-
-

Logo
-
Flowchart
-
Test script result
-
Test script result
-
Test script result

Website - https://bit.ly/skillforgeweb
Inspiration
As sophomores in engineering institutes in India, we have constantly been under the immense pressure of securing a good internship offer and thus have been constantly working towards building our profile. The current job market is intense and with the availability of so many resources online, it is hard to figure out what'd work best for you.
"In the face of adversity, we have two choices: we can be bitter or better". Now in June 2024, we are faced with the immense challenge of preparing for the upcoming internship season. Confronted with this challenge, we saw this hackathon as a great opportunity to enhance our skills while offering valuable support to others in similar situations.
The rise of Large Language models has clearly revolutionized the internet and leveraging their ability to create something so personalized for the user with little cost was our motivation. Most of our team members have delved into Retrieval Generated Augmentation before and it proved to be a key aspect of our program to provide the user with a rich corpus of interview questions we gathered to practice.
Normally when one prepares for an interview, most of their time goes into grinding LeetCode questions. We believe that actually taking interviews makes you a lot more confident about facing them than just LeetCode. Thus, the idea to simulate entire interviews leveraging LLMs was a game-changing idea - using text-to-speech and speech-to-text models we managed to build a decent interview simulator.
What it does
We use multiple agents built in Vertex AI Agent Builder to facilitate the various features we offer. For the Interview Simulation, we employ Retrieval Augmented Generation from a Corpus of Interview Questions to enrich the questions asked by our interviewer. We also employ the use of Codeforces API to be able to conduct coding questions during the interview.
Backend
The backend infrastructure is built with OpenAPI and Python, employing the Retrieval-Augmented Generation (RAG) methodology to enrich interview questions.
Frontend
We employ the Chainlit Library in Python to build our frontend and deploy it through Docker on Google Cloud Run
