-

Figure 1-2 - https://plot.ly/~liamacrawford/22/nfl-player-relationship-organization-250000/
-
Figure 2-2-2 - side visualization of 2-2
-
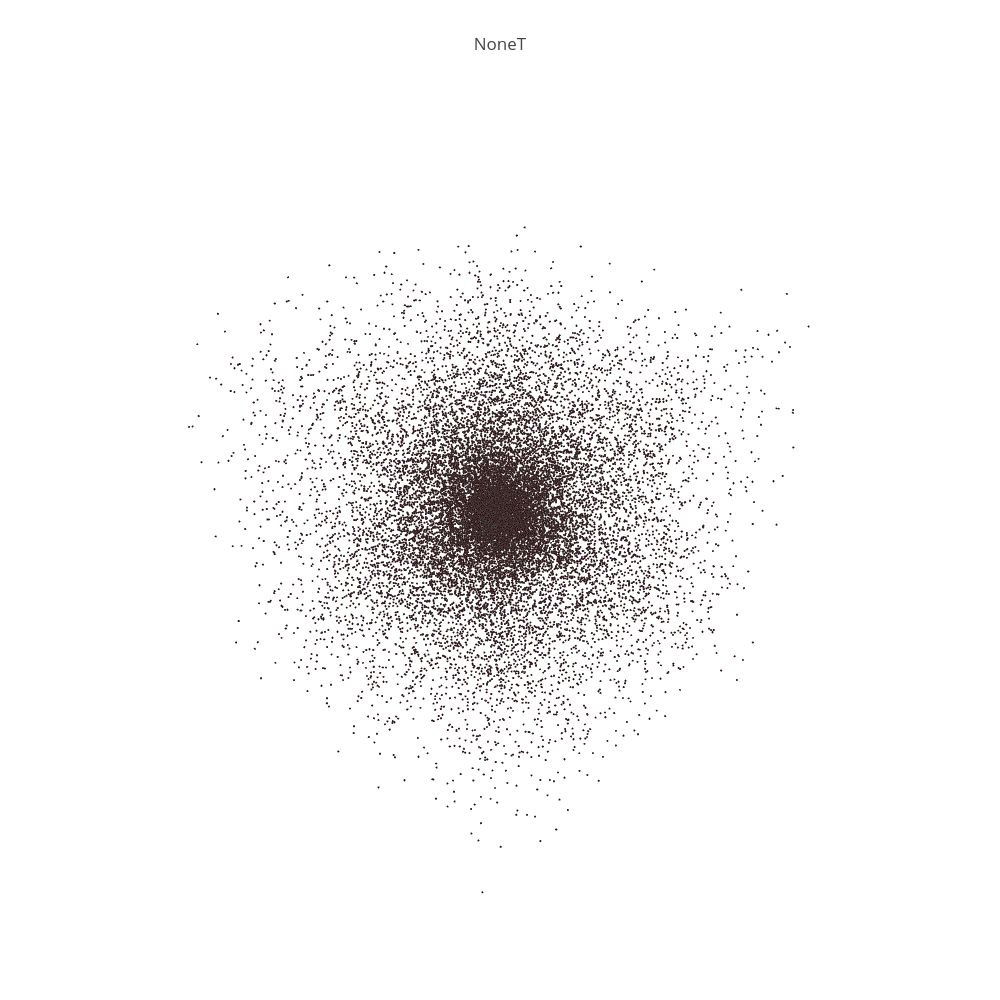
Figure 1-1 - https://plot.ly/~liamacrawford/0/nonet/
-
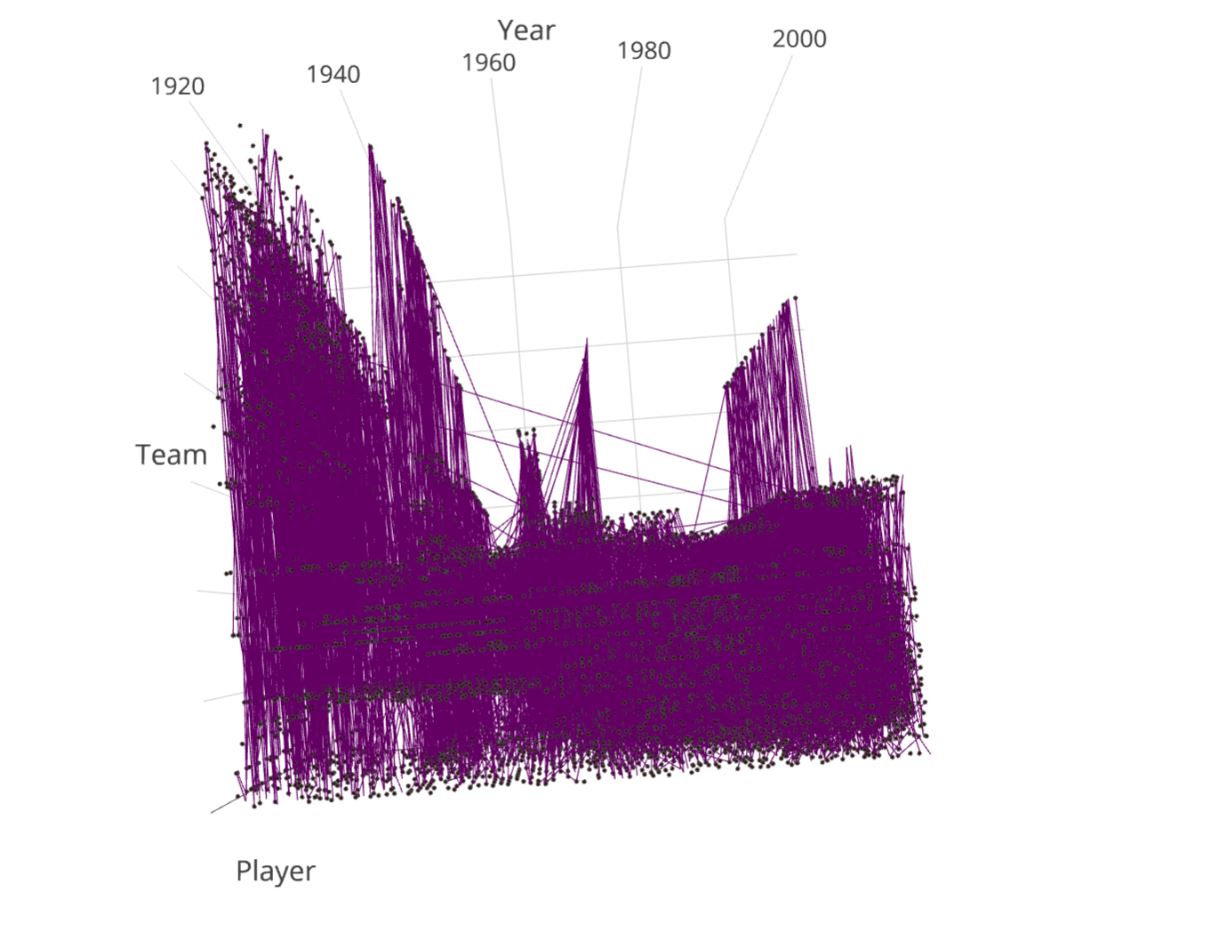
