-
-
Translation
-
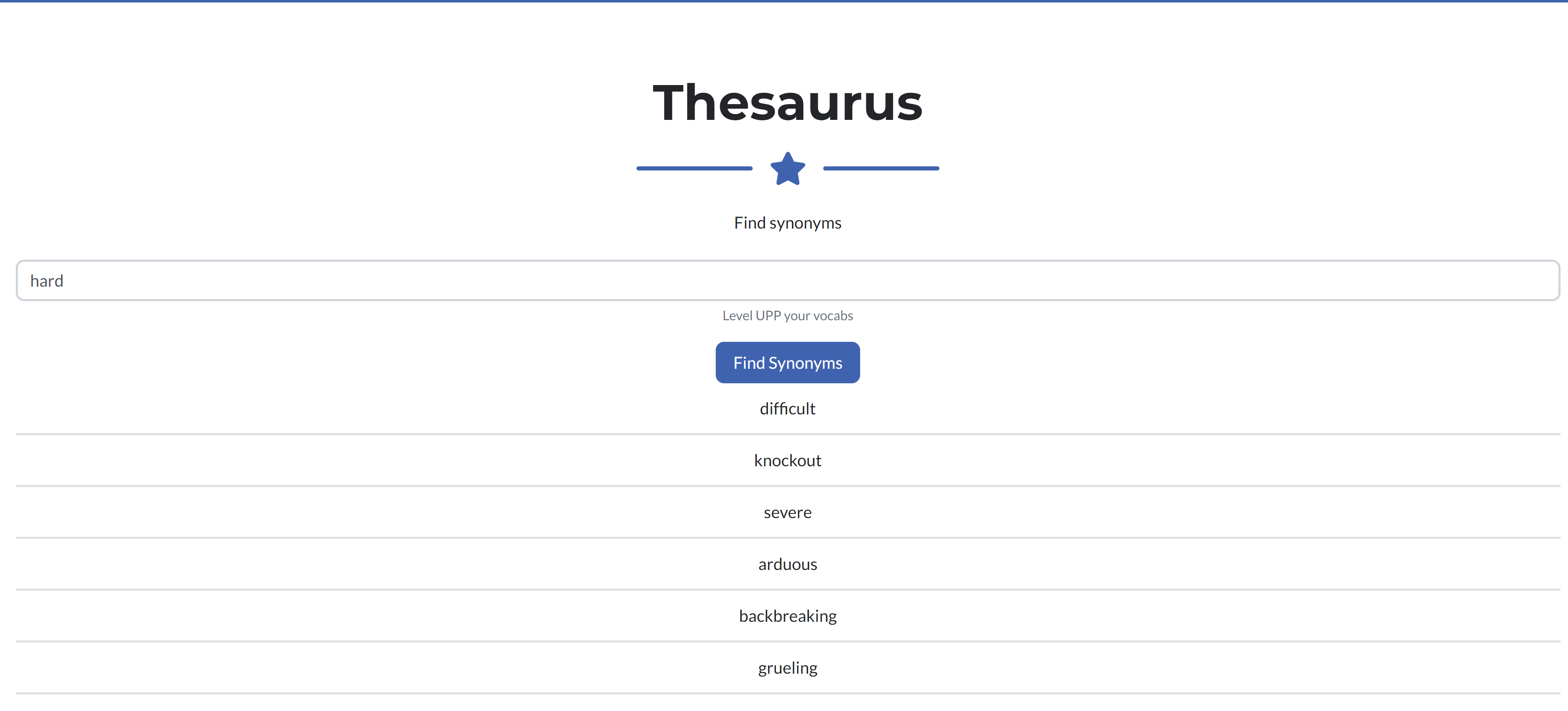
Thesaurus
-
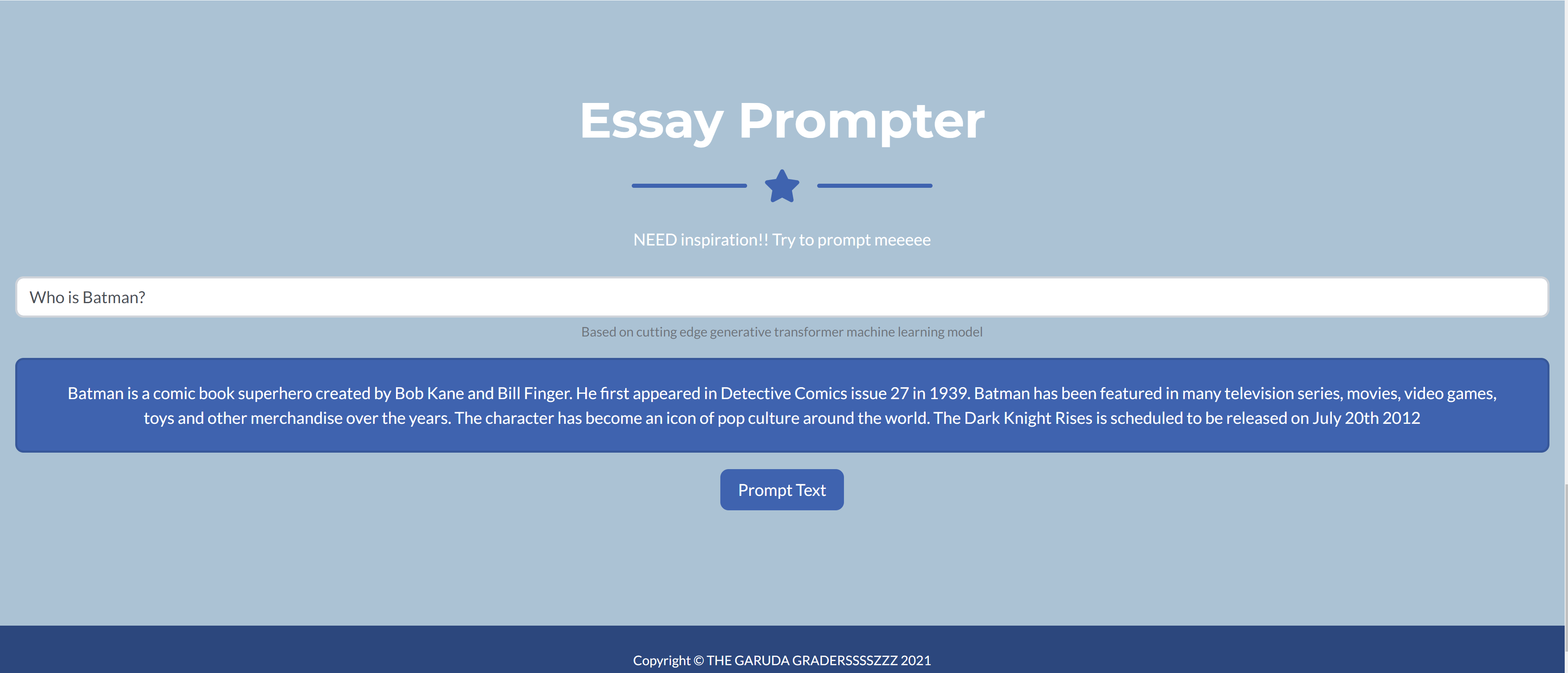
Essay Prompter
-
About Page
-
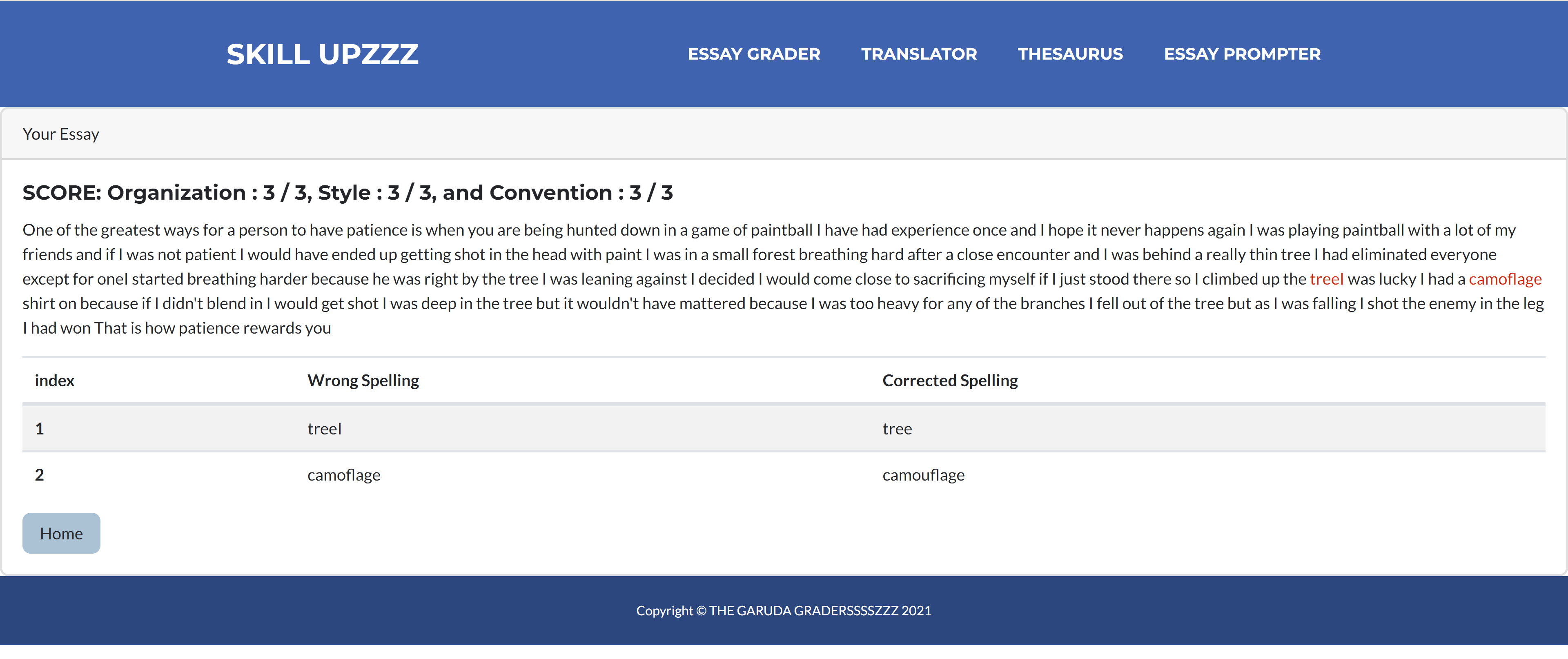
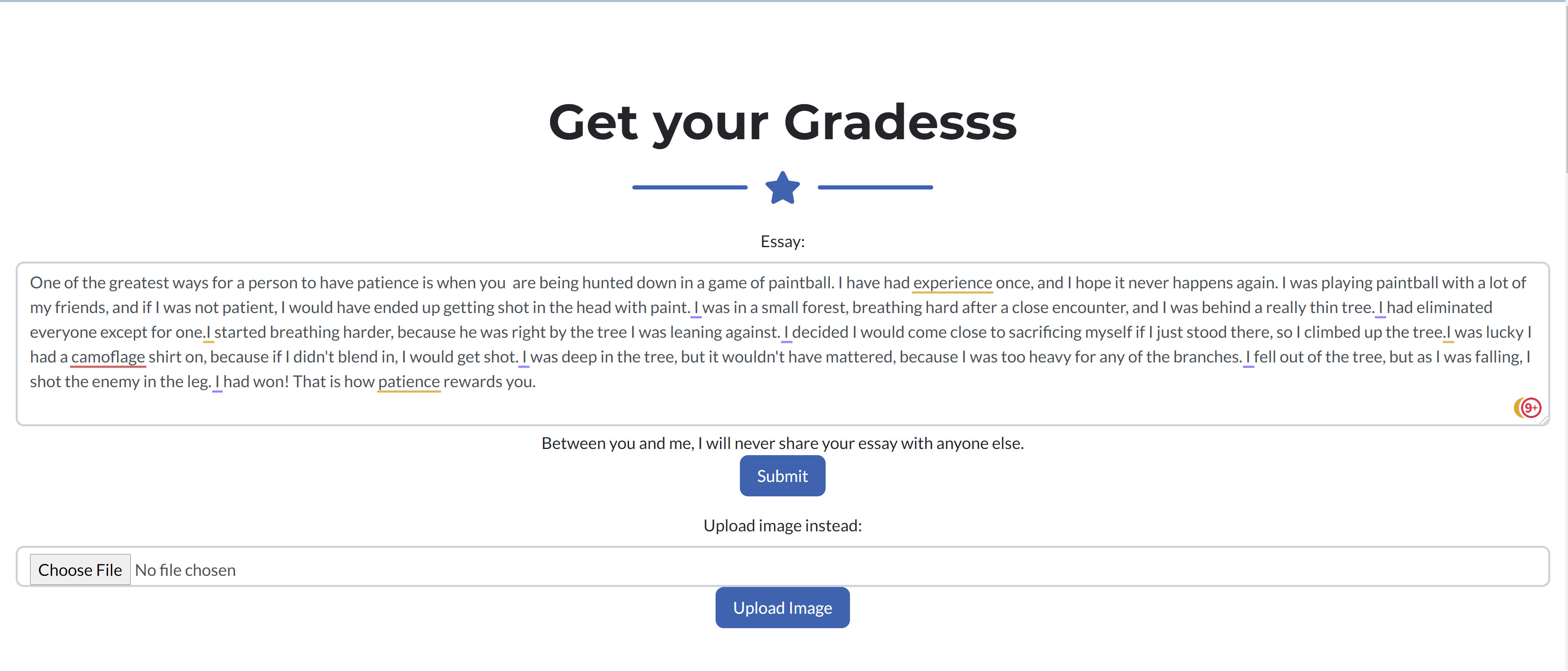
Essay Grader Result
-
Essay Grader
-

Phone UI About sect
-
django running Linode Server
-
django running Linode Server LISH console



Inspiration
English is regarded as a universal language. Not only is English the official language in 70 countries, but it is, at the very least, understood amongst scholars, as well as those in government, media and academia. In fact, studies have shown that English is spoken, at a comprehensible level, by one person in every four. This means that it is spoken by roughly 1.75 billion people worldwide! In addition, English-speaking countries make up a staggering 40% of the world’s total GNP.
It is clear that a good command of the English language is necessary to further your influential reach, enter prestigious universities or educational bodies, build connections, and help realise economic prosperity. In particular, it is vital to develop the skill of English writing due to the prevalence of the internet and online social media. This has never been more true after the wake of the COVID-19 pandemic, which has led to the increase in popularity of remote work and online networking. However, it may be a struggle for native Indonesian speakers to adapt to this remote-oriented lifestyle, and properly integrate with the rest of the world.