Summary
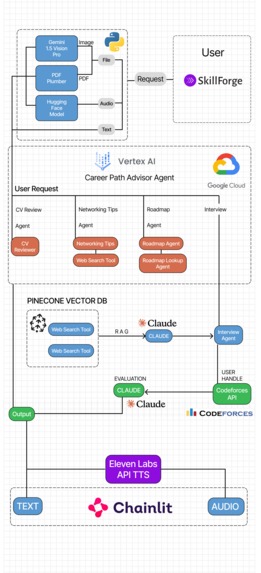
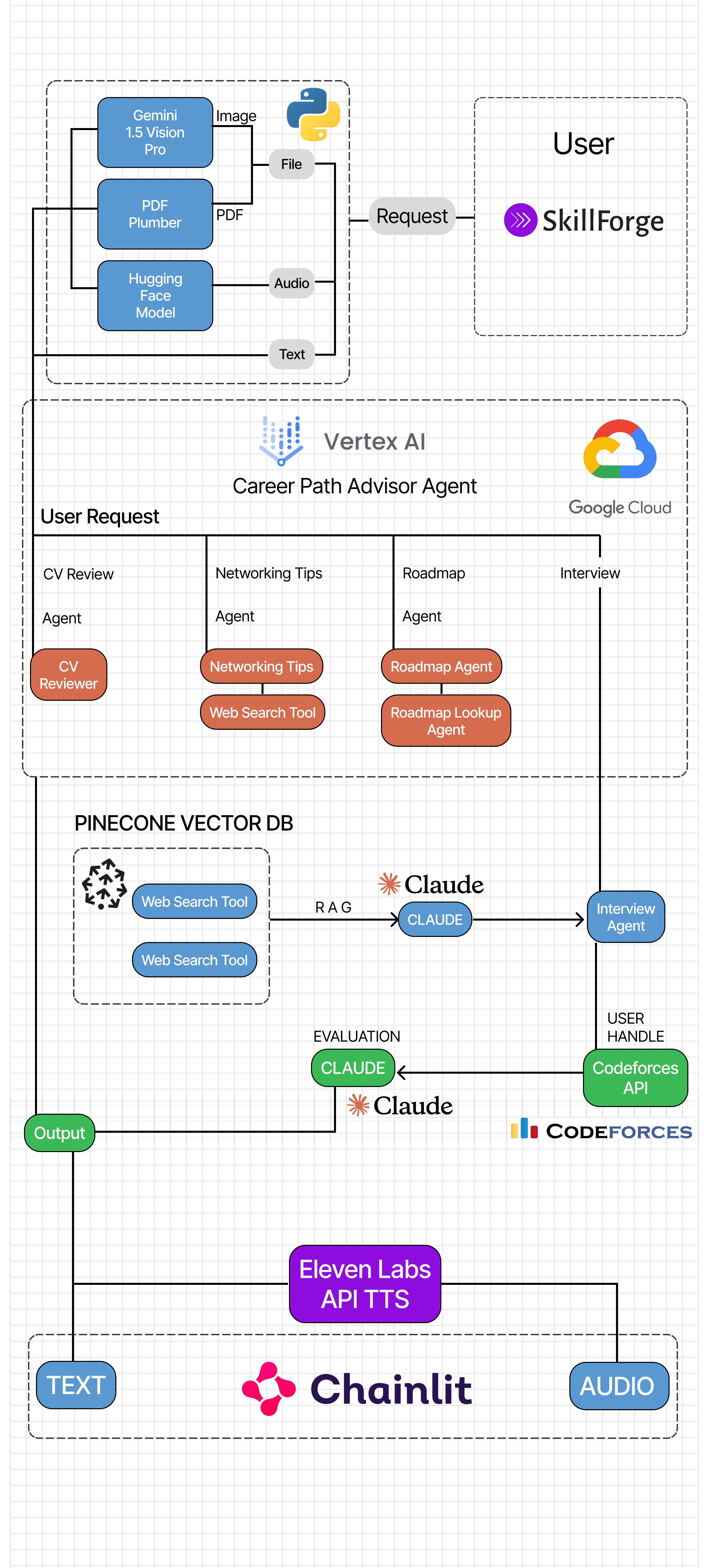
Essentially, we built multiple agents in Vertex AI Agent Builder suited for different purposes. We have a main general-purpose Agent that invokes other Agents as needed as well as any tools that it might need. When a user, say asks for a Roadmap, it invokes the Roadmap Agent which in turn invokes the "WebSearch" Tool to browse the internet and give the user a customized roadmap for them with resources. Interview experience is enhanced by RAG and utilisation of the Codeforces API, making it a very seamless experience for anyone to get some interview practice with a detailed feedback at its end.
How we built it
We have used chainlit as our frontend for this project, which is an interface for the user and the underlying LLM. We will explain our whole
pipeline through the flowchart image.
So first of all user enters a request , it can be any request such as "Improve my CV" or "I want to start an interview".
Our app provides two different chat profiles for the user's requirements:
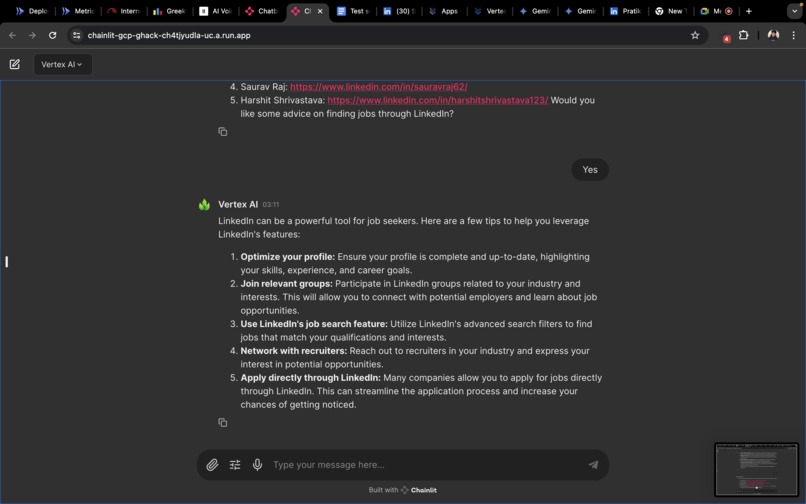
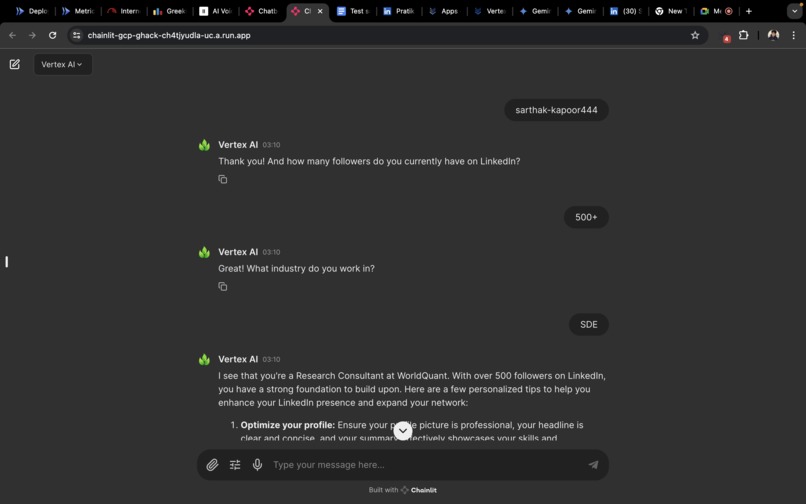
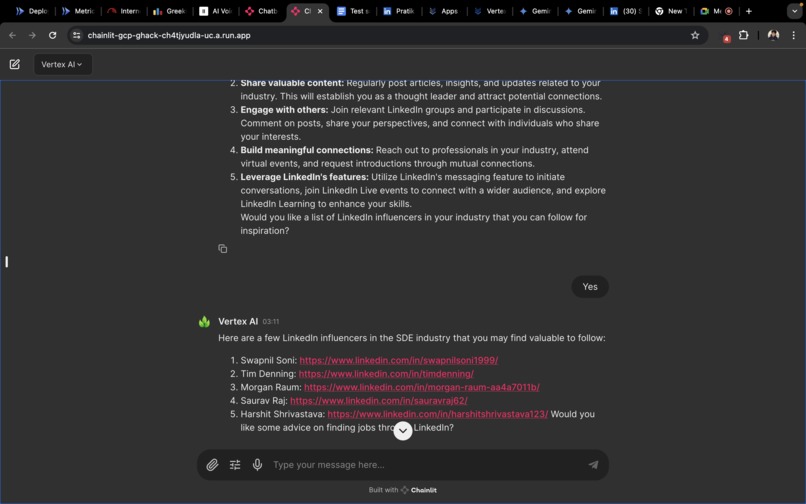
- Vertex AI : Capable of handling tasks such as CV review, providing networking tips and connection opportunities ,providing career roadmaps etc.
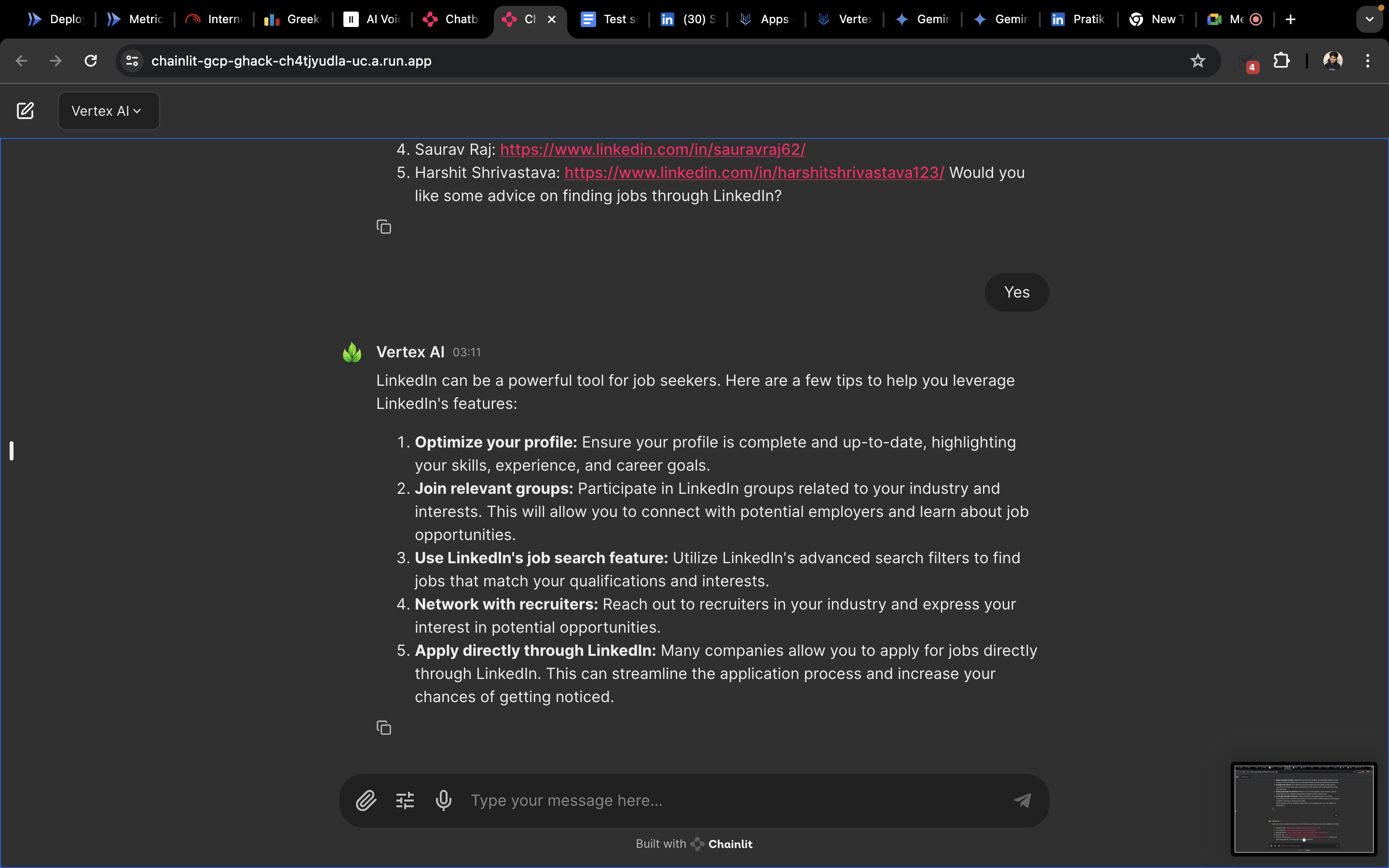
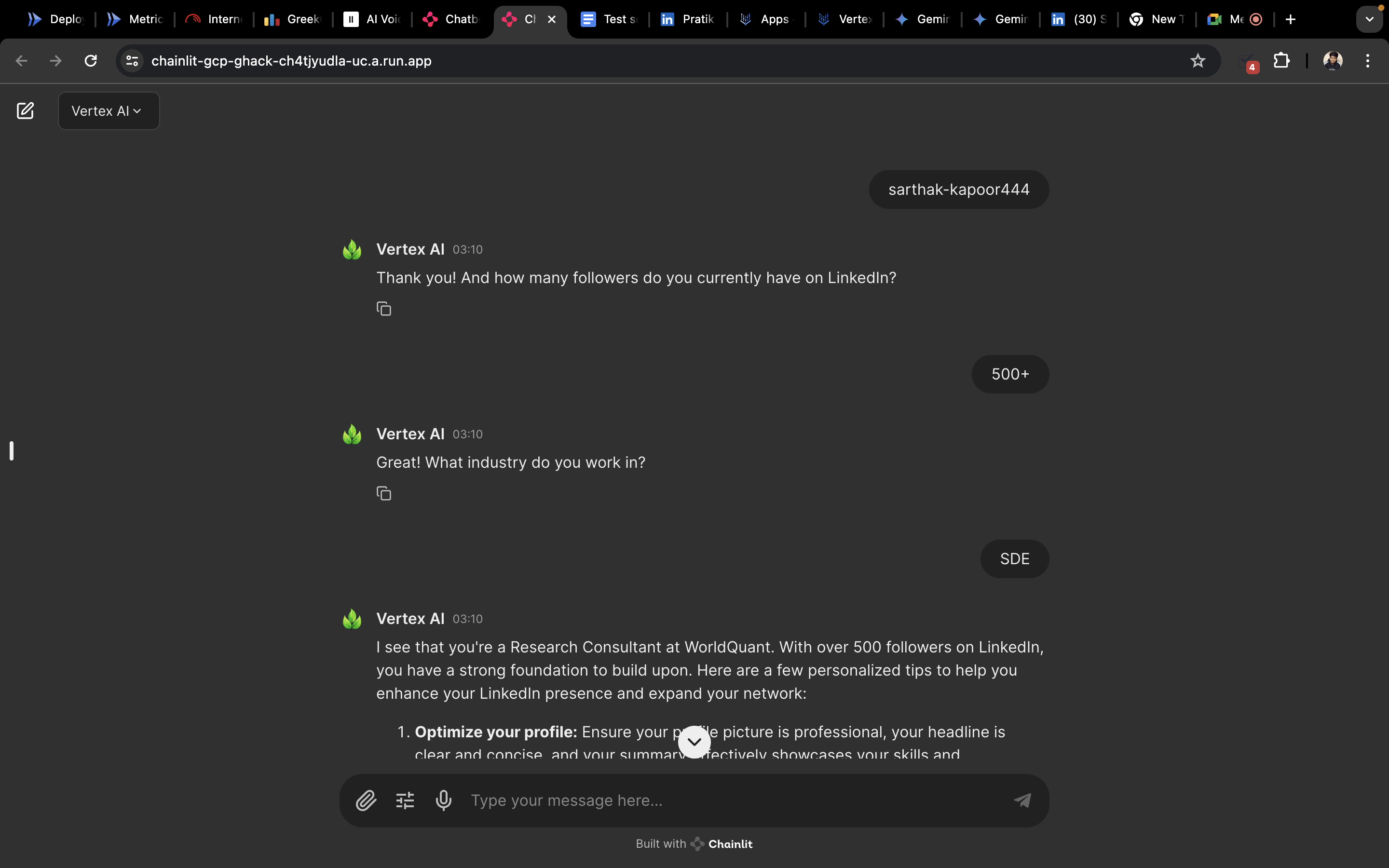
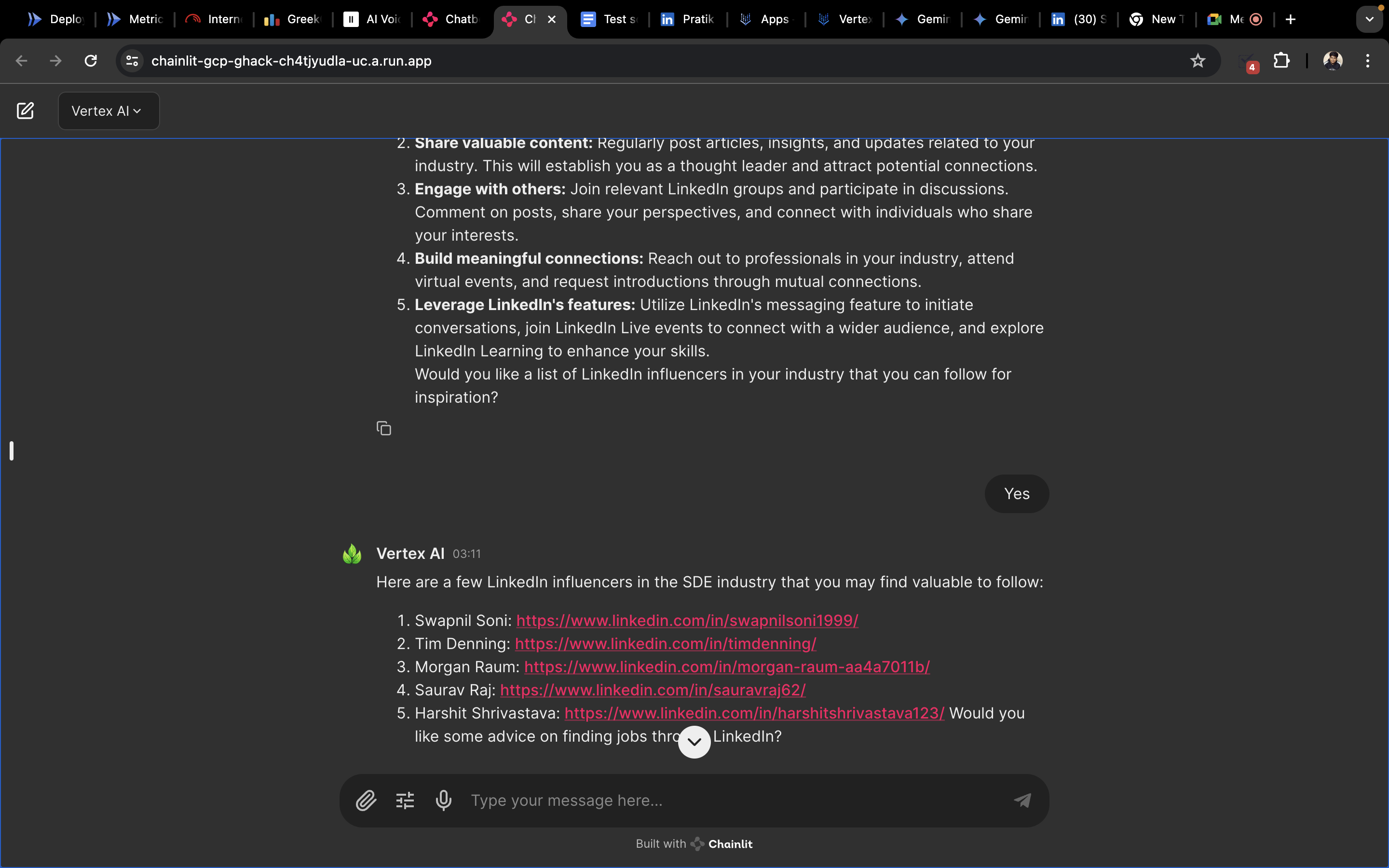
- Interview Room : This specialised segment which uses Vertex AI at its core is meant for people who want to give a mock interview, this asks the user for certain information such as name , codeforces ID, CV and the role the user wants to interview for. This serves as the point where Retrivel augmented generation through claude is used to sample a set of questions from a vector database and presents these questions as input to Vertex AI which goes on to take the interview. We store this conversation as an object of the class QuestioAnswerLogger
bash class QuestionAnswerLogger: def init(self): self.data = [] # This list will store all question-answer pairs
def add_question_answer(self, question, answer):