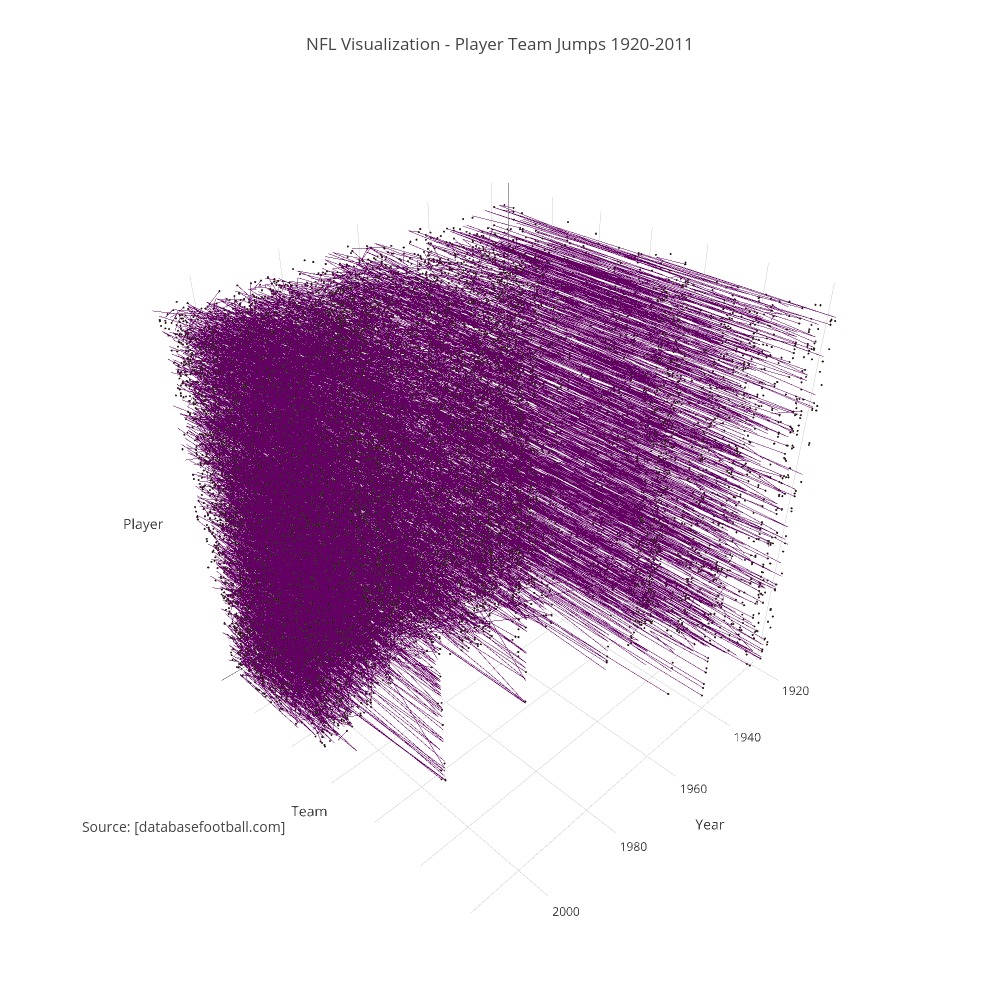
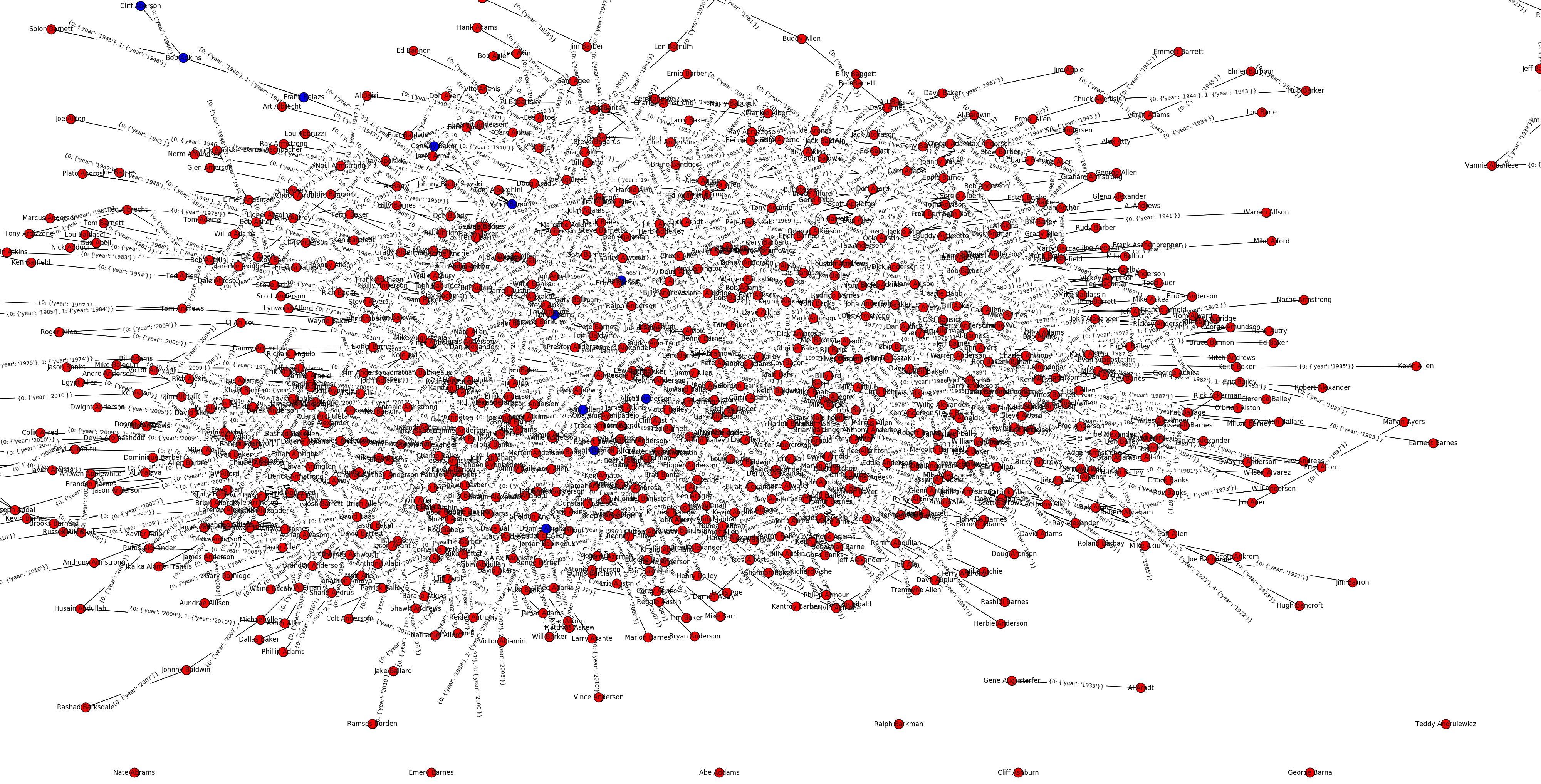
Figure 2-2 - https://plot.ly/~liamacrawford/24/nfl-visualization-player-team-jumps-1920-2011/
-
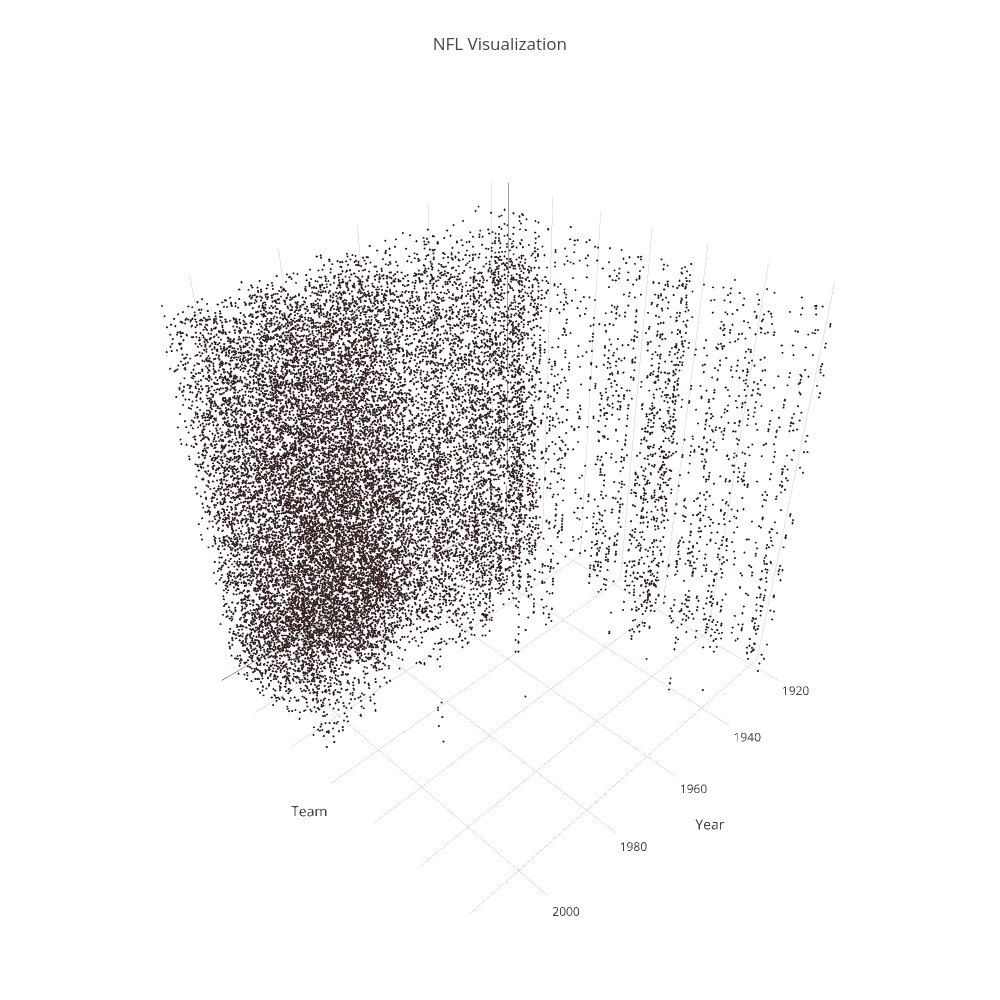
Figure 2-1 - https://plot.ly/~liamacrawford/16/nfl-visualization/
-

Figure 3-1 - generated my networkx.py
-

Figure 3-2 - generated my_networkx.py


Inspiration
The inspiration behind this project was the phenomenon of "Six Degrees of Kevin Bacon," whereby it is thought all actors are less than seven co-stars of co-stars away from Kevin Bacon at any time. We wanted to see how this idea applies to NFL players. We wondered if we could map a large set of NFL players as they related to one another, defining a relationship as having been on the same team as another player in the same year.
