-
-
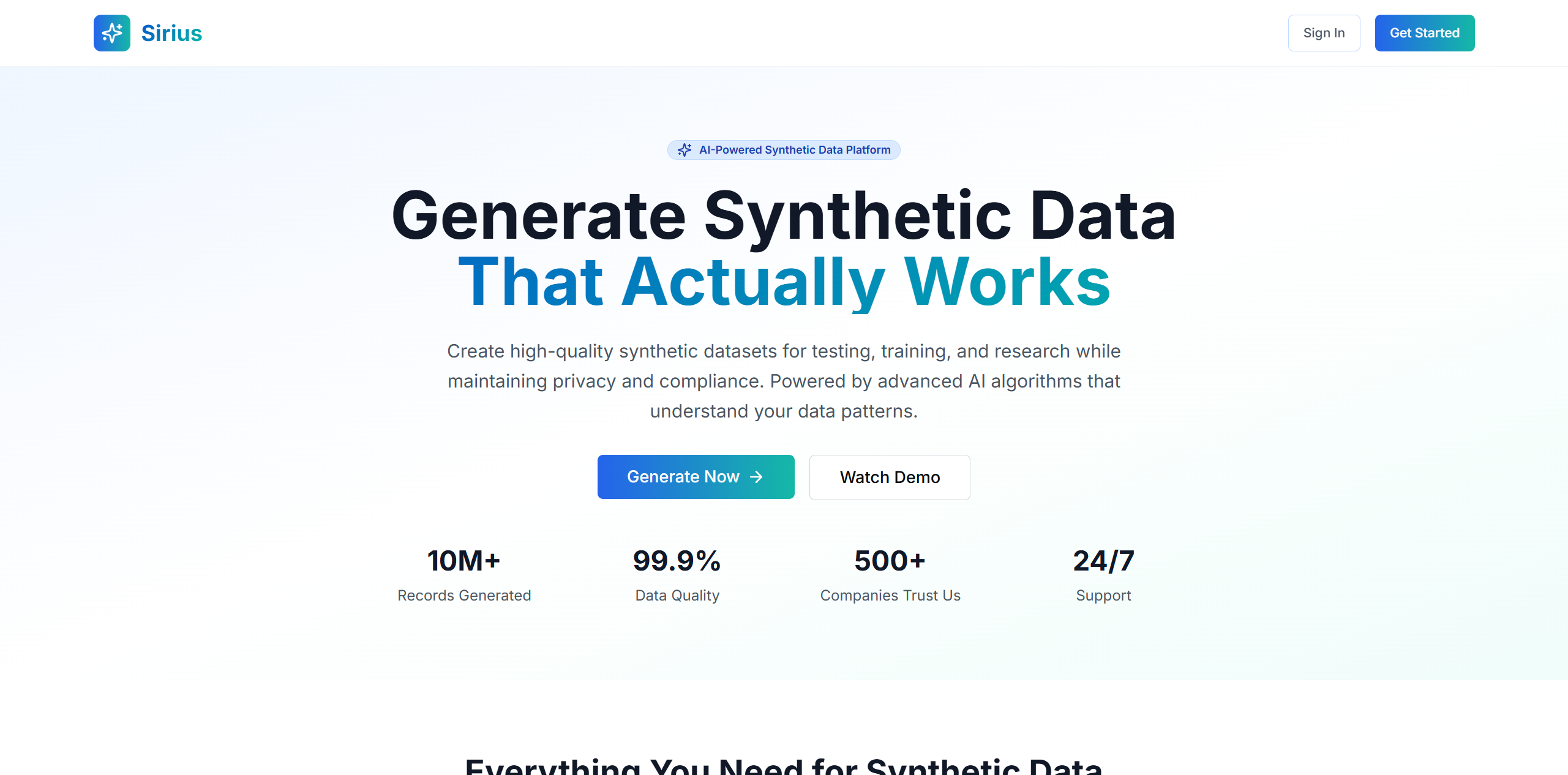
Landing page
-
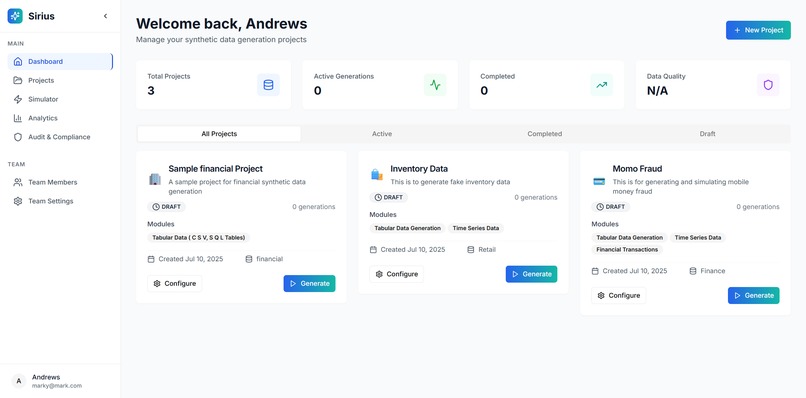
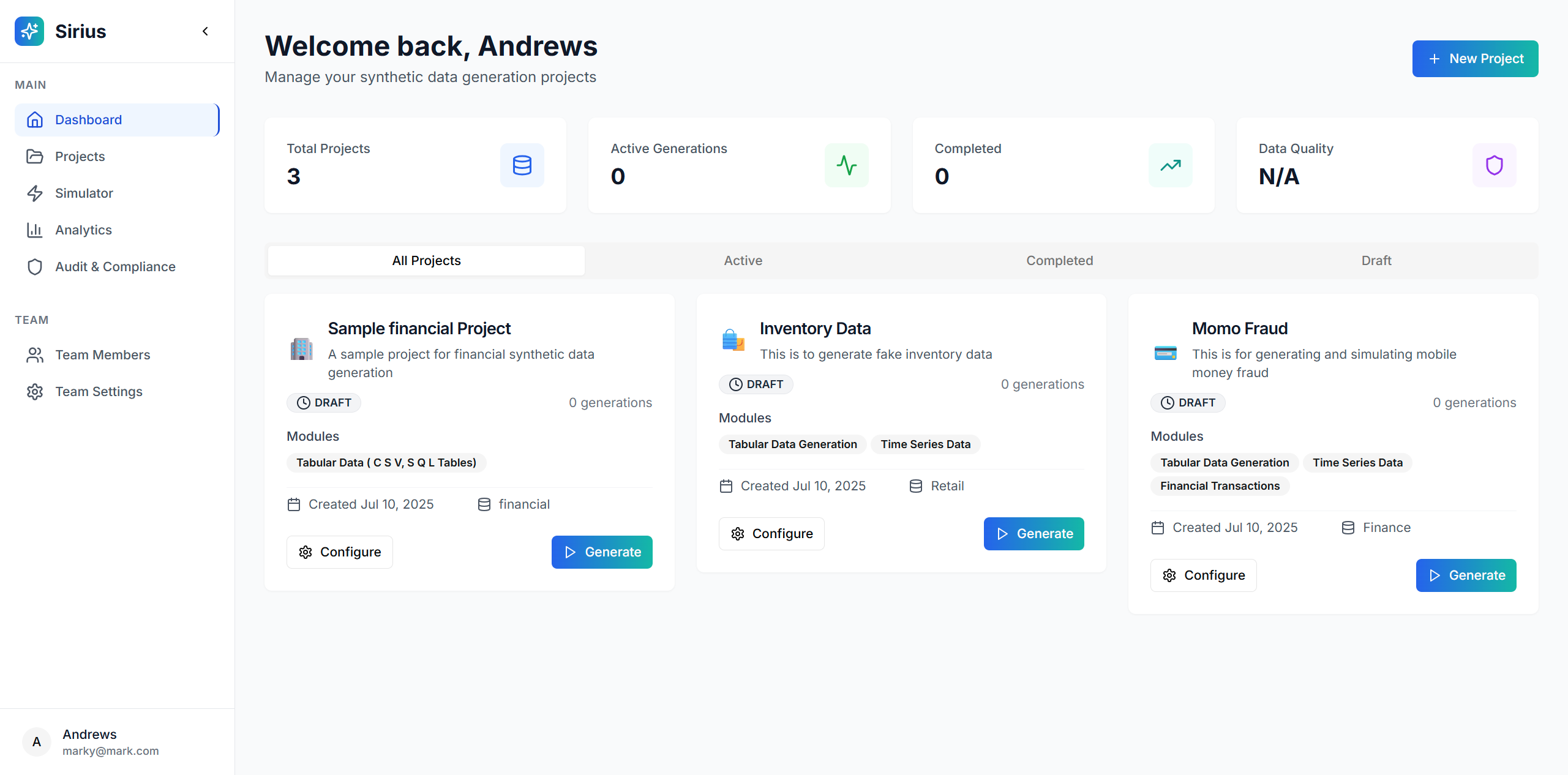
Dashboard
-
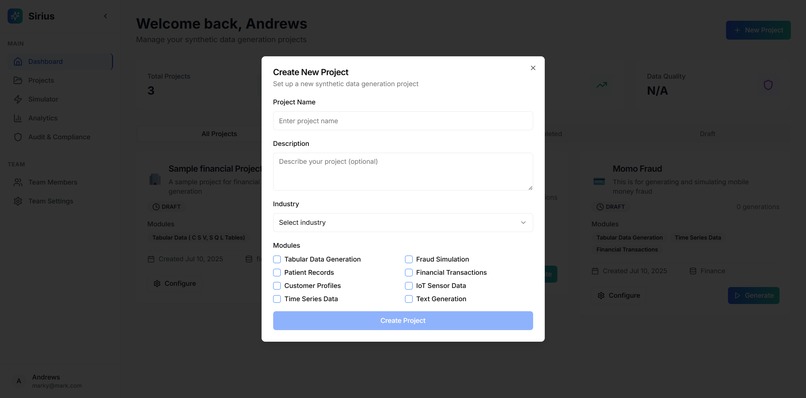