What it does
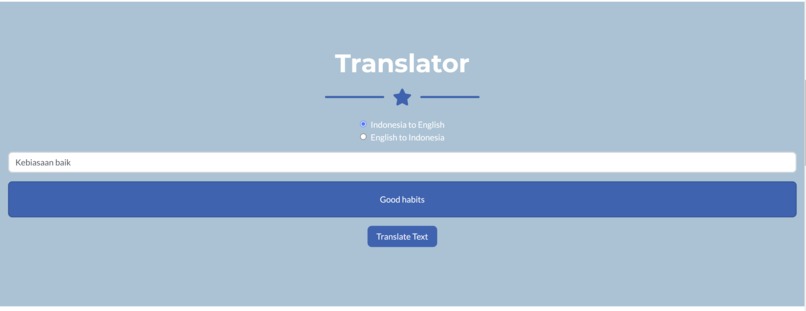
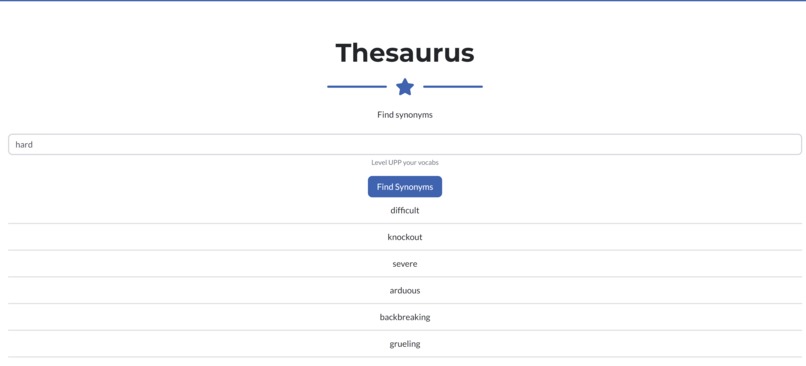
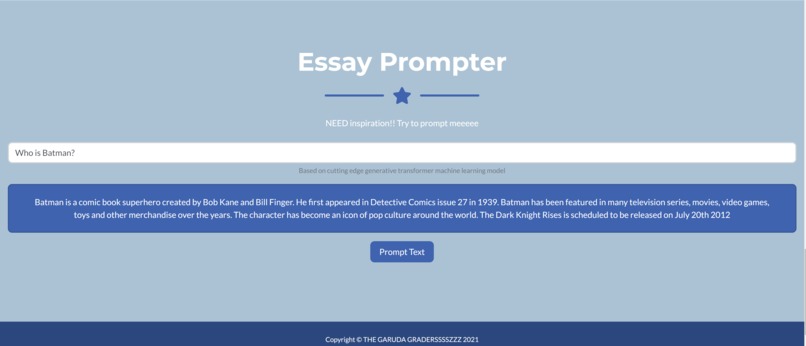
SkillUpzzz is an AI-powered writing assistant that offers a variety of services to help overcome any difficulties faced when writing in English. These services include a translator between Indonesian and English, a thesaurus, a prompter, and constructive feedback on uploaded text.
The word prompter works by inputting a few words into a search bar. The output will be a suggested paragraph that incorporates the inputted words, to help kickstart the writing process. We understand that getting into the flow of writing can be the hardest step. This prompter uses a state-of-the-art generative model known as GPT3.
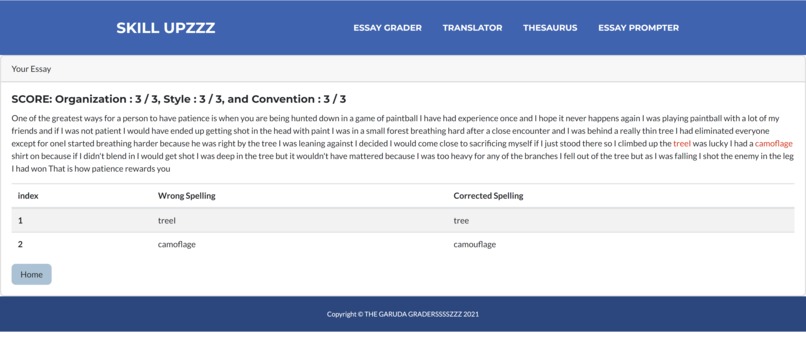
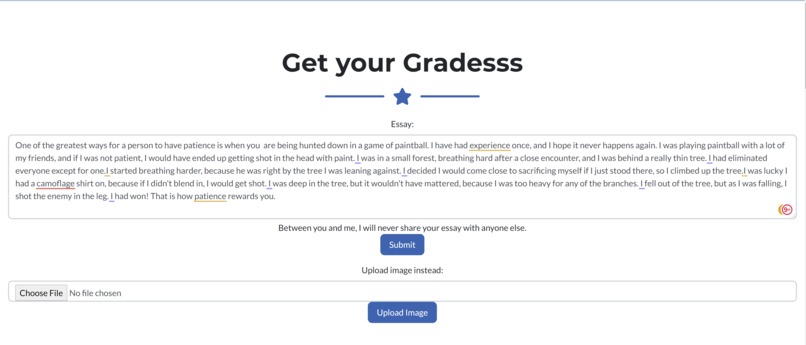
To get constructive feedback on English-written text, you can either input the text directly in the website, or upload an image of the written text. After doing so, a powerful AI language-model, with a rich contextual understanding, will parse through the text and critique it. It will critique it based on three criteria; Organization, Style, and Convention. These three categories are described blow;
- Organization refers to how well ideas are sequenced in the text
- Style refers to the words used in the text, i.e. the language model assesses whether the vocabulary used is appropriate, rich, varied etc.