What it does
The conclusion of the project is a mixture of Python scripts that were either tools in the process of scraping/ aggregating data (named Builders, Scrapers, Aggregators) or that generated visualizations of the data (generators). The folder also contains the large datasets (allPlayers.txt, teamRosters.txt, etc.) that were then used to generate graphs.
Our shortest path file works, but essentially fails on paths with n > 2000. (filename-networkx.py)
How we built it
Steps
0) Determine the datasets we would need to scrape, and the format we wanted to store it in 1) Develop the webscrapper itself, based on the above parameters 1.1) Wait for the data 2) Read the documentation on visualization tools; determine the input format for the data 3) Parse the text files in useful ways, creating list of names, rosters by year, etc. as needed; store these in other text files 4) load the data into the tools 4.1) determine why tools were failing (too large of N, wrong parameter format, etc.) 5) jump to step 3 while time remains 6) document and complete
All the while learning to collaborate and debug with other.
steps 1 and 1.1 by far were the most time consuming
Challenges we ran into
One of the major challenges we ran into was collecting the data itself, as the dataset was not readily. We spent hours figuring out how to correctly parse the XPath of databasefootball until finally the data started rolling in. Yet still, the collection of data took well over 2 hours. To remedy this, we used the site's alphabetical listing of player names to separate players into different files based on the first letter of their. This allowed us to build tools for the entire dataset based on the format of the smaller subset.
Another major challenge came when we tried to visualize the data. We had so many graph nodes and edges between them that either 0) the graph became essentially unreadable or 1) the computer/plot.ly failed to generate an image. By changing up our strategy, we were able to create some cool visualizations that were a bit more ordered than before.
Accomplishments that we're proud of
We are most proud of the datasets we were able to compile, containing over 100,000 data points about over 22,000 players, that then can be extrapolated into millions of connections. Once the data was off the website, it was easy to manipulate.
We're also very proud of our reworked approach of visualizing the data. The algorithm provided by pyPlot and similar tools would work well considering the number of points we wanted to plot. We had to develop our own algorithms space out the data points.
What we learned
One of the biggest("hehe") problems with big data is the time it takes to access and process everything. Our tools can do the work well and make things look pretty, but not in a reasonable amount of time. The trick seems to be removing irrelevant data and avoiding needlessly redoing a task as much as possible. Also, it's helpful to know what data is going to be needed going in, especially if the process of collecting that data is time consuming.
Skills we learned: webScraping, XPathParsing, data visualization, more about the lovely language of Python
What's next for Six Degrees of NFL Players
The next thing would be to do re-scrape the data source for more information, or possibly pull from a different, more comprehensive website. If we wanted to pursue the shortest path problem, it might be useful to revisualize this as a path between teams, where a class team contains a name, a list of all-time players, and dictionary full of connected teams, where keys are the neighboring teams and the values are years that players went to or away from it. The processing time might be longer initially, but it would be easier to traverse between 122 team nodes than it would 22,138 players.
Built With
- beautiful-soup
- networkx-library
- py.plot-api-and-library
- python

Log in or sign up for Devpost to join the conversation.