self.data.append(
{
'question': {question},
'answer': {answer}
}
)
def get_all_entries(self):
return self.data
and then at the end of the conversation the user is presented with a set of coding problems retrieved from the codeforces API , we then go on to check the solved status of these problems and add these to the objects to send these repsonses to claude which evaluates and provides a comprehensive review of the performance by the individual.
Example : Final Output:
Question 1: Explain the concept of inheritance in object-oriented programming. Discuss the different types of inheritance and their use cases. Your Answer: types of inheritance are single and multilevel Justification: Your answer is partially correct as you have identified two types of inheritance (single and multilevel), but it lacks depth and specific examples. The response does not explain the concept of inheritance itself or provide use cases for the different types mentioned. Scores: Relevance: 3, Clarity: 3, Depth of Knowledge: 2, Specific Examples: 1
Question 2: What is a database management system (DBMS)? Describe the key components of a DBMS and their roles. Your Answer: do not know Justification: Your response indicates a lack of knowledge about database management systems, which is an important concept for software development roles. Scores: Relevance: 1, Clarity: 5, Depth of Knowledge: 1, Specific Examples: 1
Overall Assessment: Based on your responses, it appears that you have significant gaps in your knowledge of fundamental computer science and software development concepts. Your answers consistently demonstrated a lack of understanding of important topics such as object-oriented programming, databases, computer architecture, design patterns, algorithms, and version control systems. While you were able to provide a partially correct answer for the time complexity of BFS and DFS, your overall performance in the interview was poor. You struggled to provide clear, relevant, and in-depth responses, and you did not offer specific examples to support your points. Your communication skills were adequate, but your lack of technical knowledge raises concerns about your suitability for the software development role you are interviewing for.