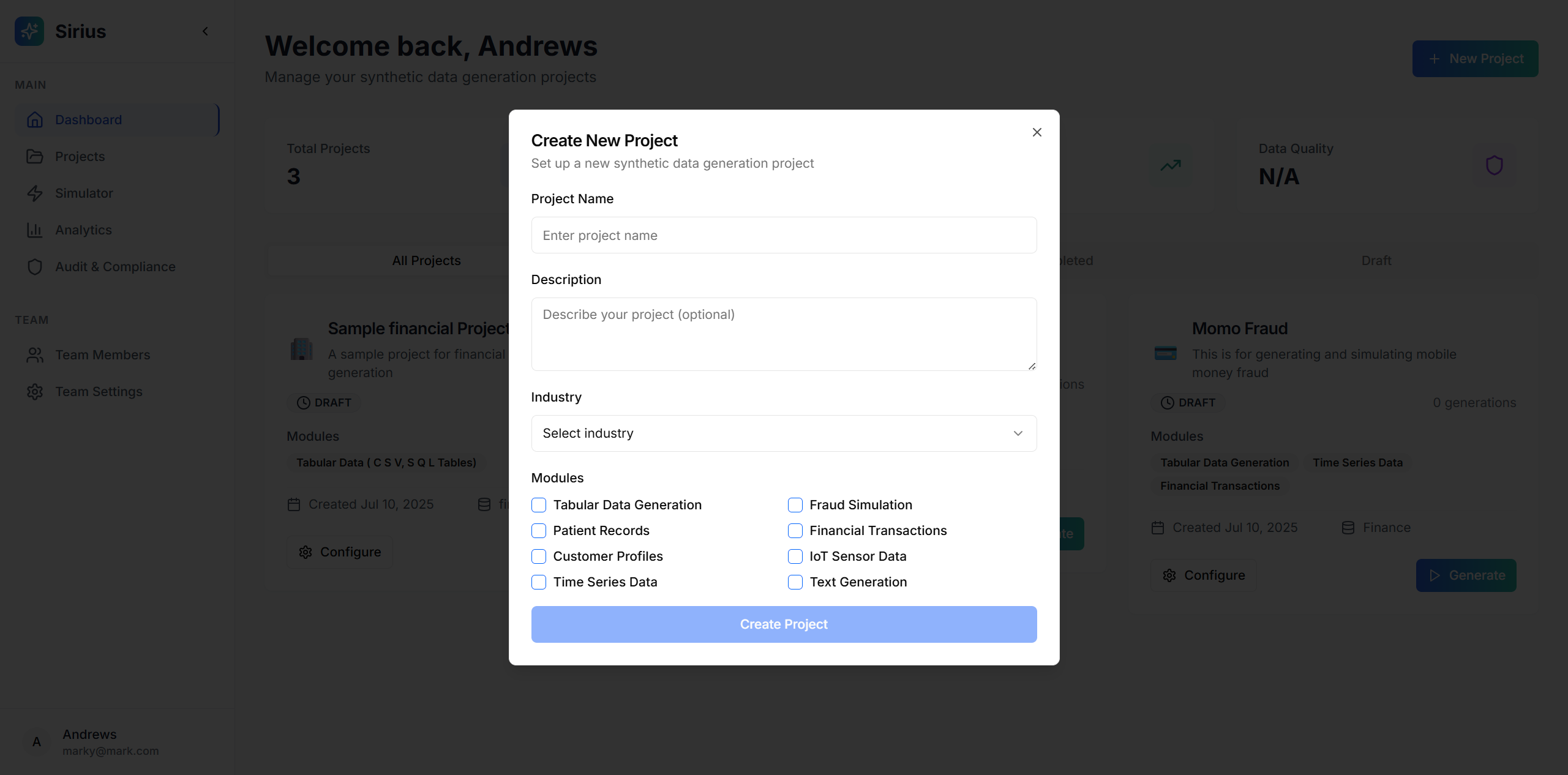
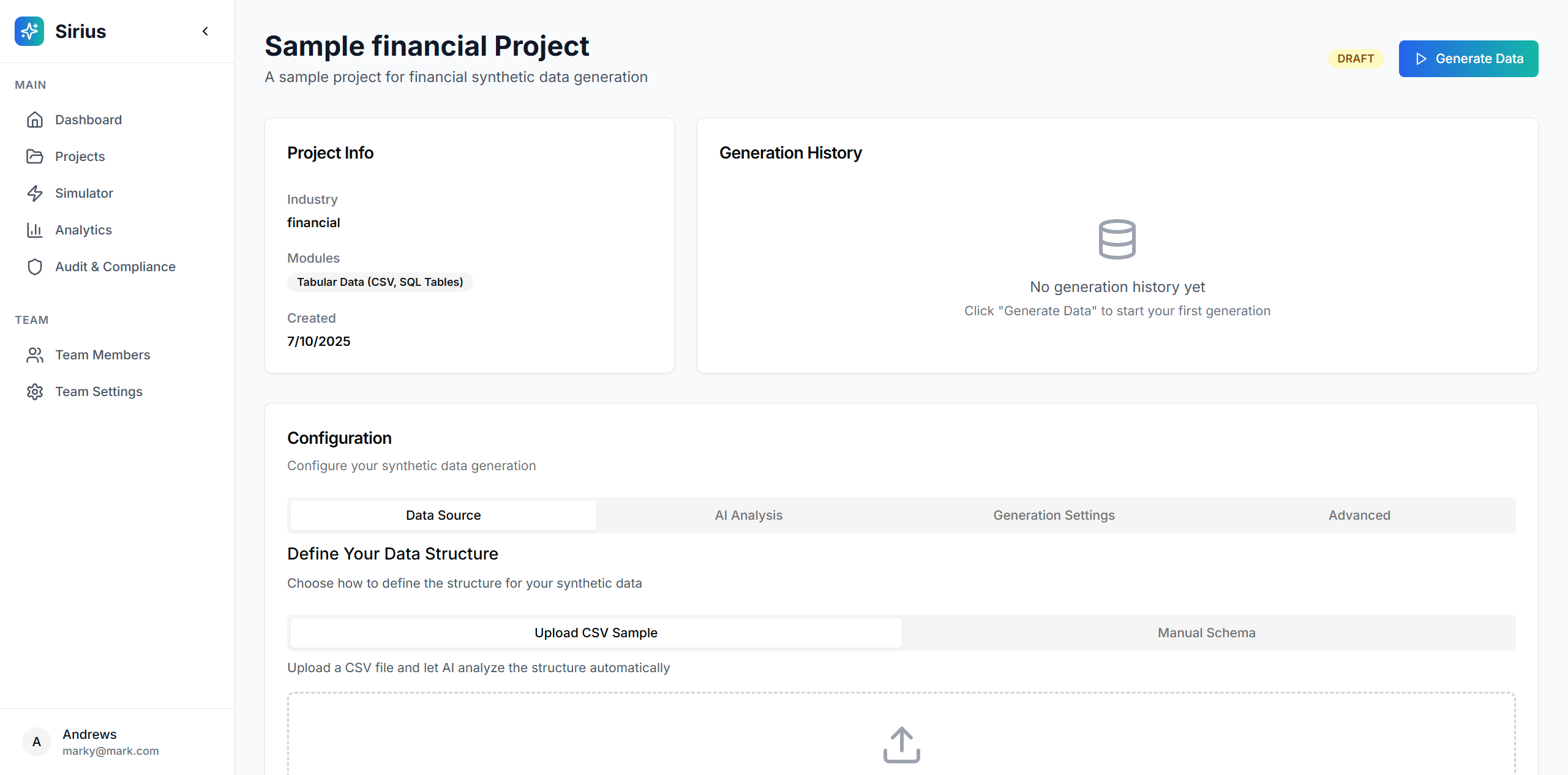
Creating A Project
-
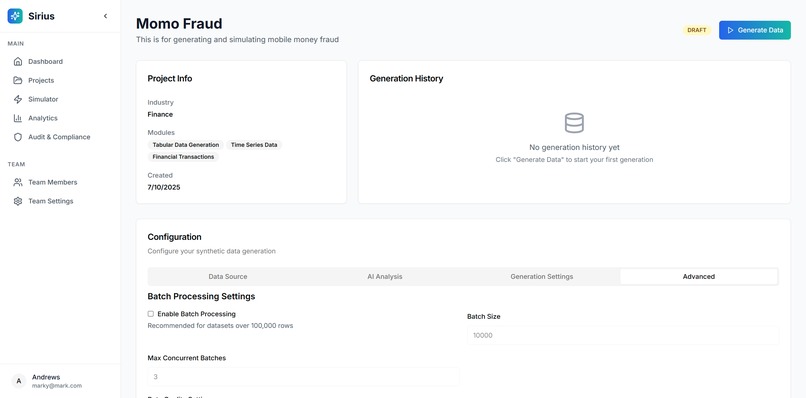
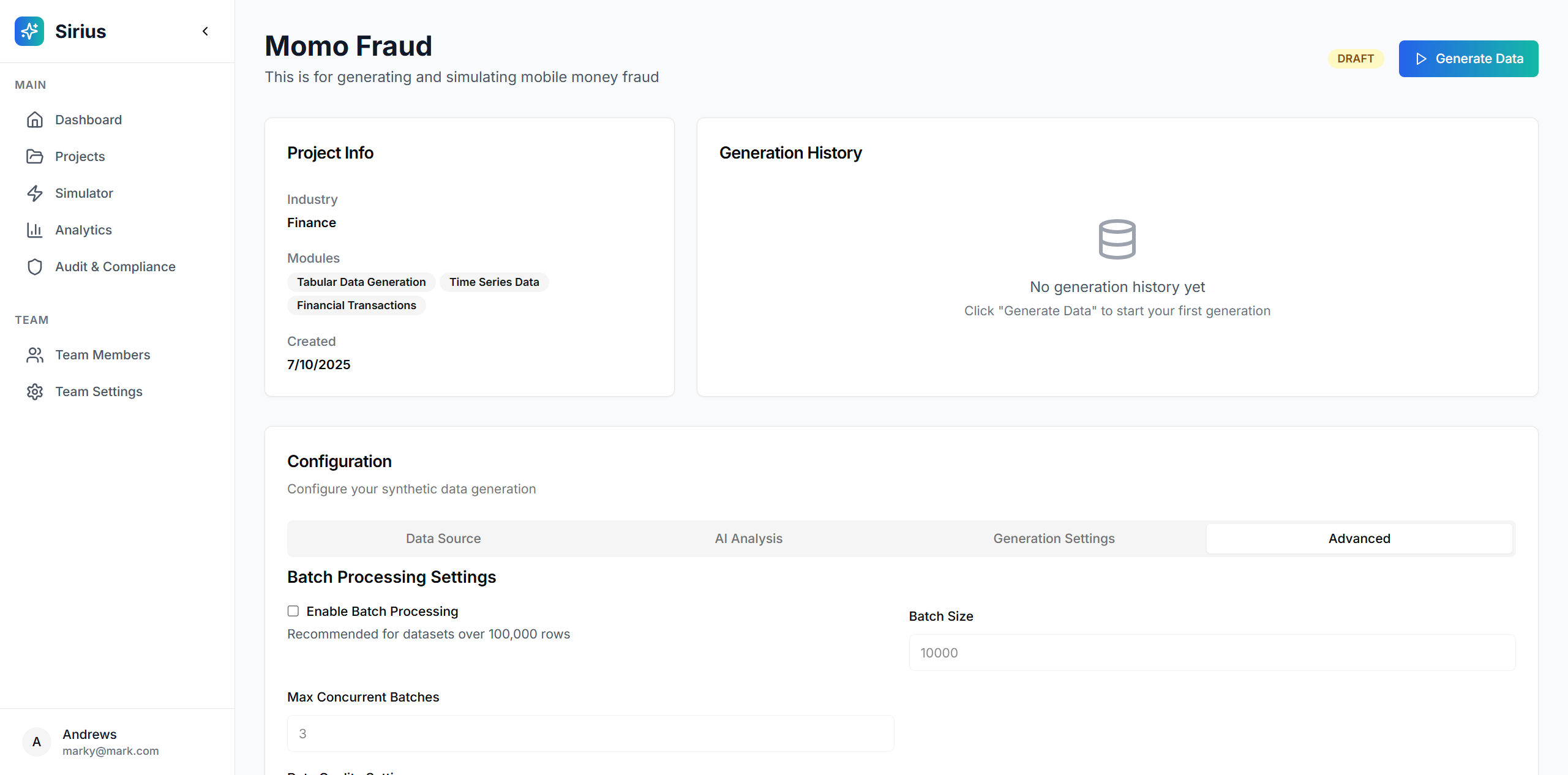
Project Details & Config
