Inspiration
ScottyLab's CMU Course 'API' isn't quite an API. It's just a course scraper. Moreover, it fails combine the data from FCEs and current course schedules into a usable format. For web applications that could potentially leverage the use of an API and easy-to-use formatting, this course API is lacking.
What it does
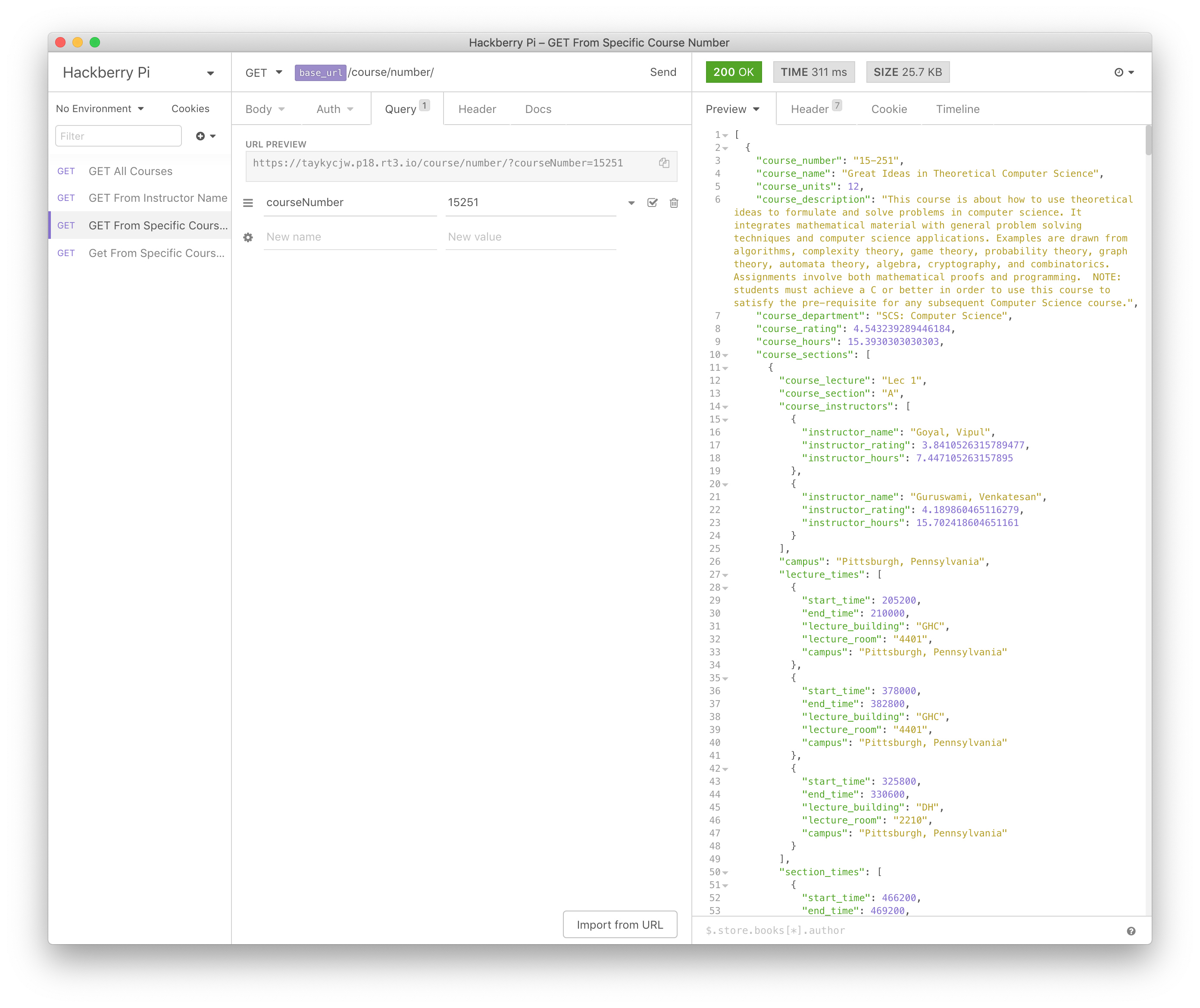
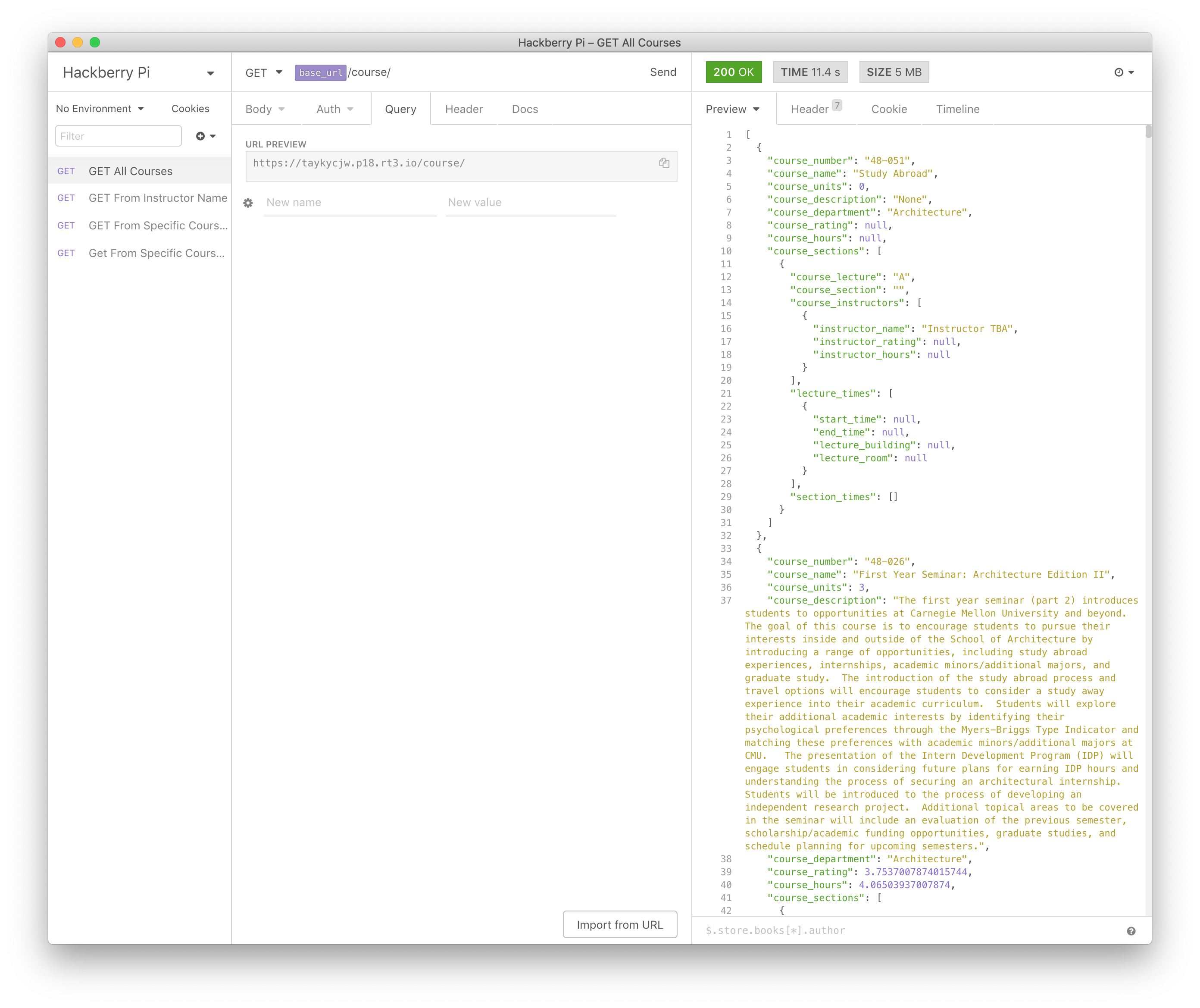
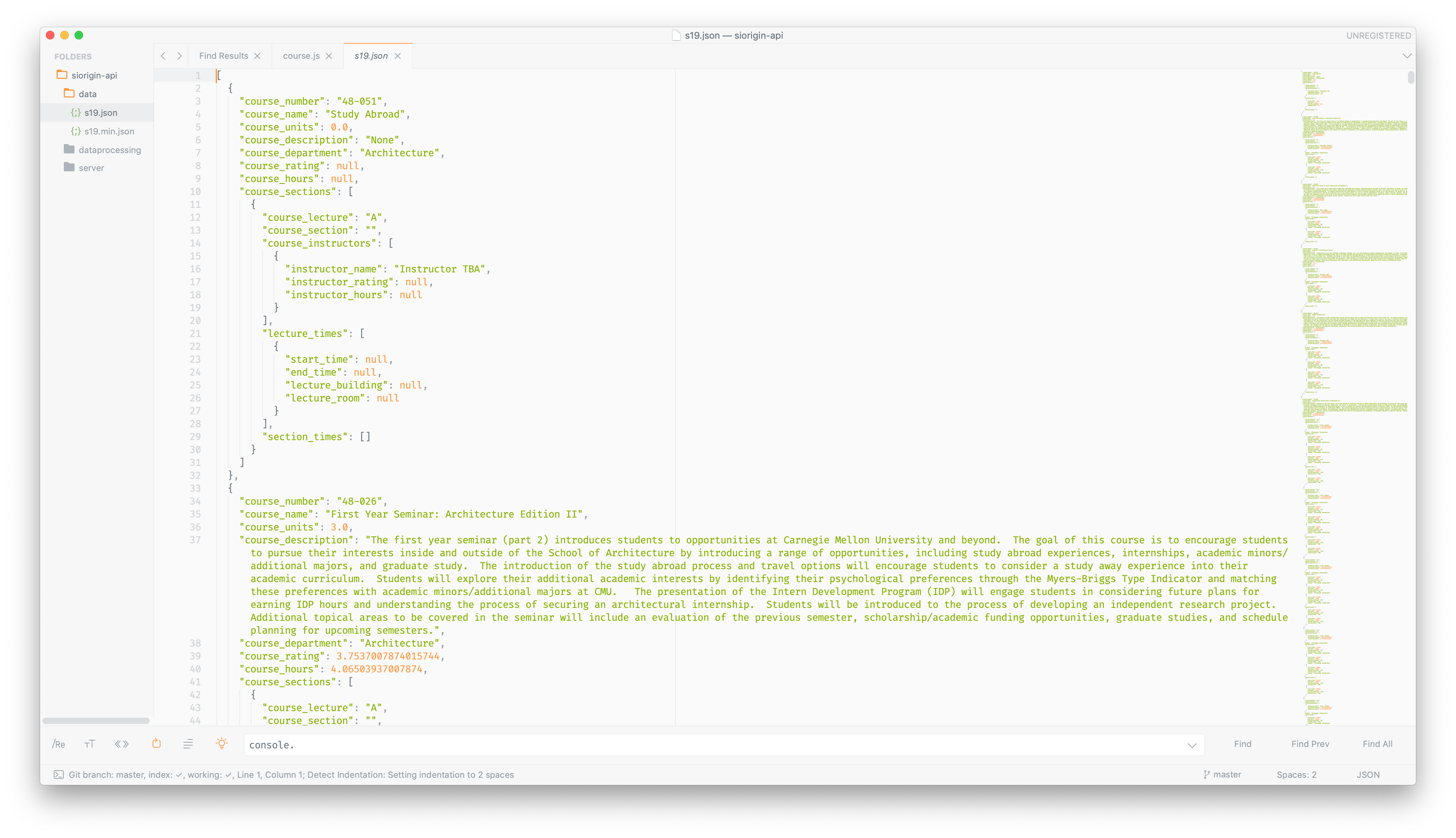
This project has two parts. The first part is a modification to the current course scraper. Given FCE data and the semester to scrape, the course scraper will make both a JSON and a minified JSON of the following format:
[
...
{
"course_number": "15-122",
"course_name": "Principles of Imperative Computation",
"course_units": 10.0,
