-
-
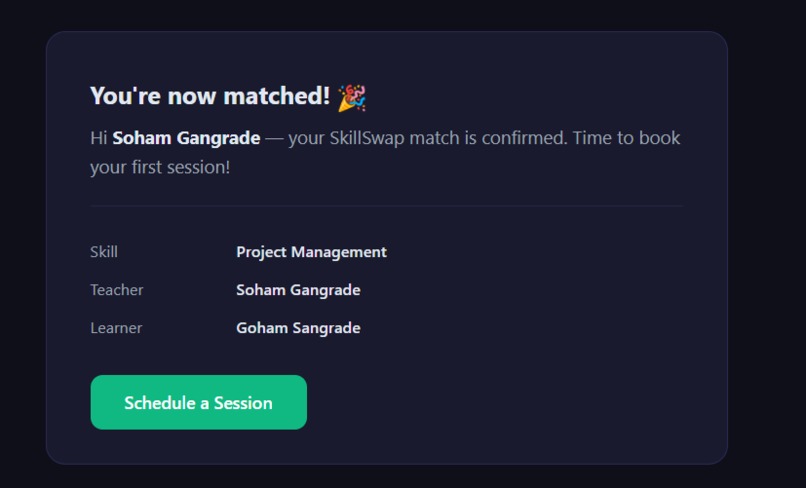
Matching successful
-
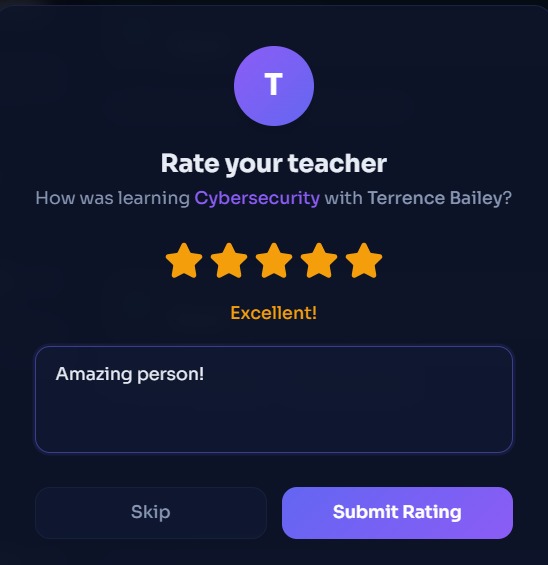
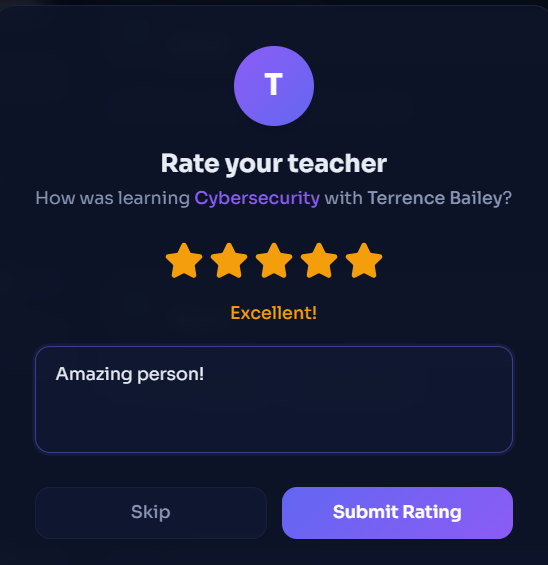
Rating after lessons are over
-
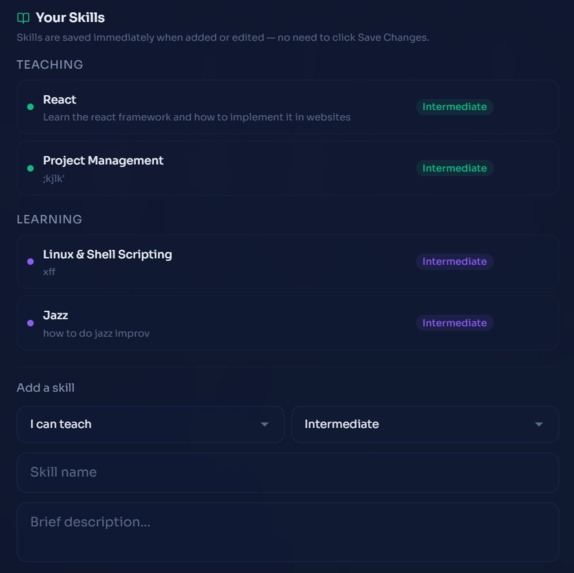
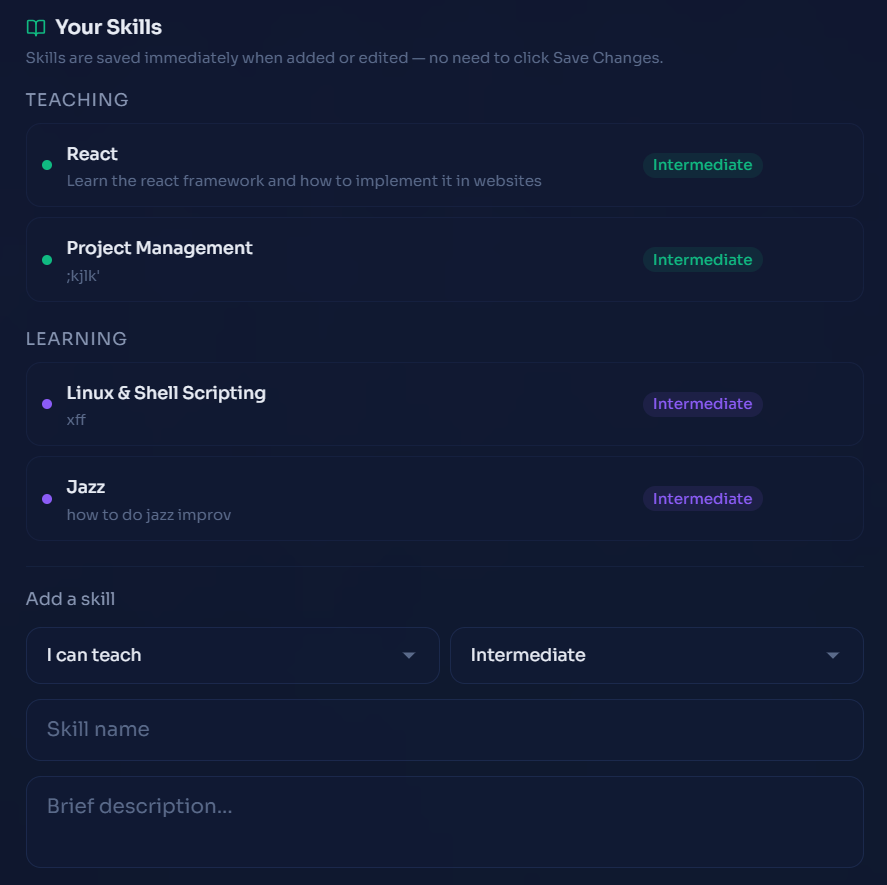
Create skills
-

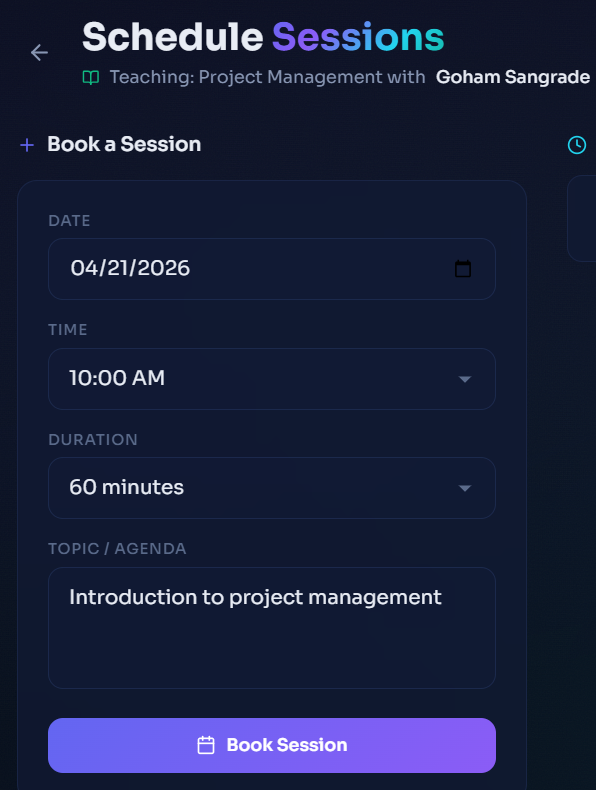
Schedule builder
-
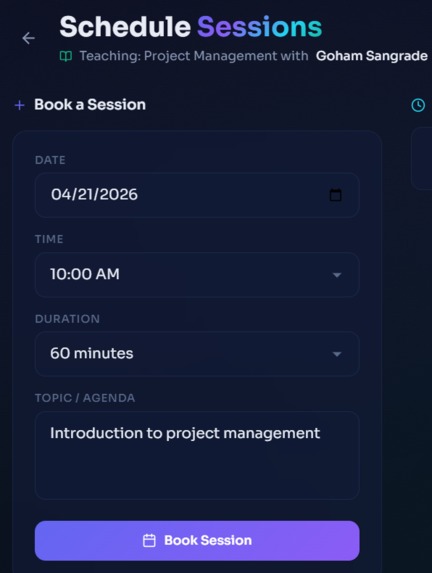
Schedule a session for teaching
-
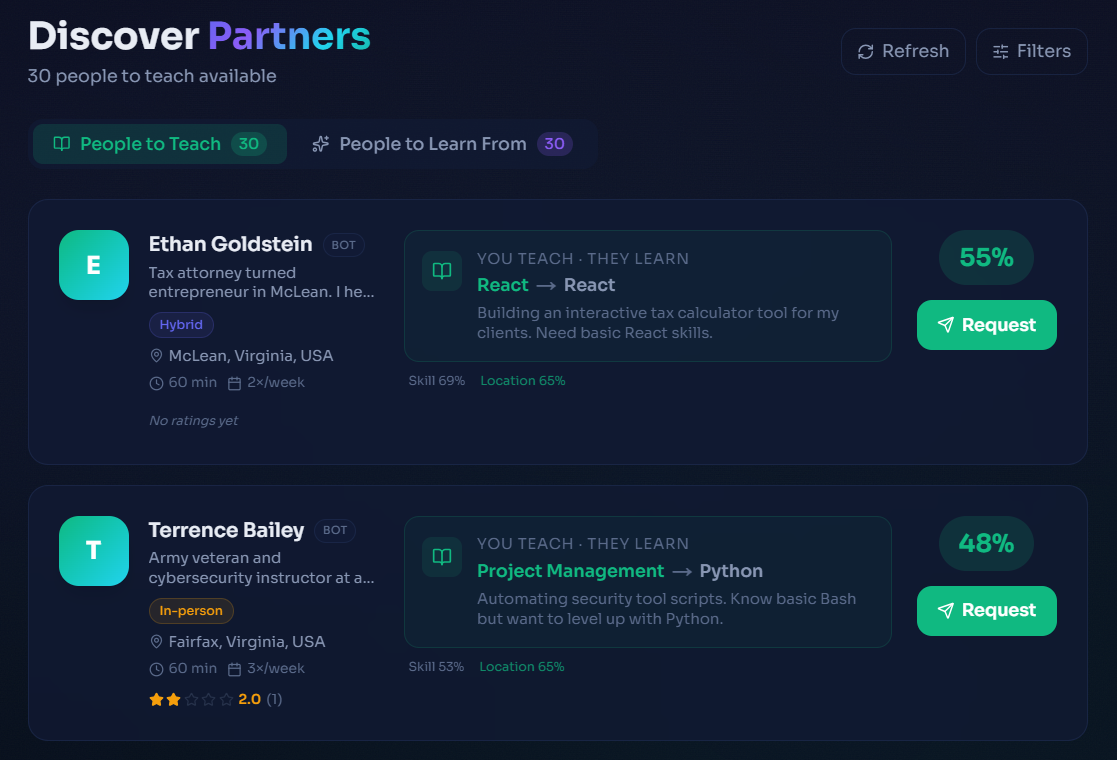
AI matching
-
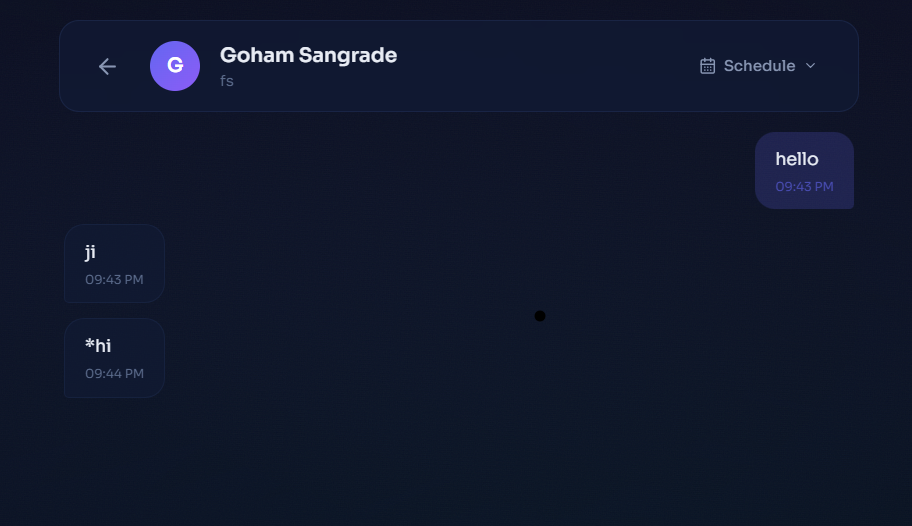
Message between teacher and learner
-
Initial page

SkillSwap: Building a Peer-to-Peer Skill Exchange Platform
Inspiration
Inspiration
It all came out of a personal experience when I wanted to learn how to edit videos while my buddy wanted to learn Python coding. We always said "I'll teach you if you teach me," but