- Convention refers to grammar, spelling, capitalization and punctuation.
The language-model should be finishing its assessment within a few seconds, and it will output a score for each of the three categories listed above. All scores are out of three. In addition, the model will also output a list of specific spelling errors it detected in the text, as well as suggested corrections.
How we built it
- The text grader is implemented using Bidirectional Encoder Representation from Transformers (BERT) to output contextual word embeddings, which are then fed into a Multi-Layer Perceptron (MLP) to output the grades. The whole model is trained on the Automatic Essay Scoring (AES) dataset of the Kaggle competition by Hewlett-Packard (HP).
- The spellchecker is implemented using pyspellchecker library (https://pyspellchecker.readthedocs.io/en/latest/), which uses Levenshtein Distance to determine not only the misspelled words, but also the most likely correction.
- The image-to-text feature uses Optical Character Recognition (OCR) from Google Vision API.
- The translation feature is implemented using Google Translate API.
- The essay has a thesaurus using NLTK WordNet, which outputs the synonyms of the inputted word
- The essay prompter is implemented using GPT3, which is a word-level generative model. This therefore allows the generation of a full paragraph of text from a prompt that consists of only a few words.
- UI is developed using web based tools (HTML, CSS, and JavaScript) that is managed by Django Web Frameworks (based on Python) for the backend.
Challenges we ran into
- Training BERT requires intensive usage of GPU and takes a significant amount of time. Furthermore, the dataset is relatively small for a model as massive as BERT and the essays in the dataset have little variety in terms of topic.
- The setups required to get the API keys and configuring the environment variables to use them in the code is relatively complicated for first-timers.
- Django has lots of features, hence finding the required feature is relatively challenging within a short period of time.
Accomplishments that we're proud of
Working together effectively as a team to develop an end-to-end solution (integrating UI, AI models, and APIs) to develop a service with the aim of helping fellow Indonesians within 24 hours.
What we learned
We learned how to collaborate with one another effectively and efficiently online, despite some of us being in different time-zones (7 hours apart).
What's next for SKILL UPZZZ
We would like to develop this application further by introducing new features which we did not have time to implement in the given time. For example, we would like the language model to not only output a score for each of the three categories, but also output a brief description of what the user can do to improve each of these scores. For example, if the input text consists of repeated words, the model can suggest that the user vary their vocabulary, and can refer the user to the thesaurus. If the flow of information is not appropriate, the model can propose how best to shuffle around some portions of the text, and so on. Another extension feature would be to implement the word suggestions above, as well as spell-checking as a ‘live’ feature, that is active whilst the user is typing.
Furthermore, we would also like to train the language model (BERT) on graded text samples with more variety of topics and categories. Currently, the model is only trained on texts written by primary school students. We believe there is an abundance of appropriate training data for more ‘advanced’ texts such as research papers from universities or other educational institutions. Perhaps we can reach out and collaborate with some universities to receive anonymised data to improve the performance of the language model.



Log in or sign up for Devpost to join the conversation.