-
-
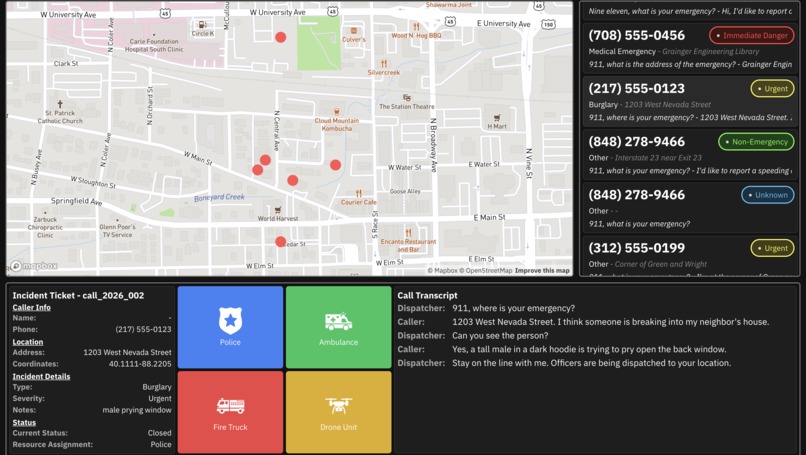
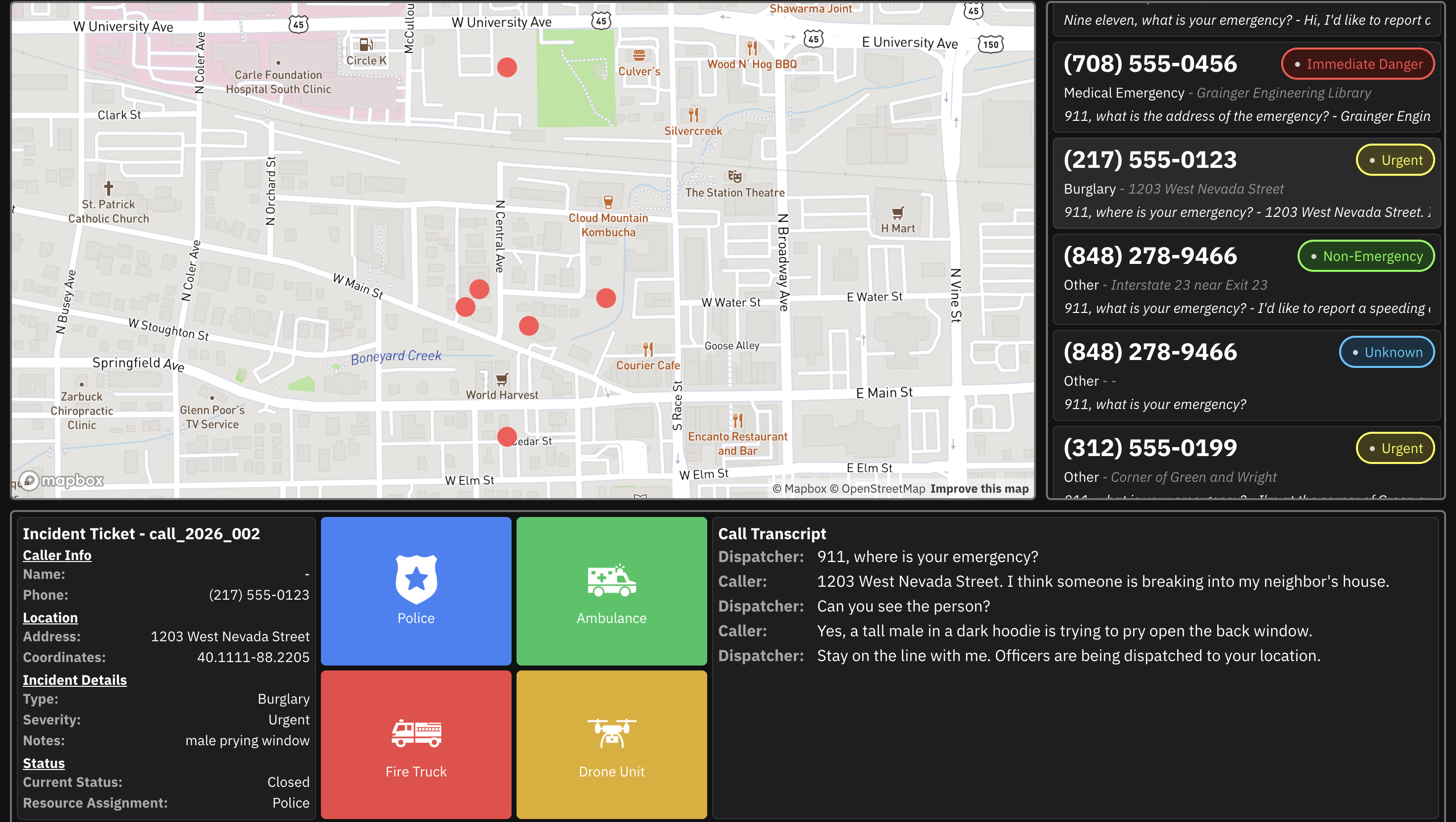
Computer Aided Dispatcher UI
-
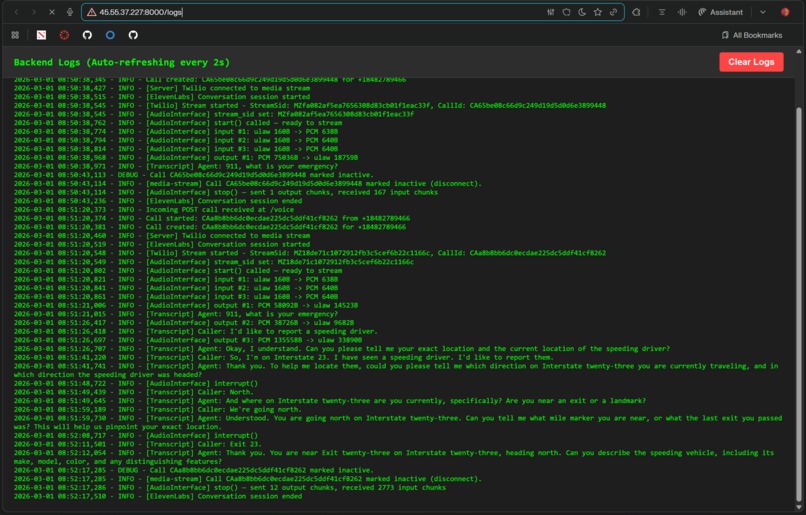
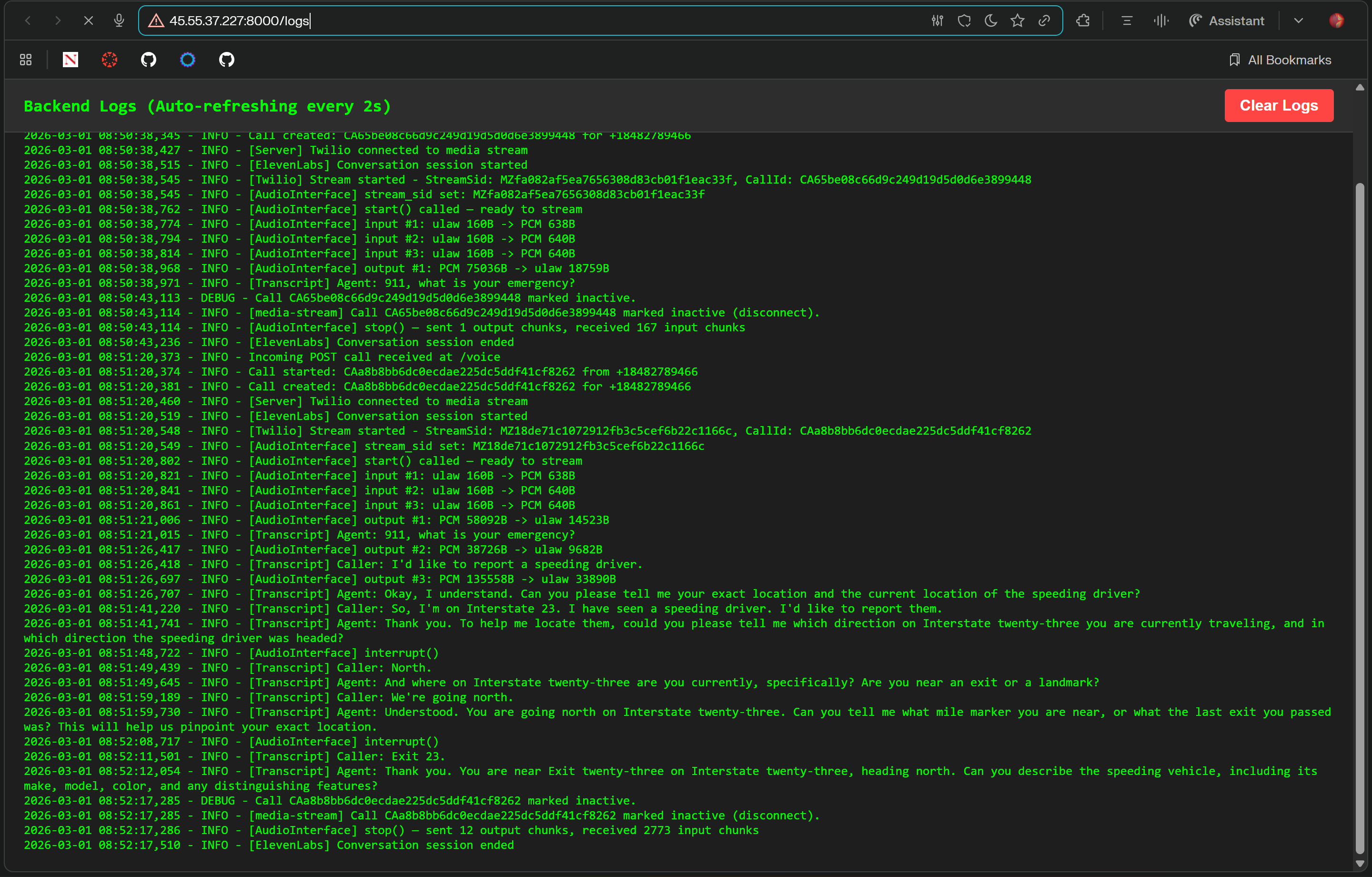
