
🔥 Inspiration
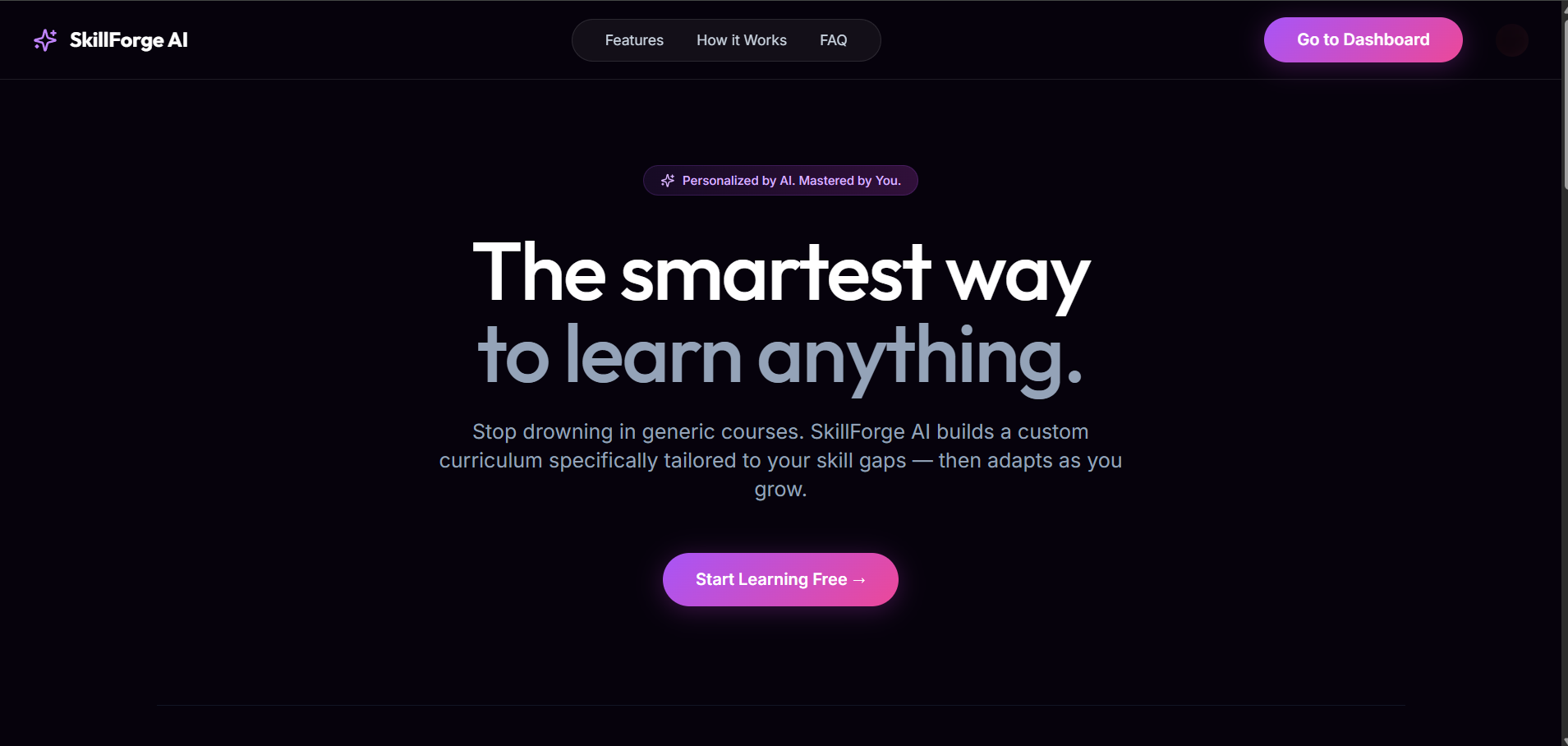
Every year, the tech industry loses billions forcing talent through generic, one-size-fits-all onboarding. Experienced hires waste up to 40% of their time on redundant training modules, while freshers get overwhelmed because they don't know exactly which micro-skills they are missing. We set out to fix this broken system — not with another course catalog, but with an intelligent, AI-native engine that adapts to each individual learner.