we never did anything about it because there was no platform for us to do that. Sites such as Udemy and Coursera are unidirectional, and tutoring websites are monetized. However, not many people are after the money; they just want a return favor.
And that is what SkillSwap is all about: learning from each other without any transaction.
What I Built
SkillSwap is a full-stack Next.js web app where users:
- List skills they can teach and skills they want to learn
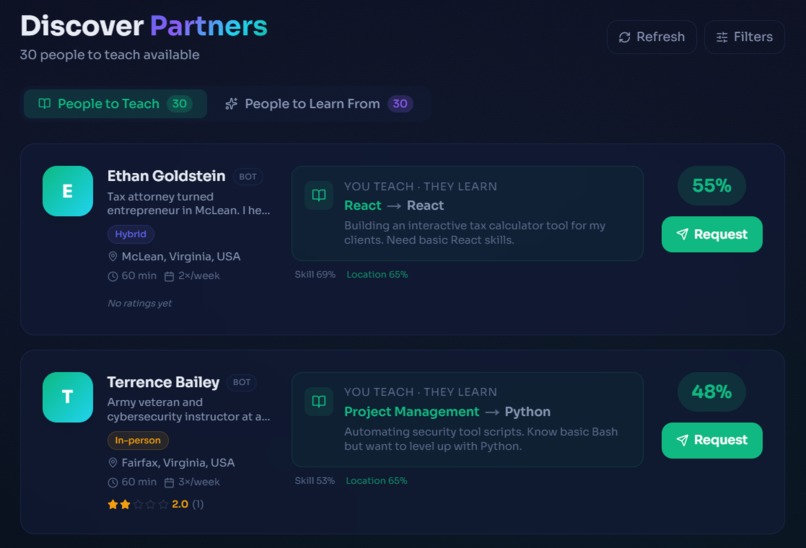
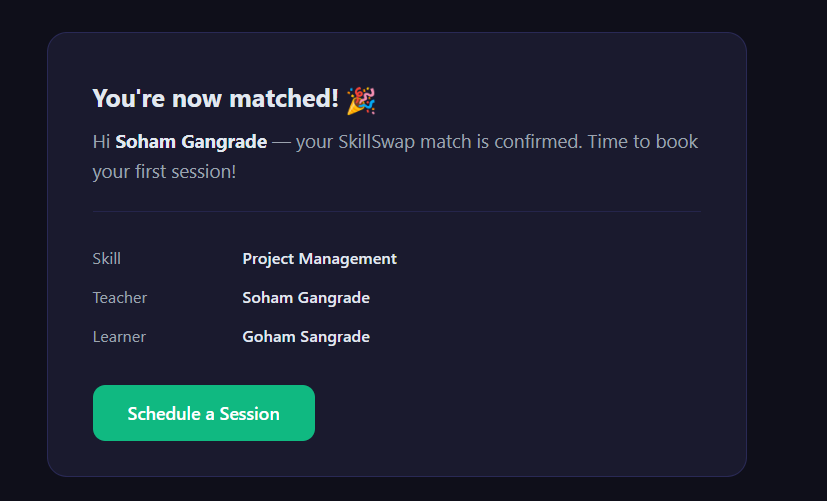
- Get matched with compatible partners using semantic vector search + a multi-factor scoring algorithm
- Negotiate matches, schedule sessions, and message each other
- Rate teachers after sessions or unmatching
- Discover people nearby or virtually, filtered by session type, bot status, and more