-
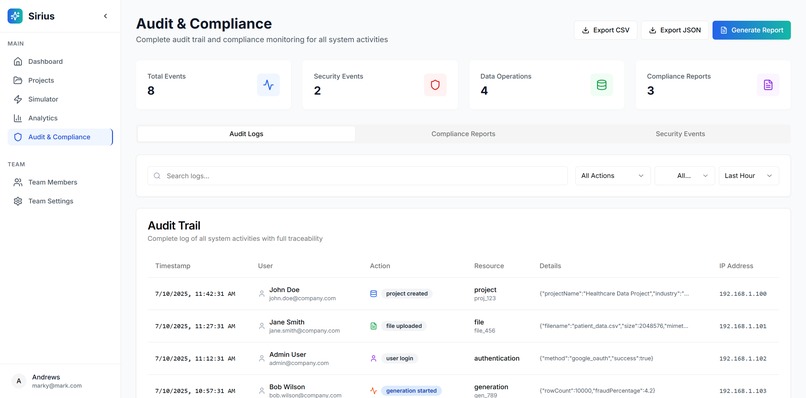
Audit & Compliance Checks
-
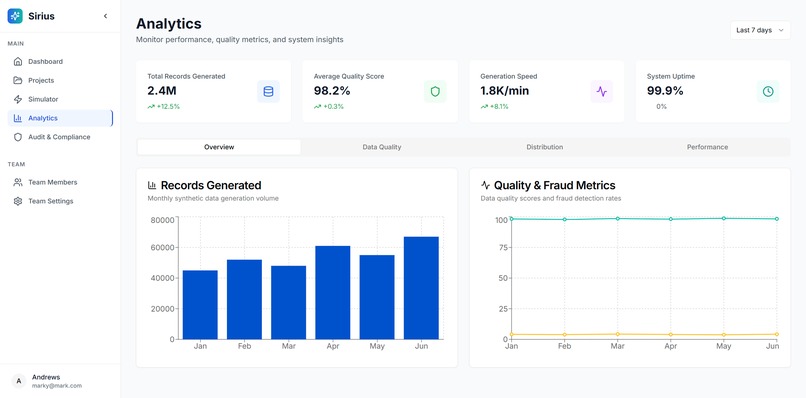
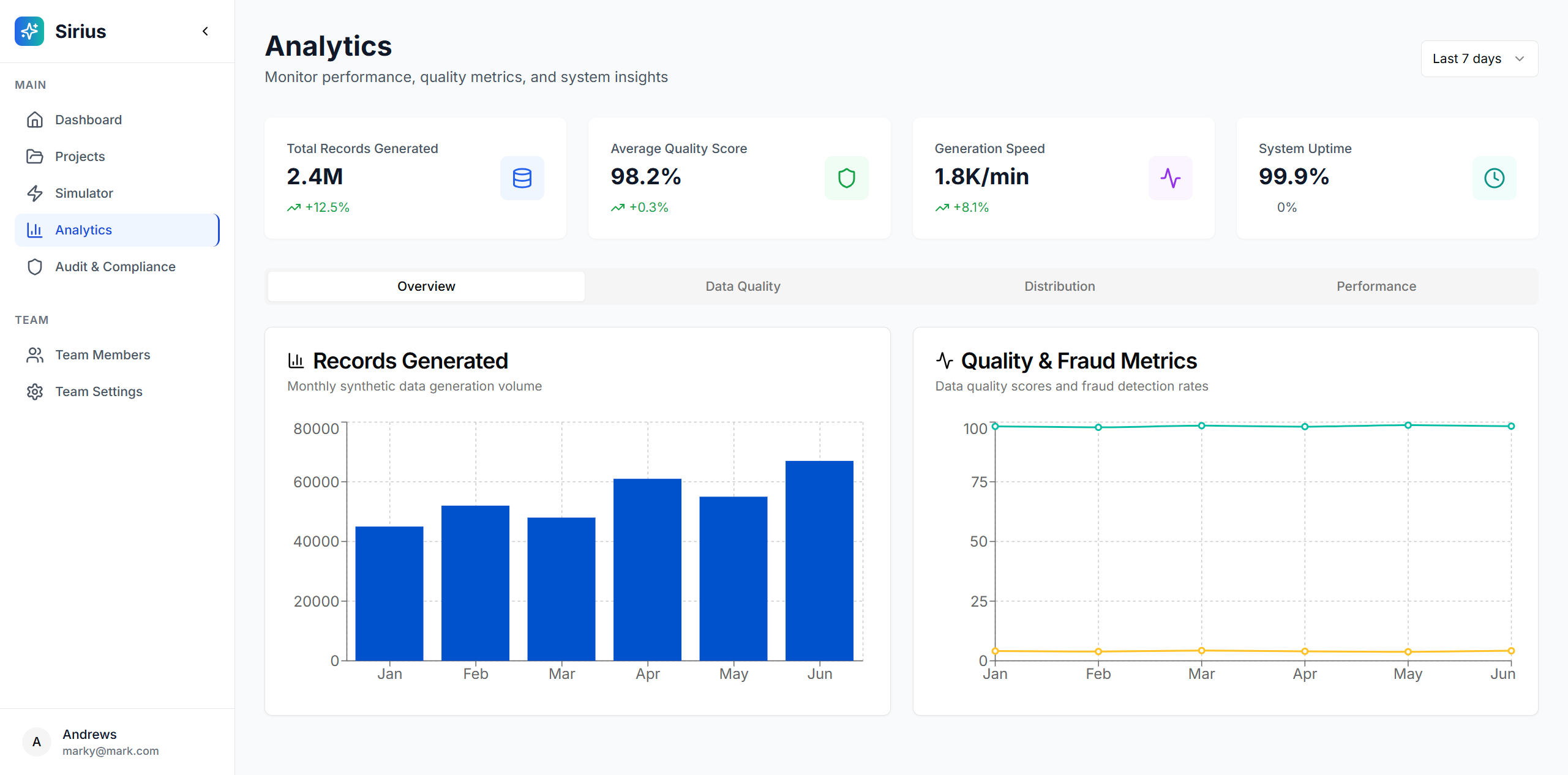
Analytics
-
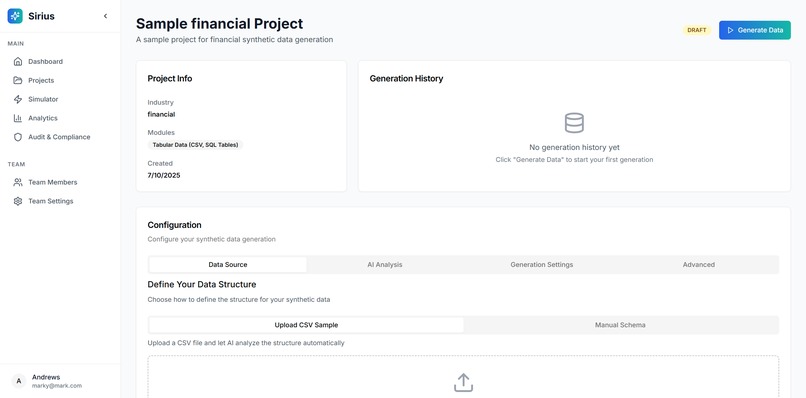
