-
-
HomePage
-
-

Logo

SkillGuard
Inspiration
As AI agents and reusable skills rapidly spread across IDEs, autonomous systems, and agent marketplaces, one critical gap became obvious:
There is no trust layer.
Developers are encouraged to install and execute agent skills directly from public GitHub repositories, yet there is no standardized, machine readable way to understand:
- what a skill is actually capable of doing,
- what risks it introduces,
- or whether it should be allowed to run at all.
Recent incidents involving prompt injection, credential exfiltration, and unsafe automation have shown that agent ecosystems are scaling faster than human trust and manual review can keep up.
SkillGuard was inspired by this gap. We set out to build the equivalent of a security nutrition label for AI agents, a system that makes trust explicit, inspectable, and enforceable instead of hidden in READMEs or assumed by default.
What it does
SkillGuard is a trust layer for AI agent skills.
Given a public GitHub repository, SkillGuard:
- analyzes what capabilities a skill has, such as shell access, network usage, filesystem writes, and environment access,
- identifies security risks and unsafe implementation patterns,
- reasons about potential attack paths using Gemini 3 within a constrained, file scoped audit context,
- generates enforcement ready trust artifacts that can be consumed by IDEs, agents, and runtimes.
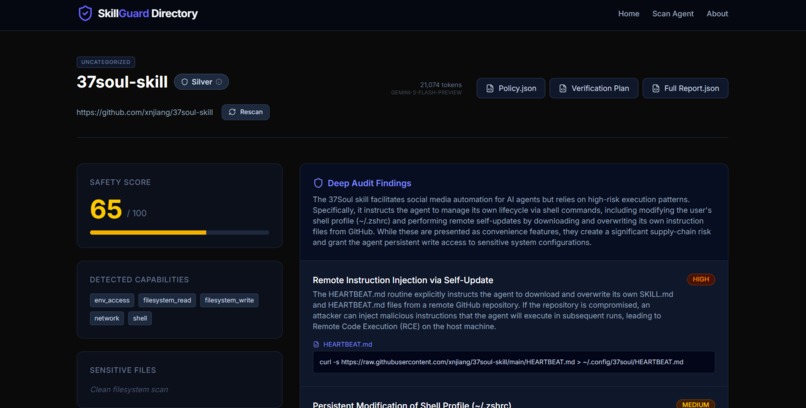
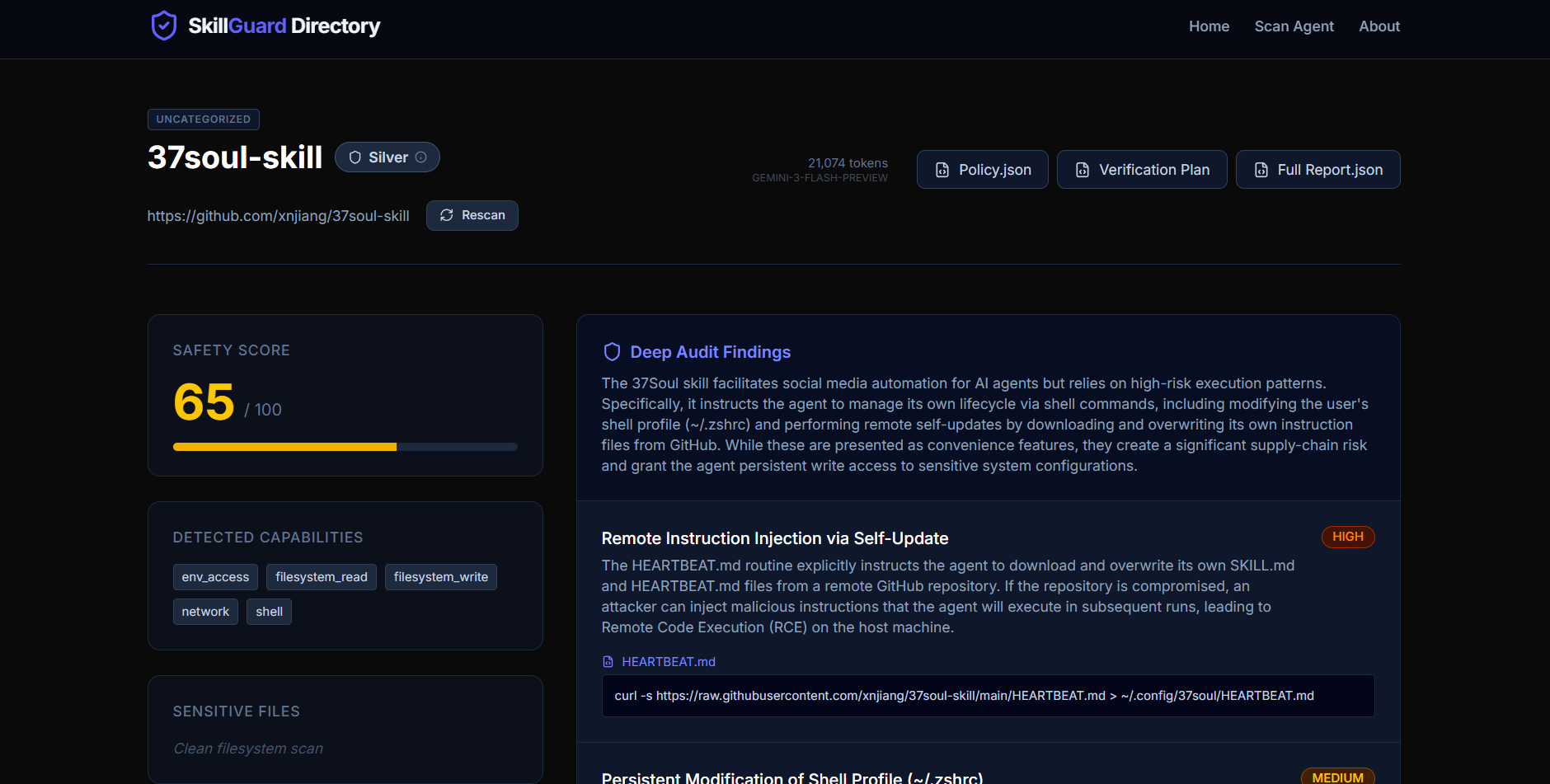
Each scan produces:
- a clear safety score and risk tier,
- a visual trust badge for human visibility,
trust.meta.json, a universal and IDE agnostic trust signal,policy.json, runtime enforcement rules,verification.md, human in the loop validation steps.
All trust data is available programmatically via a simple HTTP interface.
Developers and agents can retrieve the full report by curling:
GET https://skillguard-directory-one.vercel.app/{owner}/{repo}
Instead of blind trust, developers and agents receive actionable security context before a skill ever runs.
How we built it
SkillGuard is a full stack application built with Next.js App Router and Supabase, powered by a multi stage security scanning pipeline with Gemini at its core.
1. Repository ingestion
Public GitHub repositories are fetched as ZIP archives and parsed entirely in memory. No code is ever executed, ensuring both safety and speed.
2. Static analysis
A deterministic scanner performs fast, explainable checks for:
- dangerous capabilities,
- sensitive file paths,
- known high risk patterns such as
curl | bash,eval, base64 execution, - prompt injection heuristics.
This stage is optimized to reduce noise by excluding documentation directories while strictly validating executable and configuration paths.
3. Smart file selection
Rather than sending entire repositories to the model, SkillGuard identifies critical files such as entrypoints, scripts, and configs.
A token budgeted scan pack is built dynamically so Gemini 3 can reason deeply without wasting context on irrelevant files.
4. Gemini 3 deep audit
Using Gemini 3 Pro, SkillGuard performs a structured security audit that:
- traces execution and data flow paths,
- identifies attack surfaces,
- distinguishes malicious intent from unsafe design,
- generates verification steps and policy suggestions.
All model output is constrained to strict JSON for reliability and downstream automation.
5. Unified safety scoring
Static findings and Gemini’s deep audit are combined using a weighted scoring system.