The platform is populated with ~95 realistic bot users that make the discover and matching features feel alive during the demo.
The Matching Algorithm
The core of SkillSwap is the matching engine. Given two users A (potential teacher) and B (potential learner), I compute a compatibility score bewteen 0 and 1:
$$s = w_{\text{skill}} \cdot \text{skill} + w_{\text{loc}} \cdot \text{loc} + w_{\text{avail}} \cdot \text{avail} + w_{\text{rating}} \cdot \text{rating} + w_{\text{session}} \cdot \text{session} + w_{\text{freq}} \cdot \text{freq}$$
Skill Similarity
Skills are embedded using the gemini-embedding-001 embedding from Google (3072-dimensional vector), which is saved in PostgreSQL tables via pgvector columns. Cosine similarity calculates how much knowledge A shares with what B needs:
$$\text{skill}(A, B) = \frac{\vec{e}_A \cdot \vec{e}_B}{|\vec{e}_A| |\vec{e}_B|}$$
It reflects semantic similarity of "machine learning" and "neural networks" have a high similarity despite no matching words.
Location Score
For in-person matches, I use the Haversine formula to penalize distance:
$$d = 2r \arcsin!\left(\sqrt{\sin^2!\left(\frac{\Delta\phi}{2}\right) + \cos\phi_1 \cos\phi_2 \sin^2!\left(\frac{\Delta\lambda}{2}\right)}\right)$$
$$\text{loc}(d) = e^{-d / 50}$$
Because of the exponential decay, a match within about 25 km is worth almost 1, whereas a match 200 km away is less than 0.02. Virtual people disregard this entirely (location weight = 3%).
Availability Overlap
$$\text{avail}(A, B) = \frac{|S_A \cap S_B|}{|S_A \cup S_B|}$$
A Jaccard overlap of 30-minute time slots across the week. Perfect overlap = 1.0; no common time = 0.
Rating Score (Bayesian Blend)
Raw averages are noisy for users with few ratings. I use a Bayesian prior blending approach:
$$\hat{r} = \frac{n}{n + k} \cdot \bar{r} + \frac{k}{n + k} \cdot \mu_0$$
where $$\bar{r}$$ is the user's sample mean rating (1–5 stars), $$\mu_0 = 3.25$$ is the prior mean (mapped to $$0.65$$ in $$[0,1]$$), $$n$$ is the number of ratings, and $$k = 5$$ is the confidence saturation point. This means:
- A new user with 0 ratings gets the neutral prior: $\hat{r} = 0.65$
- A user with 5 ratings is halfway between their average and the prior
- A user with 20+ ratings is almost entirely their own signal
Crucially, rating only factors into the score when you are the learner — if you're teaching someone, their rating as a teacher is irrelevant since you're the one doing the teaching.