Sample Project After Onboarding
-
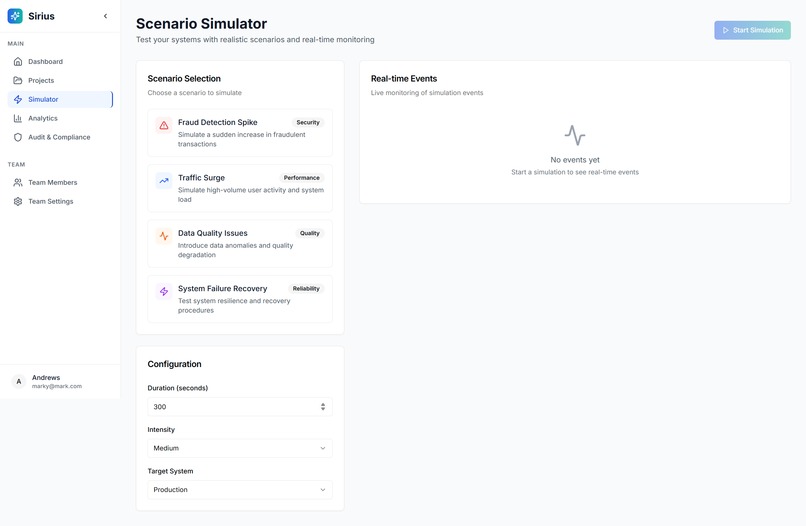
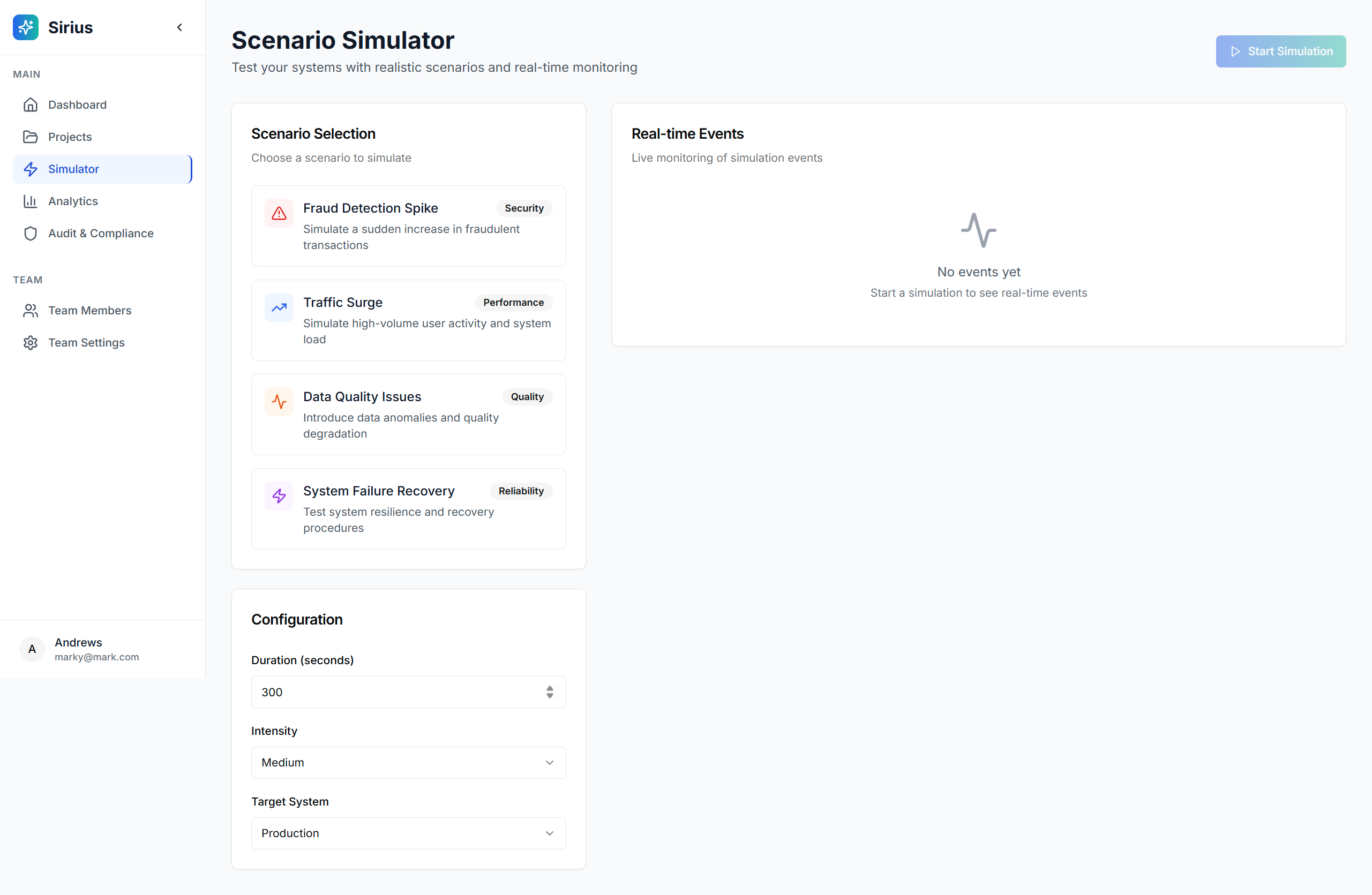
Simulator

Sirius: AI-Powered Synthetic Data Platform
Inspiration
In 2023, I co-founded Radii with three friends - a business intelligence platform designed to help small to medium-sized companies understand their business through a unified data interface. Radii was revolutionary: it connected to databases, Google Drive, Excel files, and other data sources, presenting executives with a single chat-based panel powered by natural language processing and generative AI.