Logs to Debug
-
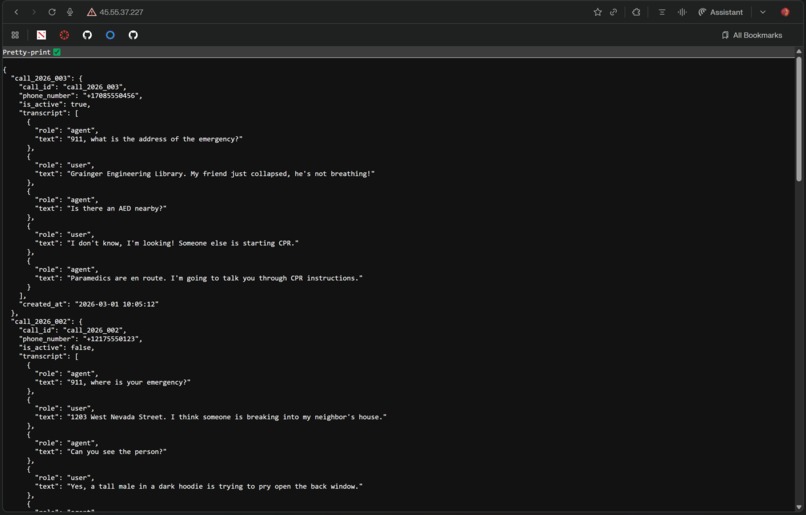
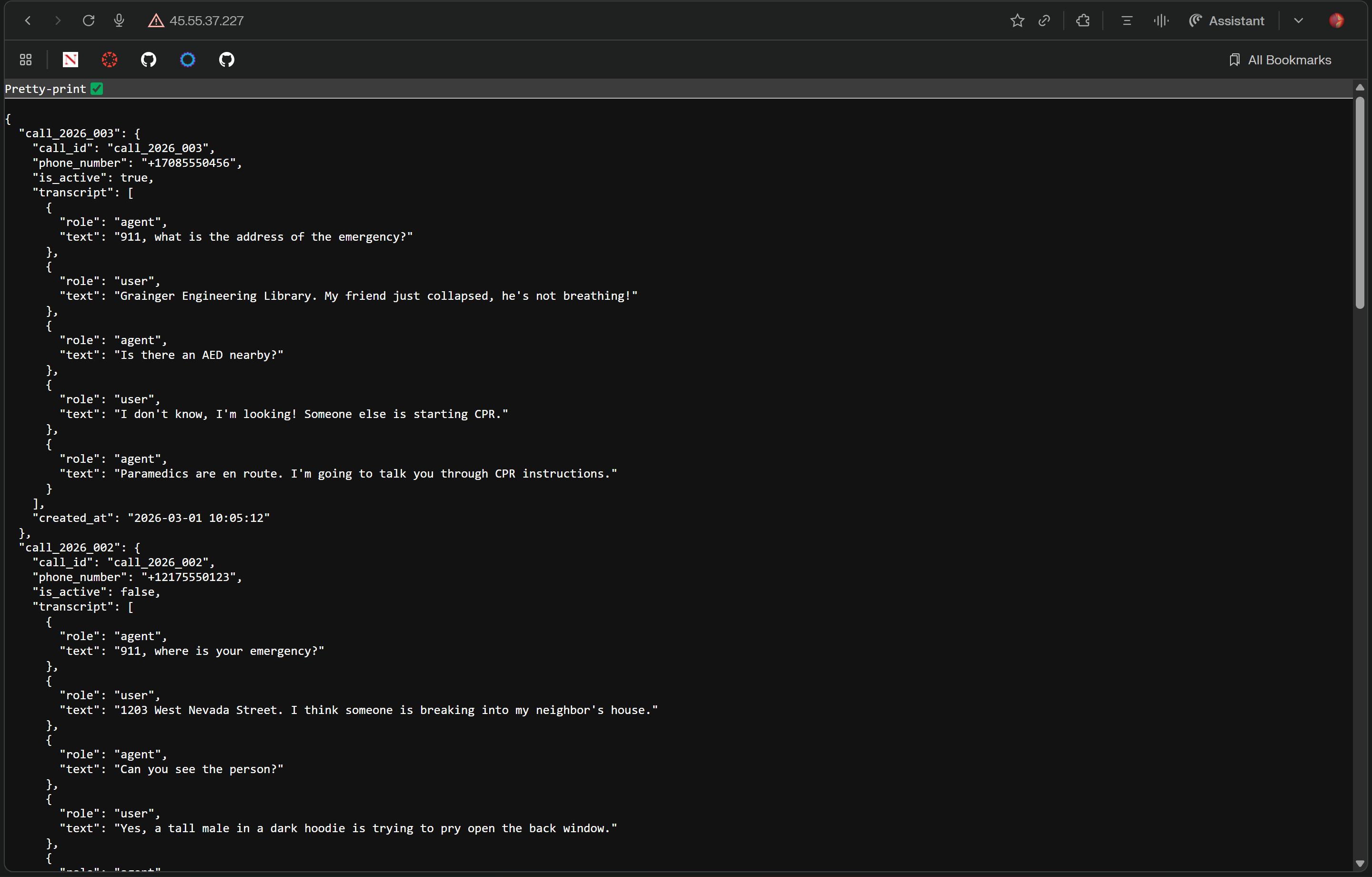
Database View
Inspiration
82% of 911 call centers in the US are understaffed. 240 million calls come in every year, and dispatch centers are facing a 30% staffing shortage nationwide. In cities like Denver, 6% of calls take over 2 minutes to answer. In Portland, average hold times hit 53 seconds. People are dying on hold because the system built in 1968 can't keep up with modern demand. We built Siren because no one should ever hear a recording when they're calling for help.