Overall Score: 2
The user recieves a overall rating on a scale of 5, through prompting we can utilise the CV of user and generate questions based on the CV and the questions retrieved from the vector data base. Finally the app is capable of accepting audio repsonses , through hugging face inference API and the app is also capable of accepting images and pdf files whereby the image files are redirected to Gemini Pro API and the pdf is parsed and sent to Vertex AI through dialogflow.
Codeforces API : Used the codeforces API to get the problem solved by the user currently then matched the complete data set of problems and found two problems relevant and unsolved by the user to be solved in the interview further taking the information from the meta data of the codeforces API and scraping the codeforces.com site using beautiful soup and display the problems and gave a link to submit the problems on the codeforces website after the problems were submitted , again used the API to see if the problems were correctly solved or not by the user thereby sending all this data to the evaluator bot to judge the user. RAG : First we used Huggingface sentence transformers to create text embeddings of ML and SDE questions which were asked to our seniors in actual interviews. Then we inserted these embeddings to different vector databases using Pinecone. Then using claude-3-haiku , we retrieved a list of high quality questions from the vector store.
Deployment : Created a requirements.txt all the information about the important libraries that needed to be installed .Created a docker file containing the list of instructions on how to generate the docker image generated the docker image ,tagged the docker image, pushed it in the google artefact registry container and then deployed it on Google Cloud Run.
Challenges we ran into
Few of the many challenges we faced during our journey were :
- The documentation for Vertex AI was challenging to follow, making it difficult to implement certain features effectively.
- Several components had outdated documentation, which led to confusion and hindered progress.
- Resolving dependency conflicts proved to be a significant challenge, often causing delays and requiring extensive troubleshooting.
- Our initial unfamiliarity with the Vertex AI console meant we had a steep learning curve to navigate before we could efficiently utilize its features.
- Integrating our bots with external platforms, especially CP/DSA platforms, presented technical difficulties and compatibility issues.
Accomplishments that we're proud of
There are 3 main outcomes that we are particularly proud of:
- Developing a user-friendly interface using Chainlit and other frameworks, supporting multiple communication modalities. We are especially proud of the ability to talk to the model during the interview just like in real-life interviews
- Our interviewer agent simulates real interviews by analyzing user information and tailoring questions accordingly. The questions are based on those asked in actual interviews experienced by our seniors, ensuring relevance.
- We actually managed to use the Codeforces API to simulate how a real coding round would go in the interview process combined with its ability to actually verify if you solved it or not.
What we learned
This project turned out to teach us a lot more than we expected. Few of our many learnings during the course of our journey were :
- We Gained comprehensive knowledge of Vertex AI, including its console, services, and how to effectively navigate and utilize its features.
- Developed skills in resolving dependency conflicts and managing dependencies effectively to ensure stable and consistent project builds.
- Acquired expertise in integrating various external platforms and services using APIs to enhance the functionality of our bots.
- Gained experience in prompt engineering and several other retrieval methods to tailor the responses of the LLMs as per our need.
What's next for SkillForge
We have few of the following ideas next in line for SkillForge:
- We aim to significantly broaden our data corpus of interview questions, providing users with a more comprehensive and challenging interview preparation experience.
- We plan to add support for a variety of additional roles that candidates might apply for, ensuring that our agents cater to diverse career paths and job markets.
- We aim to incorporate support for multiple CP/DSA platforms beyond Codeforces, enhancing users' ability to practice and improve their coding skills across different platforms.
Built With
- anthropicapi
- chainlit
- codeforcesapi
- huggingfaceapi
- pineconeapi
- python








Log in or sign up for Devpost to join the conversation.