🧠 What It Does
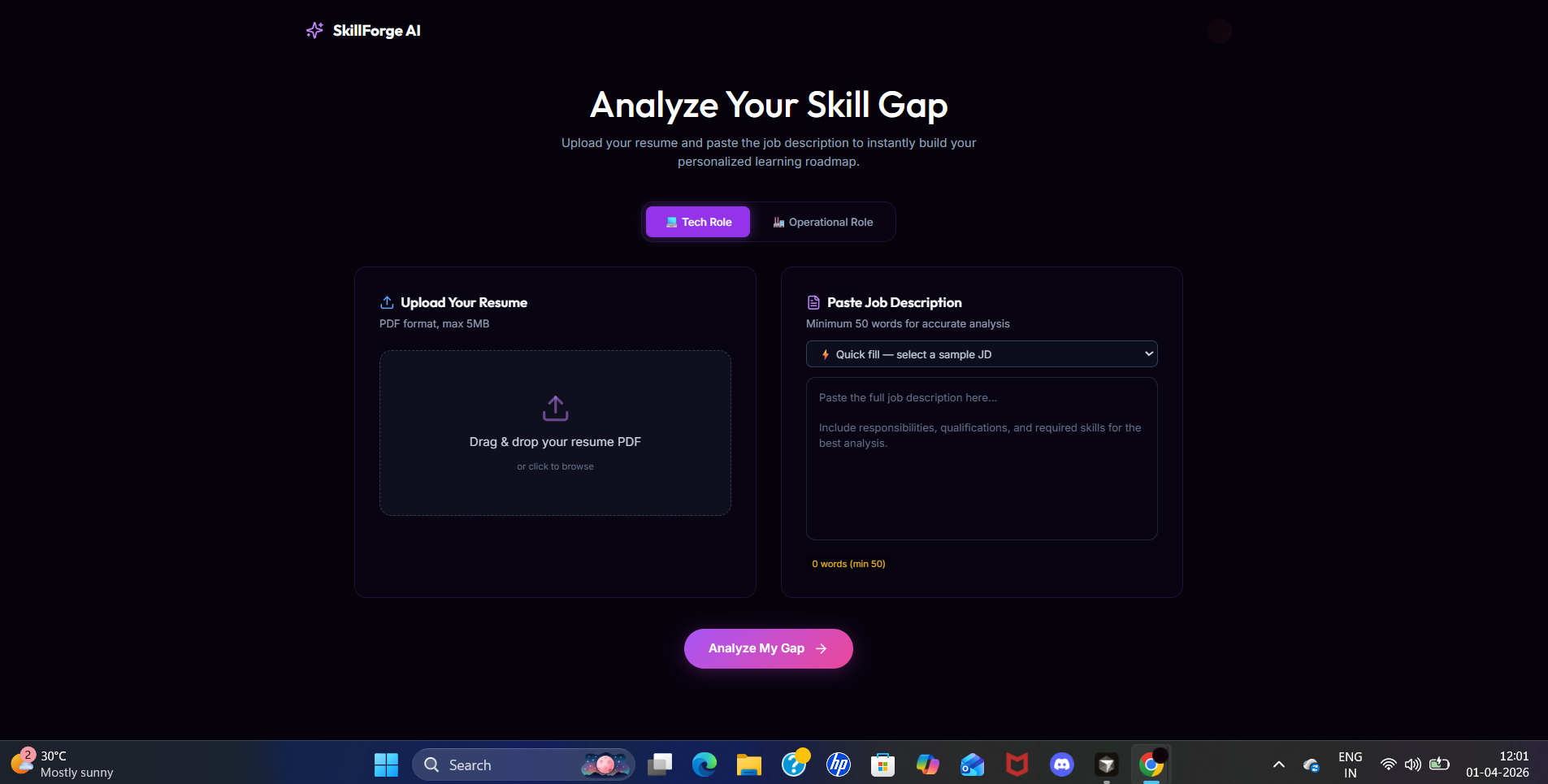
SkillForge is a unified AI ecosystem that takes a candidate's Resume (PDF) and a target Job Description, then:
- Extracts skills using Google Gemini 2.5 Flash with structured JSON outputs validated by Pydantic schemas.