"course_description": "For students with a basic understanding of programming (variables, expressions, loops, arrays, functions). Teaches imperative programming and methods for ensuring the correctness of programs. Students will learn the process and concepts needed to go from high-level descriptions of algorithms to correct imperative implementations, with specific application to basic data structures and algorithms. Much of the course will be conducted in a subset of C amenable to verification, with a transition to full C near the end. This course prepares students for 15-213 and 15-210. NOTE: students must achieve a C or better in order to use this course to satisfy the pre-requisite for any subsequent Computer Science course.",
"course_rating": 4.049813046937152,
"course_hours": 13.704470962609388,
"course_sections": [
{
"course_lecture": "Lec 1",
"course_section": "A",
"course_instructors": [
{
"instructor_name": "Kaynar, Zeliha Dilsun",
"instructor_rating": 3.9335607476635515,
"instructor_hours": 11.452915887850466
},
{
"instructor_name": "Cervesato, Iliano",
"instructor_rating": 3.8843656716417914,
"instructor_hours": 13.698955223880596
}
],
"campus": "Pittsburgh, Pennsylvania",
"lecture_times": [
{
"start_time": 205200,
"end_time": 210000,
"lecture_building": "DH",
"lecture_room": "2315",
"campus": "Pittsburgh, Pennsylvania"
},
{
"start_time": 378000,
"end_time": 382800,
"lecture_building": "DH",
"lecture_room": "2315",
"campus": "Pittsburgh, Pennsylvania"
}
],
"section_times": [
{
"start_time": 120600,
"end_time": 123600,
"section_building": "GHC",
"section_room": "CLSTR"
},
{
"start_time": 466200,
"end_time": 469200,
"section_building": "WEH",
"section_room": "5310"
}
]
},
...