What it does
Siren is an AI-powered voice agent that answers 911 calls when human dispatchers can't. The moment a call comes in, Siren picks up, speaks naturally, stays calm under pressure, and extracts the critical information dispatchers need: location, nature of the emergency, number of people involved, and severity. Our LLM-based decision making system dispatches the right responders to each call and provides them with a near instant briefing of the situation, far quicker than any human could coordinate. Our AI-powered context awareness doesn't stop within a single call. Siren combines context across multiple calls in real time. In large scale events like mass shootings, natural disasters, or child abductions, information from multiple callers is synthesized instantly to give responders a unified, evolving picture of the situation. These contextual features and the agent's specialized knowledge in addressing medical emergencies, fire hazards, and other critical situations are powered by Supermemory.
How we built it
We built Siren using ElevenAgents for natural, human-quality voice synthesis so callers feel like they're speaking with a real person. We used Modal for near instant inference on call transcripts to assign severity scores, choose the type of first responders and the briefing to each responder. Open source model deployment on Modal also allows us to keep conversations with 911 private and secure. Our API and website is deployed on DigitalOcean.
Challenges we ran into
The biggest challenge was getting all the services to actually talk to each other. Our pipeline touches a lot of moving parts. A phone call comes in through Twilio, which routes it to our FastAPI backend hosted on DigitalOcean. From there, the call streams to ElevenLabs Agents, which handles transcription and sends it back to our FastAPI server. That transcription then gets forwarded to Modal, where we run inference on an open source model that powers our decision making LLM. Once the model makes a dispatch decision, those results get routed back to our frontend UI, also hosted on DigitalOcean. On top of all that, ElevenLabs Agents also streams voice responses back through the same infrastructure to the 911 caller, so the conversation feels natural and uninterrupted. Getting all of these services to communicate reliably in both directions with minimal latency was by far the hardest part of the build.
Accomplishments that we're proud of
We're proud that Siren can hold a coherent, calming conversation with a distressed caller and extract all the information a human dispatcher would need in a fraction of the time. The voice quality is indistinguishable from a real operator, which is critical for caller trust. We also built a triage system that accurately categorizes emergencies by severity and routes them accordingly. Most importantly, Siren picks up instantly zero hold time, every single call scaling easily as compute should.
What's next for Siren
We want to expand Siren's capabilities to support multilingual callers, as over 25 million Americans have limited English proficiency and language barriers during a 911 call can be fatal. We're also exploring expanding our model's RAG database so it can provide accurate medical, fire safety, and other instructions at expert quality, walking callers through CPR, tourniquet application, or safe evacuation while responders are en route. Another priority is integration with existing Computer Aided Dispatch systems so Siren can plug directly into real dispatch center infrastructure rather than operating as a standalone tool. We also want to build out our multi call context engine further, enabling Siren to generate live incident maps and timelines that update as new calls come in during large scale events. On the infrastructure side, we plan to fine tune our own open source models specifically on emergency dispatch conversations to improve triage accuracy and reduce latency even further.
Built With
- deepseek
- digitalocean
- elevenlabs
- fastapi
- modal
- python
- react
- sql
- supermemory
- twilio


Log in or sign up for Devpost to join the conversation.