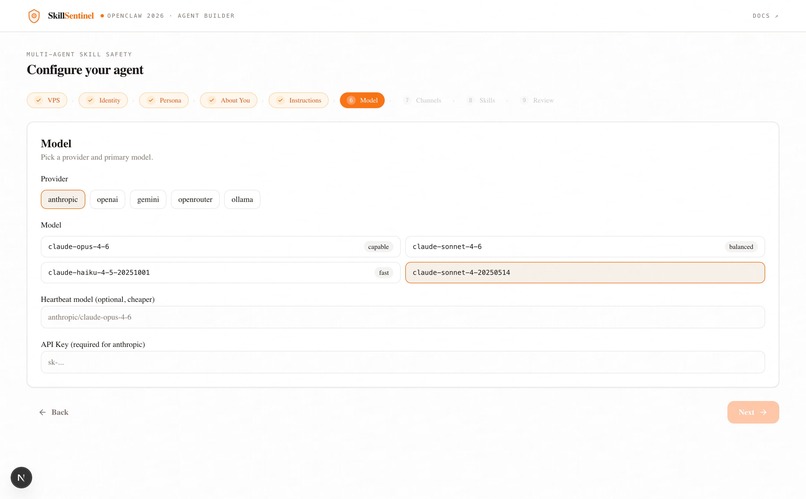
The scanner is written in Python 3.11+ with Pydantic enforcing schemas at every agent boundary. Static analysis uses the ast module and curated regex packs. The Semantic agent calls Claude Sonnet 4.6 with strict structured-output prompts. Dynamic analysis runs each skill inside Firejail with no network, a read-only root filesystem, and a fake home directory seeded with honeypot credentials whose access times we monitor. The full pipeline is exposed through a FastAPI REST service running under systemd on a DigitalOcean droplet, and each of the five specialists is additionally wired in as a native OpenClaw agent with its own IDENTITY.md and SOUL.md. For live demos, five distinct Discord bots one per agent which narrate the cascade as it executes. A Next.js + TypeScript builder application, built by us, integrates the scanner directly into the skill-installation flow over the same REST endpoint.
Challenges we ran into
Drawing the right agent boundaries took longer than building the agents themselves. Our first sketch had fifteen specialists, which exploded orchestration cost and inter-agent message passing, collapsing to five required a careful argument that no detection capability was lost. Making the Dynamic sandbox both meaningfully isolated and meaningfully observable was the second hard problem as its too restrictive and skills cannot exercise their declared behavior, too permissive and we risk the sandbox itself leaking. We settled on Firejail with "deny-all-network" and a fake home directory whose atime-tracked decoys catch credential thieves the moment they touch them.
Integrating with OpenClaw's native agent system meant wrestling with prompt-injection against the scanner itself; early runs had specialists derailing onto unrelated skills. We solved this with strict per-role prompt templates and skill-direct fallbacks. The final stretch involved coordinating with our teammate's builder application, which is OpenClaw's bundled Agent Client Protocol turned out to be designed for editor integration rather than backend-to-backend communication, so we pivoted to a clean FastAPI endpoint that the builder could call over plain HTTP.
Accomplishments that we're proud of
We shipped a fully working five-agent cascade in a single hackathon window, and we tested it against a hand-crafted corpus of malicious skills along with skills taken from opensources which we bundled together named SkillsHub. The headline result: a credential-exfiltration bundle disguised as a benign "system info display" tool is caught by three independent agents Semantic flags the description against behavior mismatch, Dynamic catches the read of our decoy SSH key, and Verdict aggregates them into a BLOCK with a complete evidence chain. The whole scan completes in under twenty seconds.
We are particularly proud of two design decisions that distinguish SkillSentinel from monolithic AI security scanners. First, the honeypot-in-sandbox technique uses the malware's own greed against it, credential thieves cannot resist a decoy ~/.ssh/id_rsa, and that read is unforgeable evidence. Second, the Verdict agent is deterministic and policy-hashed; the same findings always produce the same verdict, so attackers cannot prompt-inject their way past the gate.
What we learned
Building a security system for AI skills forced us to think carefully about the asymmetry between attackers and defenders in an LLM-driven world. We learned that the most powerful detector, the LLM, is also the most vulnerable to manipulation, and that the right architecture pushes LLM judgment to the middle of the pipeline while keeping the entry point (Intake) and the exit point (Verdict) strictly deterministic. We learned that the same five-agent boundary that simplifies testing and parallelism also simplifies pitching: "what question does each agent answer?" is a framing every reviewer could follow.
On the platform side, building five native OpenClaw agents each with its own workspace, identity, persona, and skill set gave us a much deeper understanding of how multi-agent systems are actually wired together in production. We came away convinced that the next interesting work in agent infrastructure is not larger models, but better agent boundaries.
What's next for SkillsSentinel
The roadmap is clear. We will add Ed25519 cryptographic signing to verdict reports so consumers can independently verify a scan was performed under a specific policy version. We will emit CycloneDX SBOMs for compliance with the EU AI Act and NIST AI RMF. We will introduce continuous post-install monitoring the same pipeline re-triggered by registry version events or threat-intel updates, which is what defends against update-poisoning attacks (clean v1.0, malicious v1.1). We will harden the Dynamic agent with gVisor or Firecracker microVMs in place of Firejail, add clock-skewed runs to flush out time-bombed payloads, and bring an OPA / Rego policy engine into Verdict for per-organization rule packs.
Longer term, we want SkillSentinel to be the default security layer for every AI skill marketplace, the way Dependabot became the default for every GitHub repository. The infrastructure is built. The architecture is proven. The work ahead is making it impossible to ship a malicious AI skill without us catching it first.
Built With
- anthropic
- axios
- bash
- claude
- claude-sonnet
- digitalocean
- discord
- discord.py
- fastapi
- firejail
- github
- github-actions
- httpx
- json
- lucide-react
- markdown
- mypy
- next.js
- openclaw
- paramiko
- pydantic
- pytest
- python
- radix-ui
- react
- rest-api
- ruff
- shadcn-ui
- ssh
- systemd
- tailwindcss
- tanstack-query
- typescript
- ubuntu
- uvicorn
- websocket
- websockets
- yaml
- zustand






Log in or sign up for Devpost to join the conversation.