Radii was successful - we onboarded 20 businesses and many individual users. As the CTO and backend engineer, I built integrations with PostgreSQL, Google Drive, Excel parsing, and NLP-to-SQL conversion using large language models. It was an incredible product that ran successfully for over a year.
But we faced a critical problem: testing without real data.
With live users on the platform and sensitive customer data in play, running tests on production systems became risky and irresponsible. But we lacked any alternative.Every time we needed to test new features, we were working with actual customer data - real inventory records, actual financial information, genuine customer details. Yet, we couldn't afford to corrupt or mishandle this sensitive information, but we desperately needed realistic data for testing.
I found myself constantly writing Python scripts to generate test data, primarily using Faker. But Faker was fundamentally limited:
- No African context: Names, addresses, currencies and cultural nuances were completely Western-centric
- No industry awareness: Generic data that didn't reflect healthcare, finance, or retail-specific patterns
- No localization: Couldn't generate data that matched our diverse customer base
- Manual effort: I had to manually prompt ChatGPT for realistic names, then copy-paste into Excel files
This process was incredibly stressful and time-consuming. I would spend hours crafting realistic test datasets instead of building features.
I vividly remember thinking: "If only there was a tool that could understand the context I work in, accept a schema, and generate high-quality, localized, and realistic test data on demand."
Eventually, we had to shut down Radii due to funding challenges. But that painful experience of needing realistic, contextual, privacy-safe test data never left me.
Sirius was born from that frustration - imagining a world where I could have simply defined a schema, specified my industry and region, and instantly generated thousands of realistic, compliant test records.
What it does
Sirius is an AI-powered synthetic data platform that solves the exact problem I faced at Radii - generating realistic, contextual, privacy-compliant test data at scale.
🤖 AI-Powered Intelligence
- Multi-LLM Integration: Supports Amazon Nova Lite and Pro, Anthropic Claude, Llama 4 through Groq, OpenAI GPT-4, Google Gemini, Perplexity, and DeepSeek
- Intelligent Schema Analysis: Upload a CSV and AI automatically detects field types, relationships, and business logic
- Industry-Specific Generation: Healthcare, finance, retail, manufacturing - each with appropriate constraints and patterns
- Cultural Context: Generate data that reflects real-world diversity and localization
🏢 Enterprise-Grade Features
- Team Collaboration: Multi-user workspaces with role-based access control (Owner, Developer, Auditor, Analyst, Editor, Tester, Member)
- Batch Processing: Generate 100k+ rows efficiently with concurrent processing and memory optimization
- Comprehensive Audit Trails: 40+ audit event types for GDPR, HIPAA, and SOX compliance
- Multiple Export Formats: CSV, JSON, SQL, Parquet with format-specific optimization
📊 Quality & Validation
- Real-time Quality Metrics: Completeness, accuracy, consistency, validity, uniqueness scoring
- Statistical Analysis: Distribution matching, correlation preservation, outlier detection
- Validation Reports: Detailed quality assessments with actionable insights
- Privacy Compliance: Generate realistic data without any real PII
🎯 Developer Experience
- Drag-and-Drop Upload: Simple CSV upload with instant preview and analysis
- Real-time Monitoring: Watch your data generation progress with live updates
- Professional UI: Modern, responsive design with dark mode support
- Email Notifications: Get notified when large generations complete
How we built it
Architecture Philosophy
We chose Next.js 14 with the App Router for its full-stack capabilities, allowing us to build both frontend and backend in a single, type-safe codebase while maintaining excellent performance.
AI Integration Strategy
Instead of building our own models, we integrated with multiple LLM providers using a unified interface
This approach provides:
- Flexibility: Users choose their preferred AI provider
- Reliability: Automatic fallback if one provider fails
- Cost Optimization: Different providers for different complexity levels
Database Design
We used Prisma ORM with PostgreSQL for:
- Type Safety: Auto-generated TypeScript types prevent runtime errors
- Complex Relationships: Teams, projects, generation logs, audit trails with proper foreign keys
- Performance: Optimized queries with strategic indexing for large datasets
Real-time Processing
Implemented intelligent batch processing for large datasets
Enterprise Security
Built comprehensive audit logging from day one:
- 40+ Audit Event Types: Every action tracked with context
- Role-Based Access Control: Granular permissions system
- Compliance Ready: GDPR, HIPAA, SOX support built-in
Challenges we ran into
1. AI Response Consistency
Challenge: Different LLM providers returned wildly inconsistent schema analysis results, making it impossible to build reliable generation logic.