]
...
]
The start_time and end_time are in seconds from Sunday at midnight. This structure of the data allows web applications to easily understand the whole picture without having to do data manipulation on the client side.
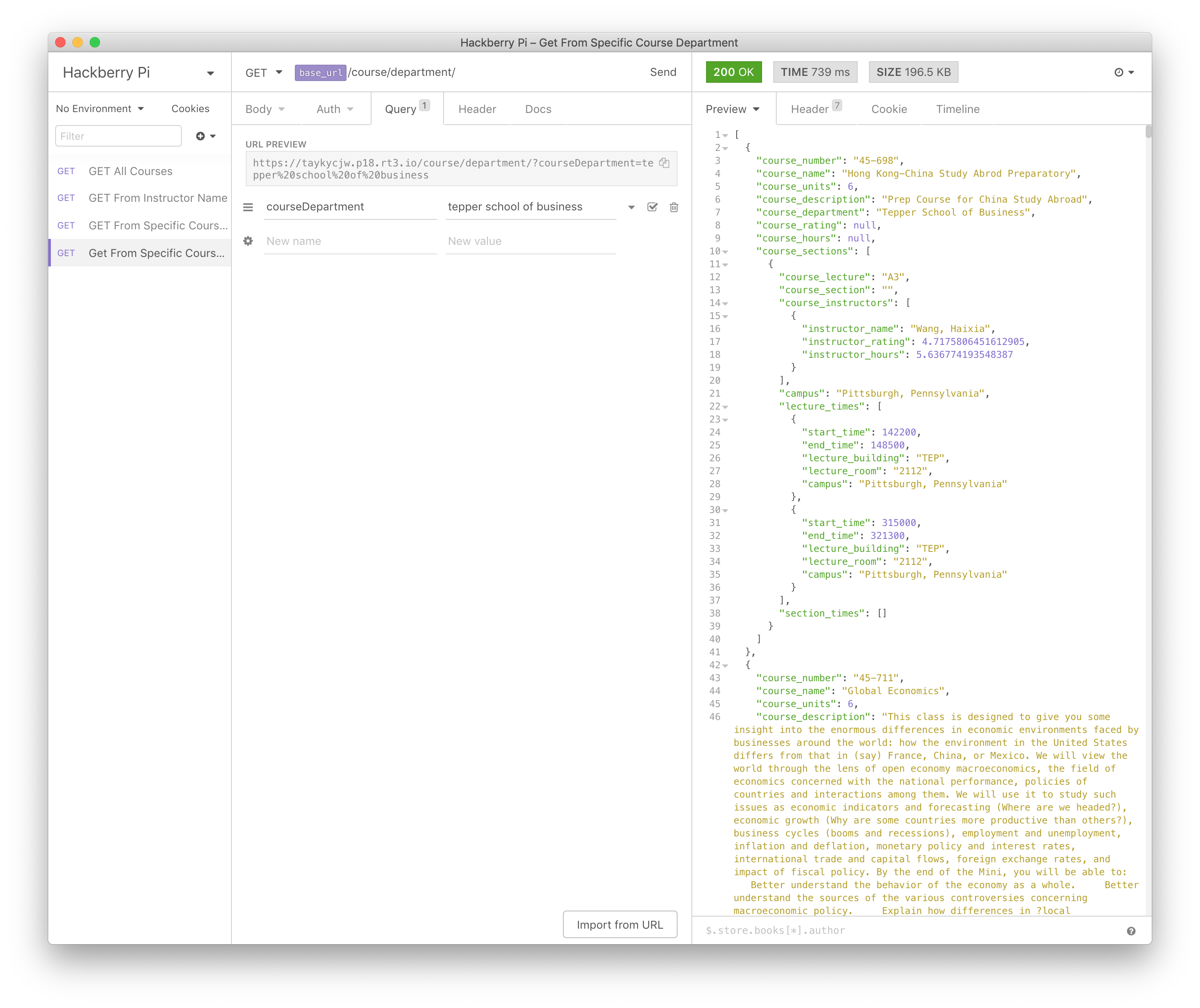
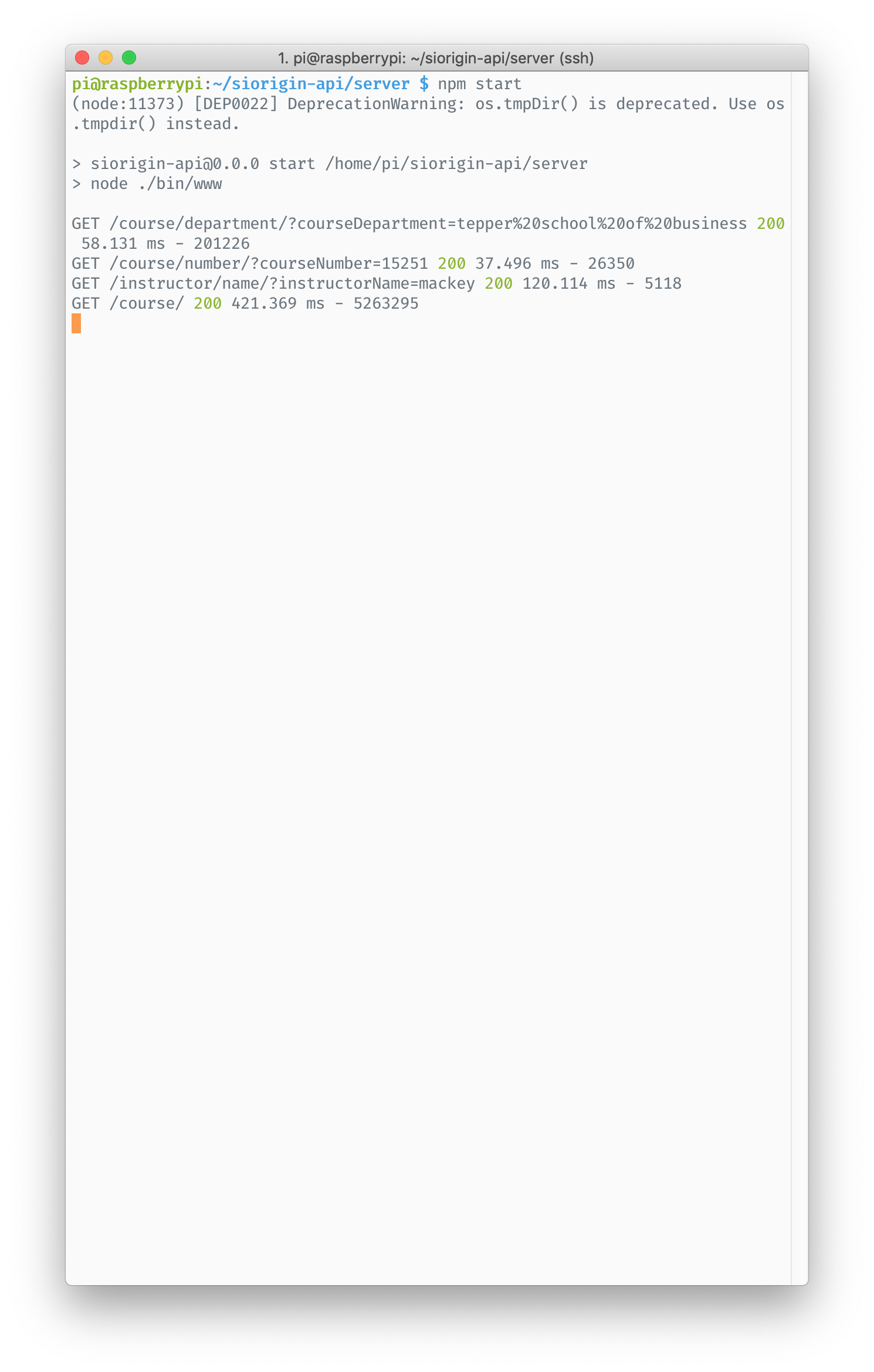
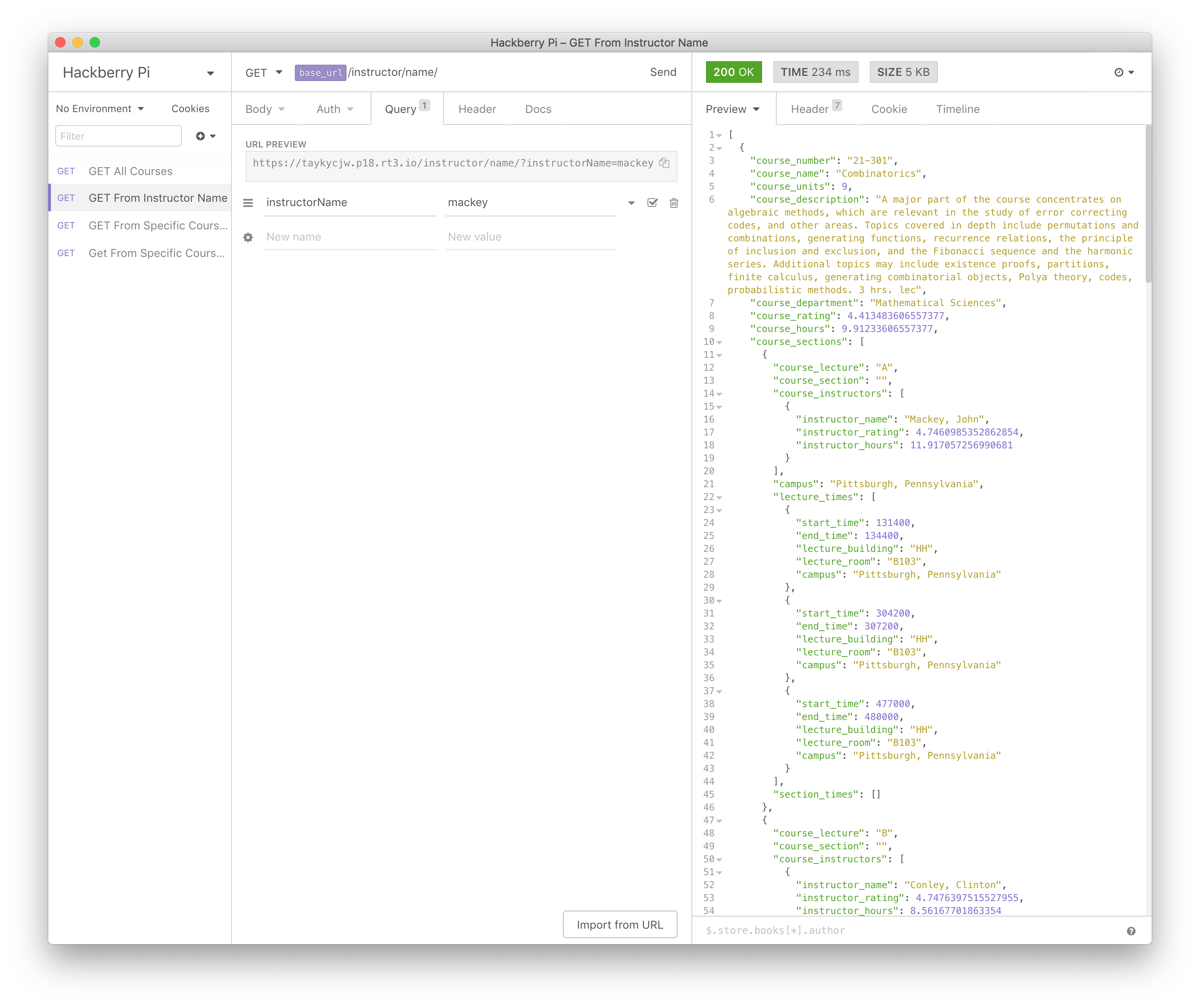
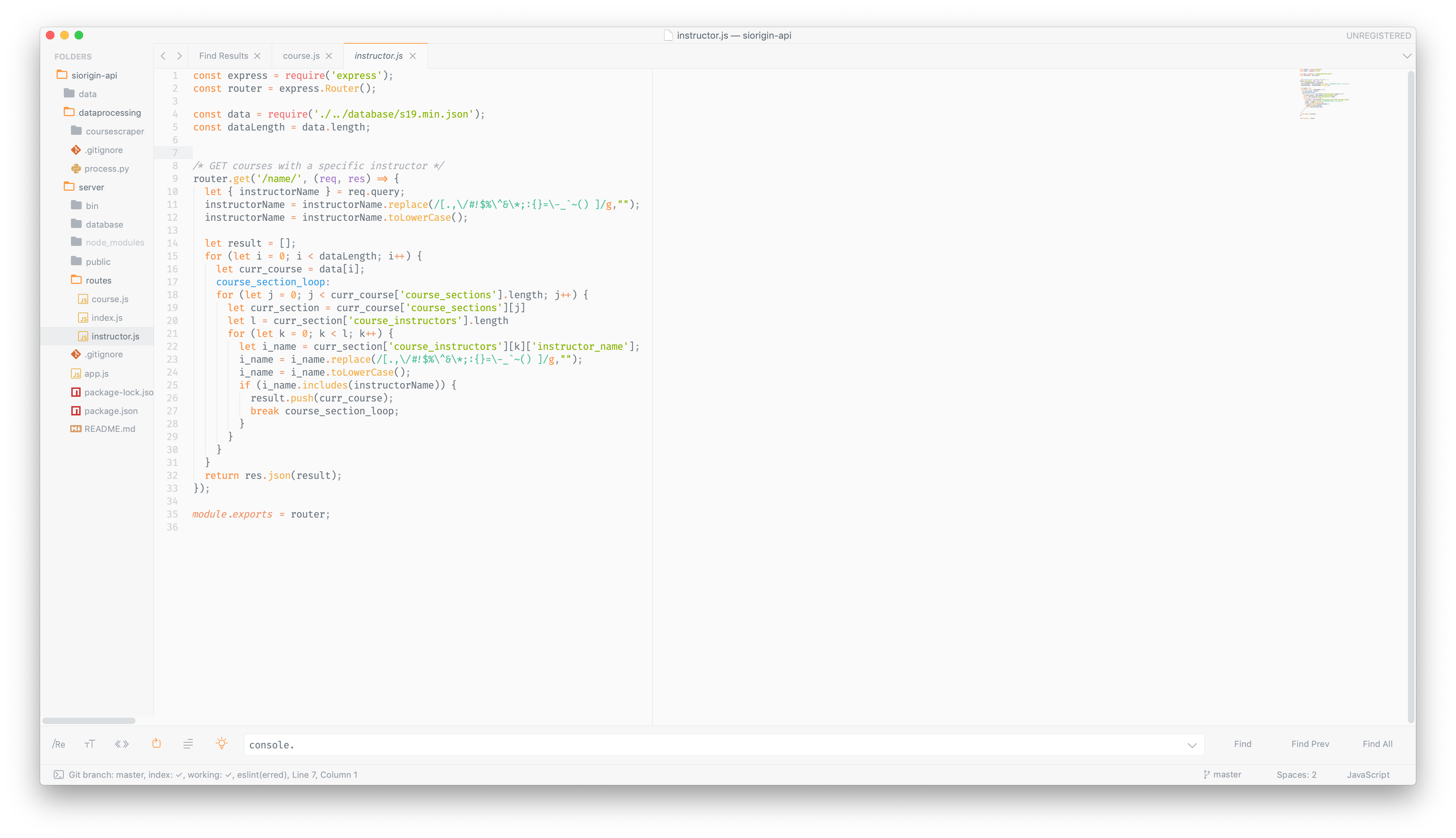
