-
-
Home Page
Inspiration
Every year, emergency dispatchers answer calls where the caller is panicked, the connection is bad, and the first ninety seconds determine how a response gets prioritized. While researching this problem for UC Berkeley's AI Hackathon, we kept coming back to the same observation: a dispatcher already has access to incredibly rich information on every call, the words spoken, the sounds happening in the background, the caller's vocal stress, but almost none of it gets captured or used systematically. It mostly lives and dies in one trained person's working memory during a single phone call.
We wanted to build something that turns a raw, messy audio recording into the kind of structured report a dispatcher could read in seconds: what happened, where, how dangerous it sounds, and why the system thinks so. At the same time, we were deliberate that this stay a copilot, never an autonomous decision maker, in a domain where a wrong confident guess can cost a life.
What it does
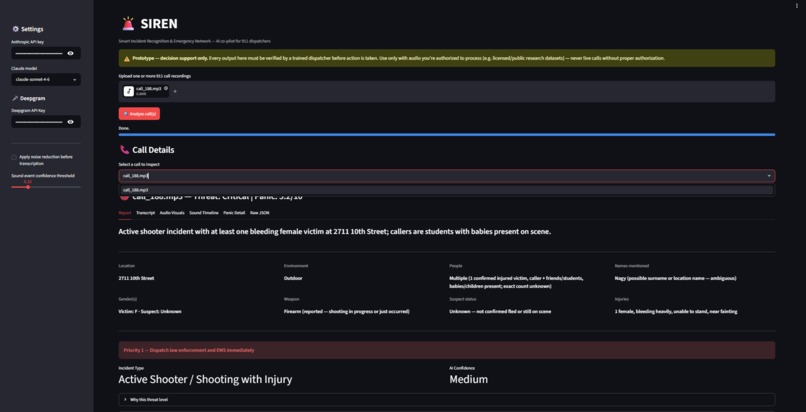
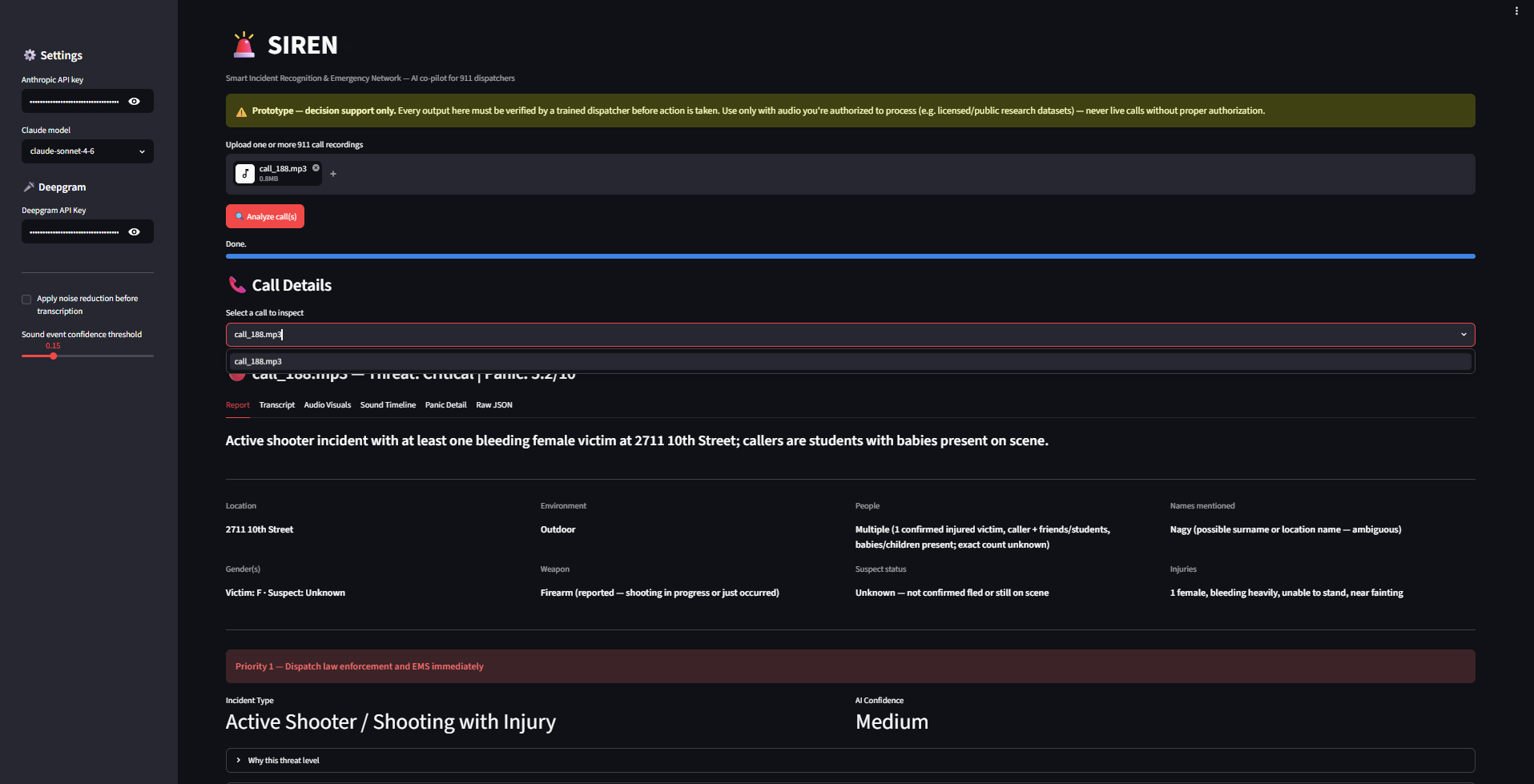
Upload a 911 call recording and SIREN returns a full incident report: a timestamped transcript, a timeline of background sounds such as sirens, glass breaking, or raised voices, an explainable panic score built from five separate acoustic and linguistic signals, and a threat assessment written by Claude that includes its own confidence level and an explicit note whenever information is missing or unclear. Upload several calls and they land in a Dispatch Queue, sorted by threat level, the way a real dispatcher actually has to triage a queue of incoming calls rather than look at just one.