Solution: Created a standardized response schema with Zod validation
2. Large Dataset Memory Management
Challenge: Generating 100k+ rows would crash browsers and timeout servers due to memory constraints.
Solution: Implemented intelligent batch processing:
- Concurrent Processing: Multiple batches processed in parallel
- Memory Optimization: Streaming data processing with automatic cleanup
- Progress Tracking: Real-time updates across all batches
- Error Resilience: Continue processing even if individual batches fail
3. Session Management Complexity
Challenge: Users were losing authentication sessions during the multi-step onboarding flow, creating a frustrating experience.
Solution: Switched from JWT to database sessions with NextAuth
4. TypeScript at Scale
Challenge: Complex type definitions for Prisma JSON fields, LLM responses, and nested data structures were causing compilation errors.
Solution: Comprehensive type definitions and proper error handling
Accomplishments that we're proud of
🚀 Technical Achievements
- Multi-LLM Integration: Successfully integrated 5 different AI providers with unified interface
- Enterprise Architecture: Built for scale with proper audit trails and compliance features
- Real-time Processing: Smooth UX for long-running data generation with live progress updates
- Type Safety: 100% TypeScript with comprehensive error handling and validation
🎨 User Experience
- Intuitive Onboarding: 7-step personalized setup flow that adapts to user needs
- Professional UI: Modern design with shadcn/ui components and Framer Motion animations
- Responsive Design: Works seamlessly across desktop, tablet, and mobile devices
- Real-time Feedback: Progress tracking, notifications, and status updates
🔒 Security & Compliance
- Comprehensive Audit Logging: 40+ event types tracked for complete traceability
- Role-Based Access Control: Enterprise-ready permissions with team management
- Privacy-First Design: Generate realistic data without storing any real PII
- Compliance Ready: Built-in support for GDPR, HIPAA, and SOX requirements
📈 Performance & Scalability
- Batch Processing: Handle 100k+ rows efficiently with concurrent execution
- Memory Optimization: Stream processing for large datasets without crashes
- Smart Caching: Optimized database queries and API responses
- Concurrent Processing: Semaphore-controlled resource management
What we learned
AI Integration Insights
- Provider Diversity Matters: Different LLMs excel at different tasks - GPT-4 for complex reasoning, Claude for structured output, Gemini for cost-effectiveness
- Prompt Engineering is Critical: Small changes in prompts can dramatically affect output quality and consistency
- Fallback Mechanisms Essential: AI services can fail unexpectedly - always have backup providers and graceful degradation
Enterprise Development Lessons
- Audit Logging from Day 1: Much easier to build comprehensive logging from the start than retrofit it later
- Type Safety Pays Dividends: TypeScript caught hundreds of potential runtime errors during development
- User Onboarding is Make-or-Break: A smooth first experience determines whether users adopt your platform
Performance Optimization
- Batch Processing is Complex: Managing concurrency, memory usage, and error handling requires careful architecture
- Real-time Updates: Balance between responsiveness and server load - polling vs WebSockets trade-offs
- Database Design: Proper indexing and relationship modeling crucial for performance at scale
Full-Stack Development
- Next.js App Router: Powerful but has a learning curve - server components vs client components
- Prisma ORM: Excellent developer experience with type safety and migration management
- Component Architecture: Reusable components with proper prop interfaces save massive development time
What's next for Sirius
🔮 Immediate Roadmap (Q1 2025)
- Advanced File Formats: XML, Avro, Parquet native support beyond JSON/CSV
- Custom Generation Rules: User-defined business logic and validation constraints
- Real-time Collaboration: Live editing with WebSocket integration for team workflows
- Advanced Analytics: ML-powered insights into data quality and generation patterns
🚀 Enterprise Expansion (Q2 2025)
- Enterprise SSO: SAML and OIDC integration for large organizations
- Advanced Privacy Controls: Differential privacy and k-anonymity implementation
- Webhook System: Real-time notifications and third-party integrations
- API Rate Limiting: Advanced quota management and usage analytics
🌟 Platform Vision (2025-2026)
- Distributed Processing: Multi-node processing for massive enterprise datasets
- Mobile Application: Native mobile experience for on-the-go data generation
- Template Marketplace: Community-driven schemas and generation templates
- Custom AI Models: Fine-tuned models trained on user-specific patterns
🎯 Long-term Impact
Our vision is to make Sirius the standard for synthetic data generation, enabling organizations worldwide to:
- Innovate Faster: Remove data bottlenecks from development and testing cycles
- Stay Compliant: Built-in privacy and regulatory compliance without compromise
- Scale Globally: Enterprise-grade infrastructure that grows with your needs
- Democratize AI: Make realistic synthetic data accessible to developers everywhere
Sirius represents the future I wished existed during my Radii days - where developers can focus on building amazing products instead of wrestling with test data generation. We're not just solving a technical problem; we're removing a fundamental barrier to innovation in the AI-driven world.
The pain I felt manually crafting test data at 2 AM, the stress of working with real customer data, the hours lost to data preparation instead of feature development - Sirius ensures no one working with sensitive data has to experience that again.
Built with ❤️ to solve a real problem that every one faces.
Built With
- framer
- langchain
- lucide
- mailgun
- nextjs
- postgresql
- prisma
- react
- recharts
- shadcn
- tailwind
- typescript



Log in or sign up for Devpost to join the conversation.