Weights
| Factor | Virtual | In-person/Hybrid |
|---|---|---|
| Skill | 60% | 47% |
| Location | 3% | 28% |
| Availability | 22% | 11% |
| Rating | 10% | 7% |
| Session length | 4% | 4% |
| Frequency | 1% | 3% |
How I Built It
Stack
- Next.js 16 (App Router) — server components + API routes
- Supabase — Postgres + pgvector + auth + realtime subscriptions
- Google Gemini —
gemini-embedding-001for skill embeddings,gemini-2.0-flashfor AI-generated match explanations - Resend — transactional email (match requested, accepted, session scheduled)
- Tailwind CSS v4 — utility-first styling with custom CSS variable color tokens
The Balance Constraint
Reciprocity is enforced via a hard rule that you cannot ask to learn anything unless the number of times you taught was equal or higher than the number of times you learned:
$$\text{canLearn} \iff \text{teachingCount} \geq \text{learningCount}$$
Thus, there is no way to take advantage of others. In case you are restricted from learning, you will see an amber-colored banner immediately with the explanation of why this will be updated dynamically for every teach request without refreshing the page.
Timezone-Aware Scheduling
Your availability is stored in the following format: "DayName:HH:MM", along with the timezone in IANA format (for example, America/New_York). When viewing a partner's availability in chat, their times will be converted to your timezone using JavaScript alone:
const naive = new Date(`${refDate}T${hh}:${mm}:00Z`);
const fromStr = naive.toLocaleString("sv", { timeZone: fromTz });
const offsetMs = naive.getTime() - new Date(fromStr + "Z").getTime();
const utcInstant = new Date(naive.getTime() + offsetMs);
// then format utcInstant in toTz
The sv locale trick produces ISO-like strings ("2025-01-06 09:00:00") that are trivial to parse — no moment.js required.
Challenges
1. Embedding Rate Limits at Scale
Embedding skill descriptions with 95 bots involved embedding about 380 skill descriptions at 200 ms. The free plan in Gemini supports up to 100 embeddings per minute. I got stuck when trying bot 24. The trick was to create a secondary reembed-all.mjs that uses WHERE embedding IS NULL and fills only the missing ones – basically a recoverable pipeline.
2. Synthetic Ratings Without Real Match Pairs
I wanted the bots to have realistic rating distributions – but the rating entry requires an existing match_id. The realization came that the foreign key column match_id is actually nullable in the database schema and NULL does not equal NULL in a UNIQUE constraint – so several past ratings can be associated with match_id = NULL.
3. Balance Lock Not Updating Live
The "Locked out of Learning" warning would appear only after a page reload. The problem was that the canLearn variable was updated within the load() function. So I created a lightweight refreshBalance(uid) which updated the balance without requiring a reload after a successful teaching attempt.
4. Bayesian Ratings in a Direction-Aware System
The initial formulation of the score worked in either direction. However, when you are teaching someone, your rating as a teacher is irrelevant, you are the teacher. To address this, I modified computeScore() to be direction-specific, using $0.65$ as the rating factor while computing the teaching-direction scores and relying on the actual Bayesian estimate for learning-direction matches.
What I Learned
- Semantic search trumps keyword search for skills-based matchmaking. If two individuals are passionate about "deep learning" and "neural networks," they need to match — cosine similarity captures this requirement effortlessly.
- Prior probability influences ratings in social contexts. A product with a 5-star rating based on a single review cannot compare to one with a 4.7 rating from twenty users. Treating these averages identically yields unreliable, exploitable rankings.
- Fake users create legitimate products. Without active members, the social networking platform lacks utility. Adding 95 plausible virtual users, complete with diverse skill sets, geographical locations, rating levels, and automatic matching rationales, gives the platform purpose.
- Time zone support without a dedicated library proves more feasible than expected with Intl. Utilizing the sv locale hack, I solved any wall-clock time-related problem using the native API.
Built at Bitcamp 2026.
Built With
- github
- google-cloud
- resend
- sql
- supabase
- typescript
- vercel


Log in or sign up for Devpost to join the conversation.