How we built it
The pipeline runs in five stages. librosa loads and resamples the audio. Google's YAMNet model classifies environmental sound, but not in the usual way: instead of only keeping each frame's single loudest label (which is almost always "Speech," since a talking caller tends to dominate loudness), we score every category of interest independently, every frame, so a quiet siren or alarm underneath a caller's voice still gets flagged instead of being drowned out. Deepgram, or a fully offline fallback, produces a diarized transcript. A heuristic panic detector then blends five weighted, individually visible signals into one score from 0 to 10:
$$ \text{PanicScore} = 10 \times \left(0.20\,S_{\text{rate}} + 0.25\,S_{\text{energy}} + 0.15\,S_{\text{pitch}} + 0.15\,S_{\text{repeat}} + 0.25\,S_{\text{emotion}}\right) $$
where each $S$ term captures speech rate, vocal energy variability, pitch variability, repeated phrases, and emotional language, so a dispatcher can see exactly why a call scored the way it did instead of trusting a black box number. Finally, Claude Sonnet reads the transcript, the sound events, and the panic breakdown together and returns a structured incident report: incident type, threat level, recommended priority, a merged timeline, and an explicit human review note. Everything is tied together in a Streamlit dashboard, containerized with Docker, and deployed to Azure Container Apps so judges could open a live link instead of only seeing a local demo.
Challenges we ran into
The signal processing side was hard in the way we expected. Our first instinct was to low pass filter the audio to try to isolate background noise from speech, and it simply did not work; speech and background sound overlap across almost the entire frequency range, so zeroing out FFT bins mostly just distorts the recording rather than separating anything useful. Scoring every sound category in every frame, independently, turned out to be the real fix.
What we did not expect was how much harder the deployment would turn out to be than the model itself. Once SIREN was behind a public Azure link, it started returning intermittent 503 errors that looked, at first, like a single bug, but turned out to be three separate problems stacked on top of each other. The container was quietly scaling down to zero after a few idle minutes, so the first request after any gap had to cold start an entire TensorFlow process from nothing. Once we pinned it to a single warm replica, a second issue surfaced: Streamlit keeps a session's state in memory on whichever replica served it, so without session affinity enabled, any extra replica spun up under load had no idea a given browser session even existed. And underneath both of those, we discovered that Streamlit itself had recently switched its web server from Tornado to Starlette and Uvicorn, and that our YAMNet model was being downloaded fresh from TF Hub on every container restart, a network call that could take anywhere from several seconds to over a minute and blocked the single worker process long enough for the platform to give up and return an error. The fix that mattered most was baking the model into the Docker image at build time instead of fetching it at request time, turning a real reliability risk into something that simply does not happen anymore.
We also spent real effort on the language model layer. Getting Claude to return reliably parseable JSON, every time, across wildly different call recordings, took careful prompt design. More importantly, in a domain like emergency dispatch, a model that sounds confident while being wrong is actively dangerous, so we explicitly instructed Claude to flag low confidence and missing information rather than filling gaps with a plausible sounding guess, and made sure that note surfaces directly in the dispatcher facing report instead of getting buried.
Accomplishments that we're proud of
We are proud that two of the riskiest technical bets in this project, the overlapping per category sound detection and the fully explainable panic score, both paid off and became some of the most well received parts of every demo. We are equally proud of getting a TensorFlow heavy machine learning pipeline running reliably behind a public link rather than only on a single laptop, and of debugging that deployment down to its actual root causes instead of papering over an intermittent error with retries. Getting Claude to consistently return clean, structured JSON across very different call recordings, while still being willing to say it was not confident about a given field, is also something we are proud of, since both reliability and honesty mattered just as much as accuracy here.
What we learned
Beyond the audio signal lesson above, the biggest takeaway was about debugging layered systems under time pressure. Four genuinely different root causes, a scaling setting, a missing session affinity flag, an upstream framework migration we had no control over, and a lazily downloaded model, all manifested as the exact same symptom from the outside: an intermittent 503. The only way through was refusing to guess at a single fix and instead separating platform level causes from application level causes one at a time, backed by real evidence such as replica health, response timings, and container logs at every step.
We also learned that explainability is worth the extra code. When we showed people the five weighted components behind the panic score instead of a single number, they trusted the system noticeably more, and that trust is the entire point of a decision support tool a real dispatcher would actually want to use.
What's next for SIREN
The most valuable next step is real source separation instead of frequency based filtering, using a dedicated speech enhancement or audio source separation model to actually pull foreground speech and background sound apart, rather than only classifying them while they overlap. We would also like to move toward a live streaming mode that updates the dashboard as audio arrives, instead of waiting for a full recording to finish, which matters a lot for an actual live emergency call. A polished PDF export of the dispatcher report is a natural next step beyond the markdown export already in the Report tab, since that is the format many real dispatch centers would want to file or hand off. Longer term, we would want to validate the panic score and threat assessment against real dispatcher judgment on a larger, properly licensed dataset, and explore support for multiple languages, since emergency calls are made in every language a community speaks, not only English.
Built With
- deepgram
- librosa
- python
- sonnet
- tensorflow
- yamnet

Log in or sign up for Devpost to join the conversation.