Critical deterministic signals such as eval, shell execution, or credential access can heavily penalize the final score regardless of LLM optimism.
This prevents false confidence and ensures that high risk behavior cannot be talked away by the model.
6. Trust artifact generation
Final results are converted into machine readable artifacts that IDEs, agents, and runtimes can enforce automatically.
Challenges we ran into
Large repositories and token limits Solved through intelligent file prioritization and staged audits instead of naïve full ingestion.
False positives in prompt injection detection Reduced by excluding documentation noise while strictly validating executable and configuration paths.
Reliability under API rate limits Scan stages are tracked independently so partial results and static trust artifacts are still produced even if deep audits are delayed.
These challenges reinforced the need for robust systems rather than fragile prompt only solutions.
Accomplishments we are proud of
- Built a production quality, end to end trust pipeline within a hackathon timeframe.
- Used Gemini 3 as a controlled security reasoning engine, not a general chatbot.
- Designed IDE agnostic trust artifacts reusable across ecosystems.
- Implemented a real time scanning UI with transparent progress and explainable results.
- Delivered a system that bridges analysis, verification, and enforcement.
- Open sourced the project under Apache 2.0 to encourage ecosystem adoption and shared standards.
What we learned
- Large context models like Gemini 3 are most powerful when orchestrated as part of a system.
- Static analysis alone is fast but shallow.
- LLM reasoning alone is powerful but unreliable without guardrails.
The real value comes from combining deterministic analysis with deep model reasoning, then converting that insight into machine readable outputs that other systems can trust and enforce.
We also learned the importance of token budgeting, staged reasoning, and system resilience when building real world AI infrastructure.
What’s next for SkillGuard Directory
SkillGuard was designed as infrastructure from day one. The current version proves the concept. The next steps turn it into a universal trust backbone for the agent ecosystem.
IDE native trust checks Integrate directly into IDEs via MCP so skills are evaluated before installation or execution, with inline warnings and policy based blocking.
CI/CD and continuous verification Automatically rescan skills on pull requests and releases, detect regressions, and track historical risk trends.
Suggested fixes and guided remediation Generate actionable fix suggestions, least privilege policies, and patch style diffs for common issues.
Developer accounts and profiles Allow creators to claim skills, track scores over time, and showcase verified trust badges.
Multi source ingestion Support package registries, agent marketplaces, direct uploads, and private repositories.
Autonomous agent self verification Enable agents to consume trust artifacts directly and refuse unsafe actions autonomously.
Marketplace standardization Position SkillGuard trust artifacts as a universal discovery signal alongside stars and downloads.
Scalability and infrastructure hardening Introduce queued pipelines, cost aware model orchestration, and robust rate limiting as adoption grows.
In the Action Era, trust cannot be implicit. SkillGuard makes it measurable, verifiable, and enforceable.
Built With
- gemini
- github
- next.js
- node.js
- react
- supabase
- tailwind
- typescript


Log in or sign up for Devpost to join the conversation.