- Calculates the precise skill gap using a Semantic Embedding Pipeline (
text-embedding-004) that computes Cosine Similarity — so the engine understands that "React.js" satisfies "Frontend Development." - Constructs a Directed Acyclic Graph (DAG) using NetworkX to logically sort foundational prerequisites before advanced modules.
- Generates an adaptive, gamified roadmap rendered as a 60fps interactive React-Flow topological map with color-coded severity nodes (Critical / Partial / Near-Competent).
- Embeds the top 6 curated YouTube masterclasses per skill gap directly into the dashboard using a Zero-Auth Protobuf Proxy, completely bypassing restricted API quotas.
- Exports a personalized 6-page AI curriculum PDF with weekly study schedules via jsPDF.
- Hosts a real-time Multiplayer Quiz Arena where users challenge peers in host-controlled waiting rooms, ending in a post-match AI analytics dashboard that explains every incorrect answer.
- Includes a NotebookLM-Style AI Mentor — paste any youtube video URL,article or doc site, and Gemini instantly synthesizes the lecture into condensed, actionable learning takeaways.
🏗️ How We Built It
Backend Architecture:
- Built an asynchronous Python server on FastAPI with Pydantic v2 schemas for strict request/response validation.
- Engineered a Semantic Embedding Pipeline using Google's
text-embedding-004API to vectorize and compare skills via mathematical Cosine Similarity, replacing heavy local PyTorch models to stay under Render's 512MB RAM limit. - Constructed skill prerequisite graphs using NetworkX DAGs, then ran topological sorting to generate logically ordered learning paths.
- Invented a Dual-Pronged Token Load Balancer that dynamically cascades from
gemini-2.5-flashtogemini-2.0-flashif Google's rate limits are hit, guaranteeing 100% API uptime. - Built a Zero-Auth Protobuf YouTube Proxy using
youtube-search-pythonwith a customhttpxcompatibility patch to scrape and rank videos by view count and channel reputation — no API key required.
Frontend Architecture:
- Built a multi-page React SPA with React Router and Clerk authentication.
- Rendered the adaptive roadmap using React Flow with animated edges, custom node styles, and real-time progress tracking with confetti celebrations on module completion.
- Designed a responsive, glassmorphic dark-mode UI with dynamic micro-animations and hover effects.
Real-Time Features:
- Engineered an asynchronous Multiplayer Quiz Arena with host-controlled lobbies, live scoreboards, and individual answer tracking.
- Built a Post-Match AI Analytics Dashboard that maps each player's historical selections against AI ground-truth explanations.
- Integrated a NotebookLM-Style AI Mentor pane that uses Gemini's native
Part.from_urito directly ingest YouTube video URIs and produce structured learning summaries.
🧱 Challenges We Faced
- Gemini API Rate Limits (429 RESOURCE_EXHAUSTED): Free-tier Gemini only allows 250K tokens/minute. During rapid testing, we burned through quotas instantly. We solved this by building a cascading model failover system and aggressively compressing input payloads by 80%.
youtube-search-python+httpxCollision: The YouTube scraping library crashed onhttpx >= 0.28because of a deprecatedproxieskeyword. We surgically patched the library's internal HTTP layer to use the modernproxysyntax, then vendored the fixed version directly into our repo.- Render 512MB RAM Ceiling: Local TensorFlow embedding models caused instant Out-Of-Memory crashes on Render's free tier. We completely pivoted to Google's cloud-hosted
text-embedding-004API, dropping RAM usage to near zero.
📚 What We Learned
- How to engineer production-grade API rate-limit resilience using cascading model failover strategies.
- How to construct and traverse Directed Acyclic Graphs for real-world prerequisite dependency resolution.
- How to build Zero-Auth proxy scrapers that bypass restrictive API quotas using internal Protobuf endpoints.
- How to patch and vendor third-party Python packages to resolve deep dependency conflicts in cloud deployment environments.
- How to design glassmorphic, gamified UIs that keep learners engaged through visual progress tracking and micro-animations.
Built With
- beautifulsoup4
- clerk
- docker
- fastapi
- google-gemini-2.5-flash
- google-text-embedding-004-api
- httpx
- javascript
- jspdf
- networkx
- postgresql
- pydantic
- pymupdf
- python
- react
- react-flow
- react-router
- render
- supabase
- vercel
- vite
- youtube-search-python



Log in or sign up for Devpost to join the conversation.