-
-
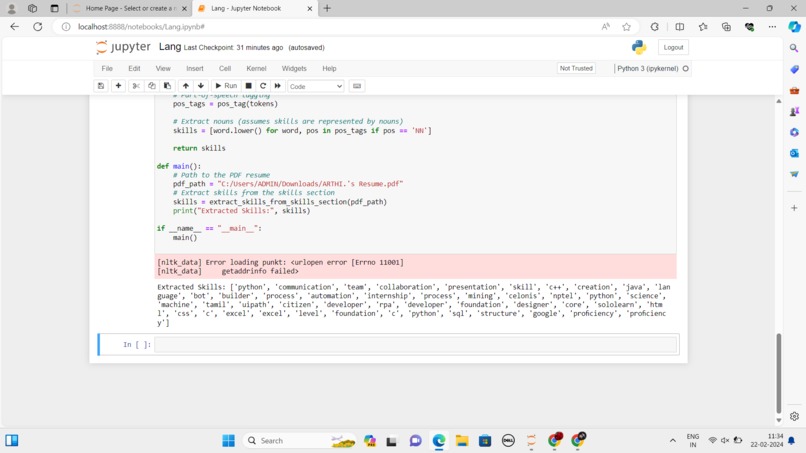
Skills Extracted
-


ML + Language
Inspiration
Inspiration for SkillScanner struck when recognizing the widespread challenge of efficiently matching job seekers with relevant opportunities. In a world flooded with resumes, extracting and understanding skills became a bottleneck. Witnessing this, the project aimed to streamline the hiring process by leveraging natural language processing to extract skills from resumes. The goal was to empower both job seekers and recruiters with a tool that transforms unstructured resume data into actionable insights.
What it does
SkillScanner revolutionizes the recruitment landscape by automating the extraction of key skills from resumes, facilitating efficient talent matching. This intelligent tool utilizes natural language processing techniques to analyze unstructured resume data, identifying and categorizing relevant skills. By transforming text-based information into actionable insights, SkillScanner empowers both job seekers and recruiters, streamlining the hiring process and fostering better connections between talent and opportunities.
How we built it
SkillScanner was meticulously crafted using a combination of advanced natural language processing (NLP) techniques and document parsing technologies. Leveraging the SpaCy library, we implemented named entity recognition to extract entities and categorize them. PyMuPDF played a pivotal role in parsing resumes in PDF format, with a special focus on accurately extracting information from the skills section. The development process involved fine-tuning tokenization and part-of-speech tagging to handle the diverse structures of resumes. Through iterative refinement and adaptation, SkillScanner emerged as a robust solution, bridging the gap between talent and opportunity in the recruitment process.
Challenges we ran into
Developing SkillScanner presented multifaceted challenges. Adapting to diverse resume formats required iterative adjustments. PDF parsing complexities posed another obstacle, demanding innovative strategies to address layout variations. Maintaining accuracy and flexibility throughout demanded continuous refinement and innovation.
Accomplishments that we're proud of
Successfully overcoming the challenges, SkillScanner stands as an accomplishment we're proud of. The system adeptly handles diverse resume formats, showcasing our commitment to adaptability. Tackling PDF parsing intricacies demonstrates our innovative problem-solving. The achievement lies not only in extracting skills but in the refined balance between accuracy and flexibility, empowering both job seekers and recruiters. SkillScanner's robustness reflects our dedication to creating a transformative tool for streamlining talent acquisition.
What we learned
Building SkillScanner provided invaluable lessons in navigating diverse data structures and handling PDF parsing intricacies. The project enhanced our understanding of natural language processing (NLP) techniques, particularly in entity recognition and categorization. It showcased the importance of iterative refinement to accommodate varying resume formats. This journey deepened our skills in adapting NLP models to real-world challenges and reinforced the significance of flexibility in handling unstructured data.
What's next for SkillScanner
The future for the SkillScanner app holds exciting possibilities. We envision expanding its capabilities to include a broader range of document types, transcending beyond traditional resumes. Integrating machine learning models for continuous improvement and adaptation to evolving job market trends is on the horizon. Collaboration features for recruiters and enhanced user interfaces for job seekers are also in the pipeline. Our roadmap includes refining the app's ability to handle multilingual resumes, ensuring a global impact. Ultimately, SkillScanner aims to be at the forefront of revolutionizing talent acquisition by embracing advancements in natural language processing and document analysis.

Log in or sign up for Devpost to join the conversation.