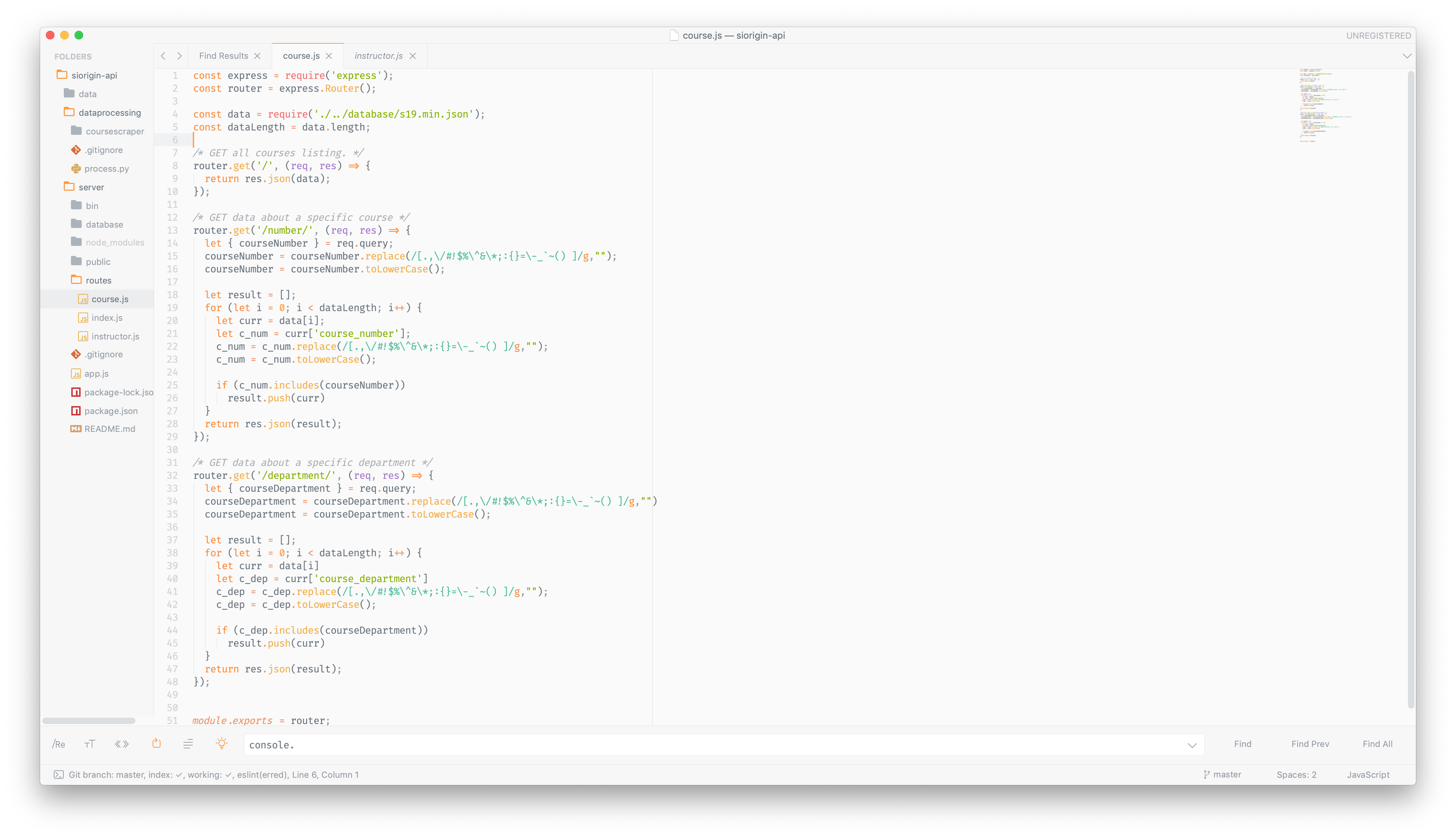
As for sending this data to the client, one approach would be to send the entire JSON. However, at 5 MB, it would take several seconds and be quite cumbersome. This is where the Raspberry Pi comes in. The Raspberry Pi functions as a low-cost and efficient API server to get information about this JSON. There are several different API calls that you can use, including getting a list of courses by course number, course department, or instructor name as well as simply getting all courses.
How I built it
I modified the existing scraper that was written in Python. I had to combine two different pieces of information -- both the FCE data and the course data. This step involved a lot of data manipulation and calculations.
The server API was written in Express. It is easily expandable and scalable.
Challenges I ran into
I ran into issues trying to calculate the FCE hours and ratings for specific courses as well as specific instructors. I found that I had a lot of redundant calculations.
Moreover, I have run into issues with associating certain sections with lecture -- for example, in the class 15-122, if you sign up for the first lecture, you can only sign up for a certain subset of the sections. The data given through CMU's API doesn't quite seem to give you this information.
What's next for SIOrigin API
The next step would be to expand the number of API queries and work on a front-end to leverage this data. Moreover, I would have to fix the bug with lecture-section classes.

Log in or sign up for Devpost to join the conversation.